Selecting Query-bag as Pseudo Relevance Feedback for Information-seeking Conversations

0

Sign in to get full access
Overview
- This paper proposes a novel approach to selecting a "query-bag" as pseudo-relevance feedback for information-seeking conversations.
- The researchers develop a system that can identify relevant queries from conversational context to improve the performance of information retrieval systems.
- The proposed method aims to enhance the quality of search results in interactive scenarios where users engage in multi-turn dialogues to find information.
Plain English Explanation
When people are searching for information, they often engage in a back-and-forth conversation with the search system, asking follow-up questions and refining their queries. This is known as an "information-seeking conversation." The paper on iterative conversational query reformulation provides more details on this interactive search process.
In this new research, the authors try to improve the search results in these information-seeking conversations. Their key insight is that the sequence of queries a user submits can provide valuable "feedback" to the search system about what information the user is actually looking for.
The researchers developed a method to automatically identify a "query-bag" - a set of relevant queries - from the conversational context. This query-bag can then be used as a form of "pseudo-relevance feedback" to refine the search and retrieve more accurate results, even without explicit user ratings or judgments.
The paper on planning and editing what you retrieve explores related ideas around using retrieval results to guide further searches.
By leveraging the conversational context in this way, the proposed approach aims to make information-seeking dialogues more effective and productive for users.
Technical Explanation
The core of the researchers' approach is a neural network model that takes the conversational history as input and outputs a "query-bag" - a set of relevant queries that can serve as pseudo-relevance feedback.
The model consists of three main components:
- A query encoder that represents each query in the conversation as a vector.
- A context encoder that aggregates the query representations into a conversational context vector.
- A query selector that identifies the most relevant queries from the context to include in the final query-bag.
The researchers train this model end-to-end using a combination of query relevance labels and reinforcement learning to optimize the query-bag selection.
In experiments on real-world conversational search datasets, the proposed query-bag approach outperformed several baseline methods for leveraging conversational context, demonstrating its effectiveness at improving information retrieval performance in interactive search scenarios.
The GenQREnsemble and IterCQR papers explore related techniques for using language models and conversational context to enhance search and retrieval.
Critical Analysis
The paper provides a compelling approach for utilizing the rich information available in conversational search logs to improve information retrieval. By automatically extracting relevant queries as pseudo-relevance feedback, the method aims to make information-seeking dialogues more effective and productive for users.
One potential limitation is that the proposed model relies on having access to labeled data for training, which may not always be available. The authors acknowledge this and suggest exploring unsupervised or few-shot learning approaches as an area for future research.
Additionally, the paper focuses on evaluating the retrieval performance of the query-bag approach, but does not directly assess the user experience or satisfaction in interactive search scenarios. Conducting user studies to understand the real-world impact on search quality and conversational flow could provide valuable insights.
The ConFLARE paper discusses some interesting techniques for improving the robustness and reliability of retrieval systems, which could be relevant extensions to the current work.
Conclusion
This paper presents a novel approach to leveraging conversational context for improving information retrieval in interactive search scenarios. By automatically extracting a "query-bag" as pseudo-relevance feedback, the proposed method aims to enhance the search quality and user experience in information-seeking dialogues.
The technical contributions, including the neural network architecture and training approach, demonstrate the potential of using conversational history to guide search and retrieval. While the paper focuses on retrieval performance, further research into the user experience and real-world deployment of such systems could yield valuable insights for the field of conversational search.
The work explores an important intersection between information retrieval, natural language processing, and interactive user interfaces - an area that is becoming increasingly relevant as users rely more on conversational AI assistants to find and explore information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Selecting Query-bag as Pseudo Relevance Feedback for Information-seeking Conversations
Xiaoqing Zhang, Xiuying Chen, Shen Gao, Shuqi Li, Xin Gao, Ji-Rong Wen, Rui Yan
Information-seeking dialogue systems are widely used in e-commerce systems, with answers that must be tailored to fit the specific settings of the online system. Given the user query, the information-seeking dialogue systems first retrieve a subset of response candidates, then further select the best response from the candidate set through re-ranking. Current methods mainly retrieve response candidates based solely on the current query, however, incorporating similar questions could introduce more diverse content, potentially refining the representation and improving the matching process. Hence, in this paper, we proposed a Query-bag based Pseudo Relevance Feedback framework (QB-PRF), which constructs a query-bag with related queries to serve as pseudo signals to guide information-seeking conversations. Concretely, we first propose a Query-bag Selection module (QBS), which utilizes contrastive learning to train the selection of synonymous queries in an unsupervised manner by leveraging the representations learned from pre-trained VAE. Secondly, we come up with a Query-bag Fusion module (QBF) that fuses synonymous queries to enhance the semantic representation of the original query through multidimensional attention computation. We verify the effectiveness of the QB-PRF framework on two competitive pretrained backbone models, including BERT and GPT-2. Experimental results on two benchmark datasets show that our framework achieves superior performance over strong baselines.
Read more4/9/2024
0
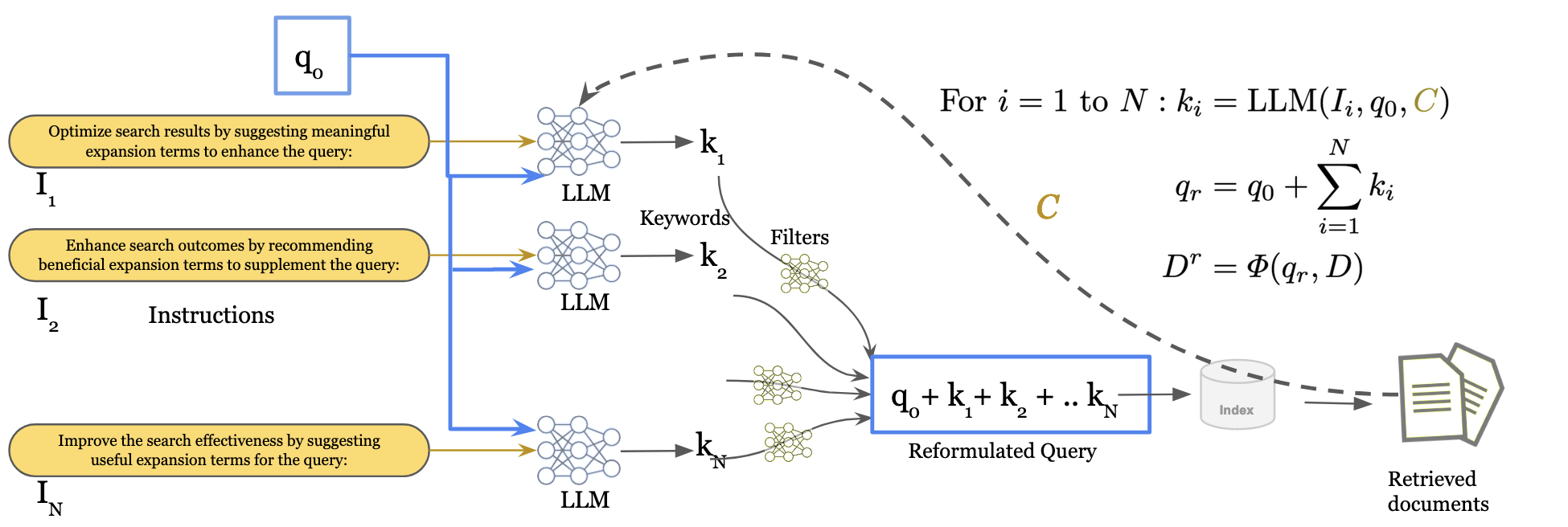
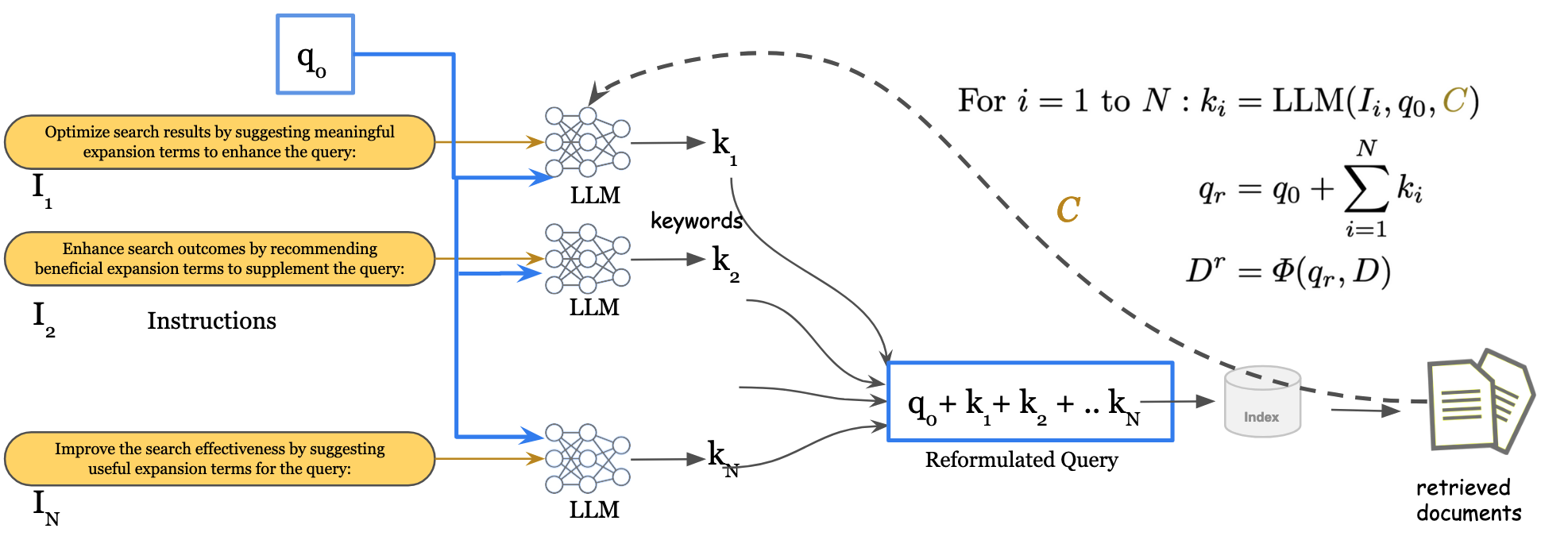
Generative Query Reformulation Using Ensemble Prompting, Document Fusion, and Relevance Feedback
Kaustubh D. Dhole, Ramraj Chandradevan, Eugene Agichtein
Query Reformulation (QR) is a set of techniques used to transform a user's original search query to a text that better aligns with the user's intent and improves their search experience. Recently, zero-shot QR has been a promising approach due to its ability to exploit knowledge inherent in large language models. Inspired by the success of ensemble prompting strategies which have benefited other tasks, we investigate if they can improve query reformulation. In this context, we propose two ensemble-based prompting techniques, GenQREnsemble and GenQRFusion which leverage paraphrases of a zero-shot instruction to generate multiple sets of keywords to improve retrieval performance ultimately. We further introduce their post-retrieval variants to incorporate relevance feedback from a variety of sources, including an oracle simulating a human user and a critic LLM. We demonstrate that an ensemble of query reformulations can improve retrieval effectiveness by up to 18% on nDCG@10 in pre-retrieval settings and 9% on post-retrieval settings on multiple benchmarks, outperforming all previously reported SOTA results. We perform subsequent analyses to investigate the effects of feedback documents, incorporate domain-specific instructions, filter reformulations, and generate fluent reformulations that might be more beneficial to human searchers. Together, the techniques and the results presented in this paper establish a new state of the art in automated query reformulation for retrieval and suggest promising directions for future research.
Read more5/29/2024
0
GenQREnsemble: Zero-Shot LLM Ensemble Prompting for Generative Query Reformulation
Kaustubh Dhole, Eugene Agichtein
Query Reformulation(QR) is a set of techniques used to transform a user's original search query to a text that better aligns with the user's intent and improves their search experience. Recently, zero-shot QR has been shown to be a promising approach due to its ability to exploit knowledge inherent in large language models. By taking inspiration from the success of ensemble prompting strategies which have benefited many tasks, we investigate if they can help improve query reformulation. In this context, we propose an ensemble based prompting technique, GenQREnsemble which leverages paraphrases of a zero-shot instruction to generate multiple sets of keywords ultimately improving retrieval performance. We further introduce its post-retrieval variant, GenQREnsembleRF to incorporate pseudo relevant feedback. On evaluations over four IR benchmarks, we find that GenQREnsemble generates better reformulations with relative nDCG@10 improvements up to 18% and MAP improvements upto 24% over the previous zero-shot state-of-art. On the MSMarco Passage Ranking task, GenQREnsembleRF shows relative gains of 5% MRR using pseudo-relevance feedback, and 9% nDCG@10 using relevant feedback documents.
Read more4/8/2024
👁️
0
User Intent Recognition and Semantic Cache Optimization-Based Query Processing Framework using CFLIS and MGR-LAU
Sakshi Mahendru
Query Processing (QP) is optimized by a Cloud-based cache by storing the frequently accessed data closer to users. Nevertheless, the lack of focus on user intention type in queries affected the efficiency of QP in prevailing works. Thus, by using a Contextual Fuzzy Linguistic Inference System (CFLIS), this work analyzed the informational, navigational, and transactional-based intents in queries for enhanced QP. Primarily, the user query is parsed using tokenization, normalization, stop word removal, stemming, and POS tagging and then expanded using the WordNet technique. After expanding the queries, to enhance query understanding and to facilitate more accurate analysis and retrieval in query processing, the named entity is recognized using Bidirectional Encoder UnispecNorm Representations from Transformers (BEUNRT). Next, for efficient QP and retrieval of query information from the semantic cache database, the data is structured using Epanechnikov Kernel-Ordering Points To Identify the Clustering Structure (EK-OPTICS). The features are extracted from the structured data. Now, sentence type is identified and intent keywords are extracted from the parsed query. Next, the extracted features, detected intents and structured data are inputted to the Multi-head Gated Recurrent Learnable Attention Unit (MGR-LAU), which processes the query based on a semantic cache database (stores previously interpreted queries to expedite effective future searches). Moreover, the query is processed with a minimum latency of 12856ms. Lastly, the Semantic Similarity (SS) is analyzed between the retrieved query and the inputted user query, which continues until the similarity reaches 0.9 and above. Thus, the proposed work surpassed the previous methodologies.
Read more6/10/2024