Planning and Editing What You Retrieve for Enhanced Tool Learning

0
Sign in to get full access
Overview
- This paper explores how planning and editing the information retrieved by machine learning models can enhance their performance on tasks like tool learning.
- The researchers investigate different strategies for curating the data used to train these models, with the goal of improving their ability to learn and apply tool-related knowledge.
- The paper presents experiments that compare the effectiveness of various data selection and editing approaches, providing insights into how to optimize model training for tool learning applications.
Plain English Explanation
The paper examines ways to improve the learning capabilities of machine learning models, particularly when it comes to understanding and using tools. The key idea is that the data used to train these models can significantly impact their performance.
Imagine you're trying to teach a child how to use a hammer. If you only show them videos of people using the hammer incorrectly, they'll have a hard time learning the proper techniques. Similarly, machine learning models trained on low-quality or irrelevant data may struggle to learn the right way to interact with tools.
The researchers tested different approaches to curating the training data, such as carefully selecting relevant examples and making edits to improve their quality. By planning and editing the information the models are exposed to during training, the researchers found they could enhance the models' ability to learn and apply tool-related knowledge effectively.
This is an important area of research, as developing AI systems that can understand and manipulate tools is crucial for a wide range of applications, from household robots to industrial automation. The insights from this paper could help unlock more capable and versatile machine learning models in the future.
Technical Explanation
The paper explores strategies for planning and editing the data used to train machine learning models for tool learning tasks. The researchers conducted experiments comparing the performance of models trained on different types of curated data.
The first experiment looked at the impact of data selection, where the researchers hand-picked a subset of the available training data they deemed most relevant and high-quality. They found that models trained on this carefully selected data outperformed those trained on the full, unfiltered dataset.
The second experiment focused on data editing, where the researchers made targeted modifications to the training examples to improve their pedagogical value. This included tasks like removing irrelevant background elements, adjusting object poses, and annotating key tool-related information. Models trained on the edited data demonstrated superior tool learning capabilities compared to those trained on the unedited examples.
The researchers also experimented with combining data selection and editing, finding that this hybrid approach yielded the best overall results. By carefully planning which data to use and then refining that data, the models were able to learn more effectively about tools and how to interact with them.
The paper provides valuable insights into the importance of data curation for machine learning, particularly in domains like tool learning where the training data can have a significant impact on model performance. The findings suggest that investing effort into thoughtfully selecting and editing training examples can pay dividends in terms of developing more capable and versatile AI systems.
Critical Analysis
The paper presents a thorough and well-designed set of experiments to explore the impact of data curation on tool learning models. The researchers make a compelling case for the importance of carefully selecting and editing the training data, providing empirical evidence to support their claims.
That said, the paper does acknowledge some limitations to their work. For instance, the experiments were conducted on a relatively small dataset, and the researchers note that scaling up to larger and more diverse datasets may present additional challenges. Additionally, the paper does not delve into the specific criteria or guidelines used for data selection and editing, which could be an area for further exploration.
Another potential area for further research is the generalizability of the findings. While the paper demonstrates the benefits of data curation for tool learning tasks, it would be interesting to see if similar strategies can be applied to other domains or learning objectives within machine learning.
Overall, the paper makes a valuable contribution to the understanding of how data quality and curation can influence the performance of machine learning models. The insights provided could inform the development of more effective and robust AI systems, particularly in applications where tool-related knowledge is crucial.
Conclusion
This paper highlights the importance of carefully planning and editing the data used to train machine learning models, especially when it comes to tasks involving tools and physical interactions. The researchers' experiments demonstrate that by thoughtfully selecting and refining the training examples, models can significantly enhance their ability to learn and apply tool-related knowledge.
The findings from this work have important implications for the development of more capable and versatile AI systems, which will be crucial for a wide range of applications, from household robots to industrial automation. By investing effort into data curation, researchers and engineers can unlock the full potential of machine learning, leading to more intelligent and capable systems that can seamlessly interact with and manipulate the physical world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Planning and Editing What You Retrieve for Enhanced Tool Learning
Tenghao Huang, Dongwon Jung, Muhao Chen
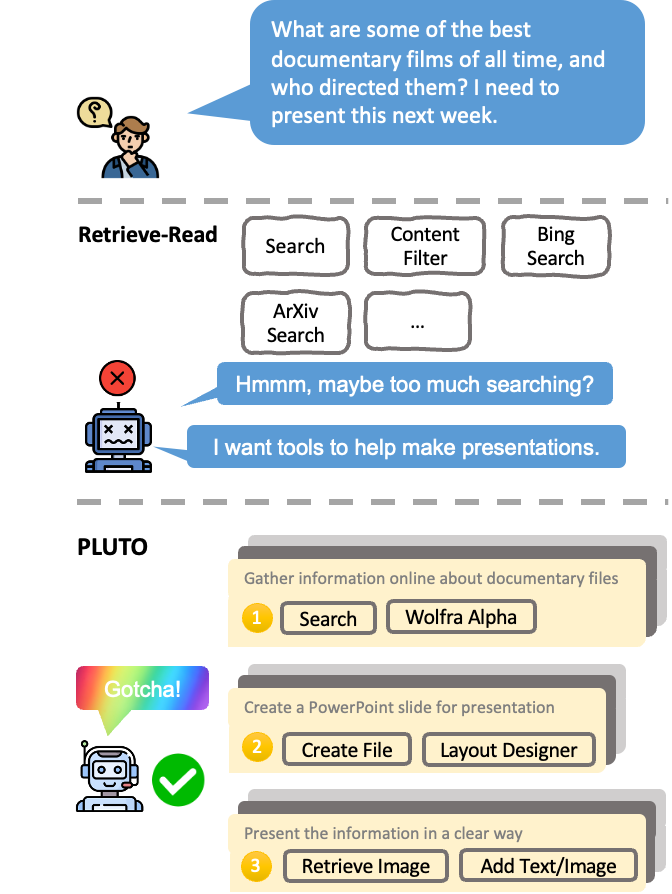
Recent advancements in integrating external tools with Large Language Models (LLMs) have opened new frontiers, with applications in mathematical reasoning, code generators, and smart assistants. However, existing methods, relying on simple one-time retrieval strategies, fall short on effectively and accurately shortlisting relevant tools. This paper introduces a novel PLUTO (Planning, Learning, and Understanding for TOols) approach, encompassing `Plan-and-Retrieve (P&R)` and `Edit-and-Ground (E&G)` paradigms. The P&R paradigm consists of a neural retrieval module for shortlisting relevant tools and an LLM-based query planner that decomposes complex queries into actionable tasks, enhancing the effectiveness of tool utilization. The E&G paradigm utilizes LLMs to enrich tool descriptions based on user scenarios, bridging the gap between user queries and tool functionalities. Experiment results demonstrate that these paradigms significantly improve the recall and NDCG in tool retrieval tasks, significantly surpassing current state-of-the-art models.
Read more4/5/2024
0
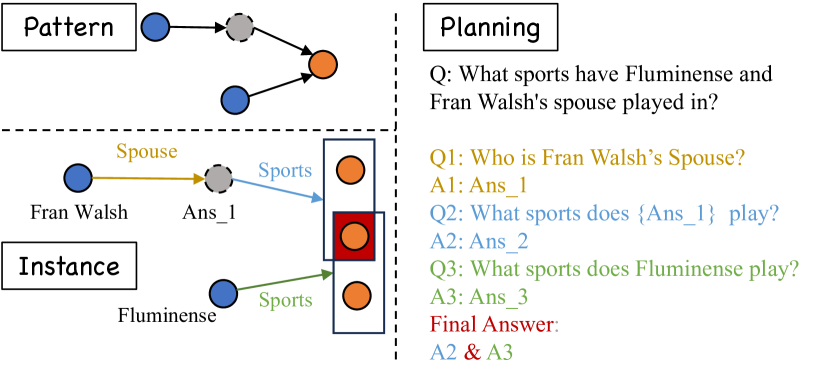
Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs
Junjie Wang, Mingyang Chen, Binbin Hu, Dan Yang, Ziqi Liu, Yue Shen, Peng Wei, Zhiqiang Zhang, Jinjie Gu, Jun Zhou, Jeff Z. Pan, Wen Zhang, Huajun Chen
Improving the performance of large language models (LLMs) in complex question-answering (QA) scenarios has always been a research focal point. Recent studies have attempted to enhance LLMs' performance by combining step-wise planning with external retrieval. While effective for advanced models like GPT-3.5, smaller LLMs face challenges in decomposing complex questions, necessitating supervised fine-tuning. Previous work has relied on manual annotation and knowledge distillation from teacher LLMs, which are time-consuming and not accurate enough. In this paper, we introduce a novel framework for enhancing LLMs' planning capabilities by using planning data derived from knowledge graphs (KGs). LLMs fine-tuned with this data have improved planning capabilities, better equipping them to handle complex QA tasks that involve retrieval. Evaluations on multiple datasets, including our newly proposed benchmark, highlight the effectiveness of our framework and the benefits of KG-derived planning data.
Read more6/21/2024
0
COLT: Towards Completeness-Oriented Tool Retrieval for Large Language Models
Changle Qu, Sunhao Dai, Xiaochi Wei, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Jun Xu, Ji-Rong Wen
Recently, integrating external tools with Large Language Models (LLMs) has gained significant attention as an effective strategy to mitigate the limitations inherent in their pre-training data. However, real-world systems often incorporate a wide array of tools, making it impractical to input all tools into LLMs due to length limitations and latency constraints. Therefore, to fully exploit the potential of tool-augmented LLMs, it is crucial to develop an effective tool retrieval system. Existing tool retrieval methods primarily focus on semantic matching between user queries and tool descriptions, frequently leading to the retrieval of redundant, similar tools. Consequently, these methods fail to provide a complete set of diverse tools necessary for addressing the multifaceted problems encountered by LLMs. In this paper, we propose a novel modelagnostic COllaborative Learning-based Tool Retrieval approach, COLT, which captures not only the semantic similarities between user queries and tool descriptions but also takes into account the collaborative information of tools. Specifically, we first fine-tune the PLM-based retrieval models to capture the semantic relationships between queries and tools in the semantic learning stage. Subsequently, we construct three bipartite graphs among queries, scenes, and tools and introduce a dual-view graph collaborative learning framework to capture the intricate collaborative relationships among tools during the collaborative learning stage. Extensive experiments on both the open benchmark and the newly introduced ToolLens dataset show that COLT achieves superior performance. Notably, the performance of BERT-mini (11M) with our proposed model framework outperforms BERT-large (340M), which has 30 times more parameters. Furthermore, we will release ToolLens publicly to facilitate future research on tool retrieval.
Read more7/30/2024
➖
0
Re-Invoke: Tool Invocation Rewriting for Zero-Shot Tool Retrieval
Yanfei Chen, Jinsung Yoon, Devendra Singh Sachan, Qingze Wang, Vincent Cohen-Addad, Mohammadhossein Bateni, Chen-Yu Lee, Tomas Pfister
Recent advances in large language models (LLMs) have enabled autonomous agents with complex reasoning and task-fulfillment capabilities using a wide range of tools. However, effectively identifying the most relevant tools for a given task becomes a key bottleneck as the toolset size grows, hindering reliable tool utilization. To address this, we introduce Re-Invoke, an unsupervised tool retrieval method designed to scale effectively to large toolsets without training. Specifically, we first generate a diverse set of synthetic queries that comprehensively cover different aspects of the query space associated with each tool document during the tool indexing phase. Second, we leverage LLM's query understanding capabilities to extract key tool-related context and underlying intents from user queries during the inference phase. Finally, we employ a novel multi-view similarity ranking strategy based on intents to pinpoint the most relevant tools for each query. Our evaluation demonstrates that Re-Invoke significantly outperforms state-of-the-art alternatives in both single-tool and multi-tool scenarios, all within a fully unsupervised setting. Notably, on the ToolE datasets, we achieve a 20% relative improvement in nDCG@5 for single-tool retrieval and a 39% improvement for multi-tool retrieval.
Read more9/24/2024