Selective Knowledge Sharing for Personalized Federated Learning Under Capacity Heterogeneity
2405.20589
0
0

Abstract
Federated Learning (FL) stands to gain significant advantages from collaboratively training capacity-heterogeneous models, enabling the utilization of private data and computing power from low-capacity devices. However, the focus on personalizing capacity-heterogeneous models based on client-specific data has been limited, resulting in suboptimal local model utility, particularly for low-capacity clients. The heterogeneity in both data and device capacity poses two key challenges for model personalization: 1) accurately retaining necessary knowledge embedded within reduced submodels for each client, and 2) effectively sharing knowledge through aggregating size-varying parameters. To this end, we introduce Pa3dFL, a novel framework designed to enhance local model performance by decoupling and selectively sharing knowledge among capacity-heterogeneous models. First, we decompose each layer of the model into general and personal parameters. Then, we maintain uniform sizes for the general parameters across clients and aggregate them through direct averaging. Subsequently, we employ a hyper-network to generate size-varying personal parameters for clients using learnable embeddings. Finally, we facilitate the implicit aggregation of personal parameters by aggregating client embeddings through a self-attention module. We conducted extensive experiments on three datasets to evaluate the effectiveness of Pa3dFL. Our findings indicate that Pa3dFL consistently outperforms baseline methods across various heterogeneity settings. Moreover, Pa3dFL demonstrates competitive communication and computation efficiency compared to baseline approaches, highlighting its practicality and adaptability in adverse system conditions.
Create account to get full access
Overview
- The paper proposes a personalized federated learning (PFL) framework that addresses the challenge of capacity heterogeneity among clients.
- It introduces a selective knowledge sharing (SKS) mechanism to enable efficient and personalized model updates.
- The framework aims to improve the performance and convergence of PFL under resource-constrained settings.
Plain English Explanation
In today's world, many machine learning models are trained on data from various sources, often called clients. This approach, known as federated learning, allows for the model to be updated without sharing sensitive client data. However, the clients may have different computational resources, which can create challenges.
The researchers in this paper developed a new federated learning framework that addresses this issue of "capacity heterogeneity." Their approach, called "Selective Knowledge Sharing" (SKS), allows clients to selectively share the most relevant parts of their local model updates with the central server. This helps to improve the overall performance and speed of the federated learning process, even when some clients have limited resources.
The key idea behind SKS is to enable clients to focus on updating the most important parts of the model, rather than sharing everything. This selective sharing helps to overcome the constraints of weaker clients and leads to better personalized models for each client. The paper demonstrates the effectiveness of this approach through experiments, showing that it can outperform traditional federated learning methods in terms of accuracy and convergence speed.
Technical Explanation
The paper proposes a Personalized Federated Learning (PFL) framework that addresses the challenge of capacity heterogeneity among clients. It introduces a Selective Knowledge Sharing (SKS) mechanism to enable efficient and personalized model updates.
The key elements of the framework are:
- Personalization Module: Each client maintains a personalization module that learns client-specific model updates, in addition to the shared global model.
- Selective Knowledge Sharing: Clients selectively share the most relevant parts of their local model updates with the central server, based on an importance score. This helps to overcome the constraints of weaker clients.
- Adaptive Aggregation: The central server adaptively aggregates the received updates, giving more weight to updates from clients with higher importance scores.
The authors conduct extensive experiments on benchmark datasets, comparing their SKS-PFL framework with state-of-the-art PFL methods, such as FedP3, MPFL, Per-FedAvg, and MH-PFLID. The results show that SKS-PFL outperforms these methods in terms of both accuracy and convergence speed, particularly under resource-constrained settings.
Critical Analysis
The paper presents a promising approach to address the challenge of capacity heterogeneity in federated learning. The selective knowledge sharing mechanism is a novel contribution that allows clients to focus on updating the most important parts of the model, rather than sharing everything.
One potential limitation of the proposed framework is the assumption that clients can accurately assess the importance of their local model updates. In practice, this may require additional computational overhead or specialized hardware, which could limit the applicability of the approach in certain scenarios.
Additionally, the paper does not explore the potential privacy implications of the selective sharing mechanism. It would be valuable to investigate whether the proposed approach introduces any new privacy risks or vulnerabilities, especially in the context of sensitive client data.
Further research could also explore the integration of the SKS-PFL framework with other personalized federated learning approaches, such as PFedAFM, to create even more robust and versatile personalized federated learning solutions.
Conclusion
The "Selective Knowledge Sharing for Personalized Federated Learning Under Capacity Heterogeneity" paper presents a novel approach to address the challenge of capacity heterogeneity in federated learning. By introducing a selective knowledge sharing mechanism, the proposed framework enables efficient and personalized model updates, even under resource-constrained settings.
The experimental results demonstrate the effectiveness of the SKS-PFL framework, showcasing its ability to outperform state-of-the-art personalized federated learning methods in terms of both accuracy and convergence speed. This work contributes to the ongoing efforts to develop robust and scalable federated learning solutions that can adapt to the diverse computational capabilities of clients.
As machine learning continues to be applied in an increasing number of real-world scenarios, frameworks like SKS-PFL will become increasingly important in ensuring the successful deployment of federated learning systems that can cater to the needs of all participants, regardless of their available resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

FedP3: Federated Personalized and Privacy-friendly Network Pruning under Model Heterogeneity
Kai Yi, Nidham Gazagnadou, Peter Richt'arik, Lingjuan Lyu
0
0
The interest in federated learning has surged in recent research due to its unique ability to train a global model using privacy-secured information held locally on each client. This paper pays particular attention to the issue of client-side model heterogeneity, a pervasive challenge in the practical implementation of FL that escalates its complexity. Assuming a scenario where each client possesses varied memory storage, processing capabilities and network bandwidth - a phenomenon referred to as system heterogeneity - there is a pressing need to customize a unique model for each client. In response to this, we present an effective and adaptable federated framework FedP3, representing Federated Personalized and Privacy-friendly network Pruning, tailored for model heterogeneity scenarios. Our proposed methodology can incorporate and adapt well-established techniques to its specific instances. We offer a theoretical interpretation of FedP3 and its locally differential-private variant, DP-FedP3, and theoretically validate their efficiencies.
4/16/2024
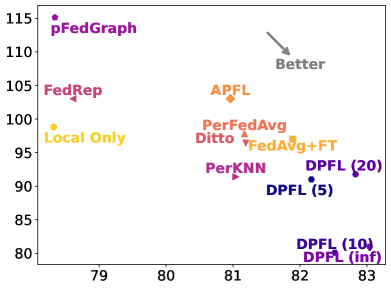
Decentralized Personalized Federated Learning
Salma Kharrat, Marco Canini, Samuel Horvath
0
0
This work tackles the challenges of data heterogeneity and communication limitations in decentralized federated learning. We focus on creating a collaboration graph that guides each client in selecting suitable collaborators for training personalized models that leverage their local data effectively. Our approach addresses these issues through a novel, communication-efficient strategy that enhances resource efficiency. Unlike traditional methods, our formulation identifies collaborators at a granular level by considering combinatorial relations of clients, enhancing personalization while minimizing communication overhead. We achieve this through a bi-level optimization framework that employs a constrained greedy algorithm, resulting in a resource-efficient collaboration graph for personalized learning. Extensive evaluation against various baselines across diverse datasets demonstrates the superiority of our method, named DPFL. DPFL consistently outperforms other approaches, showcasing its effectiveness in handling real-world data heterogeneity, minimizing communication overhead, enhancing resource efficiency, and building personalized models in decentralized federated learning scenarios.
6/11/2024
📊
Multi-level Personalized Federated Learning on Heterogeneous and Long-Tailed Data
Rongyu Zhang, Yun Chen, Chenrui Wu, Fangxin Wang, Bo Li
0
0
Federated learning (FL) offers a privacy-centric distributed learning framework, enabling model training on individual clients and central aggregation without necessitating data exchange. Nonetheless, FL implementations often suffer from non-i.i.d. and long-tailed class distributions across mobile applications, e.g., autonomous vehicles, which leads models to overfitting as local training may converge to sub-optimal. In our study, we explore the impact of data heterogeneity on model bias and introduce an innovative personalized FL framework, Multi-level Personalized Federated Learning (MuPFL), which leverages the hierarchical architecture of FL to fully harness computational resources at various levels. This framework integrates three pivotal modules: Biased Activation Value Dropout (BAVD) to mitigate overfitting and accelerate training; Adaptive Cluster-based Model Update (ACMU) to refine local models ensuring coherent global aggregation; and Prior Knowledge-assisted Classifier Fine-tuning (PKCF) to bolster classification and personalize models in accord with skewed local data with shared knowledge. Extensive experiments on diverse real-world datasets for image classification and semantic segmentation validate that MuPFL consistently outperforms state-of-the-art baselines, even under extreme non-i.i.d. and long-tail conditions, which enhances accuracy by as much as 7.39% and accelerates training by up to 80% at most, marking significant advancements in both efficiency and effectiveness.
5/13/2024

Personalized federated learning based on feature fusion
Wolong Xing, Zhenkui Shi, Hongyan Peng, Xiantao Hu, Xianxian Li
0
0
Federated learning enables distributed clients to collaborate on training while storing their data locally to protect client privacy. However, due to the heterogeneity of data, models, and devices, the final global model may need to perform better for tasks on each client. Communication bottlenecks, data heterogeneity, and model heterogeneity have been common challenges in federated learning. In this work, we considered a label distribution skew problem, a type of data heterogeneity easily overlooked. In the context of classification, we propose a personalized federated learning approach called pFedPM. In our process, we replace traditional gradient uploading with feature uploading, which helps reduce communication costs and allows for heterogeneous client models. These feature representations play a role in preserving privacy to some extent. We use a hyperparameter $a$ to mix local and global features, which enables us to control the degree of personalization. We also introduced a relation network as an additional decision layer, which provides a non-linear learnable classifier to predict labels. Experimental results show that, with an appropriate setting of $a$, our scheme outperforms several recent FL methods on MNIST, FEMNIST, and CRIFAR10 datasets and achieves fewer communications.
6/26/2024