Selective Prompting Tuning for Personalized Conversations with LLMs

0
Sign in to get full access
Overview
• This paper introduces a new technique called "Selective Prompting Tuning" (SPT) for personalizing conversations with large language models (LLMs). • SPT allows users to selectively tune the prompts used to engage an LLM, enabling more personalized and contextual responses. • This builds on recent advancements in prompt tuning, such as Soft Prompt Tuning, Passage-Specific Prompt Tuning, and Plug-and-Play Prompts.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can engage in human-like conversations. However, their responses can sometimes feel generic or impersonal. The researchers in this paper have developed a new technique called "Selective Prompting Tuning" (SPT) to make LLM conversations more personalized and contextual.
The key idea behind SPT is that users can selectively choose which parts of the prompts that are used to engage the LLM they want to tune or customize. This allows them to shape the LLM's responses to better match their individual preferences, interests, and communication styles.
For example, a user might want to tune the prompts related to their knowledge of a specific topic, their tone of voice, or their sense of humor. SPT gives them the flexibility to do this, leading to more engaging and tailored conversations with the LLM.
By building on recent advancements in prompt tuning, such as Soft Prompt Tuning, Passage-Specific Prompt Tuning, and Plug-and-Play Prompts, SPT represents an important step forward in making LLM-based conversations more personalized and natural.
Technical Explanation
The researchers propose a Selective Prompting Tuning (SPT) approach to enable personalized conversations with large language models (LLMs). SPT allows users to selectively tune the prompts used to engage the LLM, focusing on specific aspects that are relevant to their individual preferences and communication styles.
The key technical components of SPT include:
- Prompt Decomposition: The researchers decompose the prompts used to engage the LLM into different semantic and stylistic components, such as knowledge, tone, and personality.
- Selective Tuning: Users can then selectively tune these different components of the prompts, adjusting them to better match their individual needs and preferences.
- Prompt Recombination: The selectively tuned prompt components are then recombined to generate the final prompt that is used to engage the LLM, leading to more personalized responses.
The researchers evaluate SPT on a variety of conversational tasks, demonstrating its ability to improve the relevance, coherence, and engagement of LLM-based dialogues compared to standard prompt tuning approaches. They also show how SPT can be used to fine-tune LLMs for specific users or user groups, making the conversations more tailored and meaningful.
Critical Analysis
The Selective Prompting Tuning (SPT) approach presented in this paper represents an important step forward in making large language model (LLM) conversations more personalized and engaging. By allowing users to selectively tune the prompts used to engage the LLM, the researchers have developed a technique that can lead to more relevant, coherent, and contextual responses.
One potential limitation of the approach is the complexity of the prompt decomposition and recombination process. Decomposing prompts into semantic and stylistic components, and then selectively tuning and recombining them, could be computationally intensive and may require significant engineering effort.
Additionally, the researchers note that the effectiveness of SPT may depend on the specific LLM being used and the quality of the initial prompts. If the base prompts are not well-designed or do not capture the desired semantic and stylistic characteristics, the selective tuning process may not be as effective.
Further research could explore ways to streamline the prompt decomposition and tuning process, as well as investigate the generalizability of SPT across different LLMs and domains. Incorporating user feedback and preferences directly into the prompt tuning process could also be a valuable area of exploration.
Overall, the Selective Prompting Tuning approach presented in this paper represents an exciting development in the field of personalized language model interactions, and the researchers have demonstrated its potential to enhance the quality and engagement of LLM-based conversations.
Conclusion
The Selective Prompting Tuning (SPT) technique introduced in this paper is a significant advancement in making large language model (LLM) conversations more personalized and engaging. By allowing users to selectively tune the prompts used to engage the LLM, SPT enables more relevant, coherent, and contextual responses that better match individual preferences and communication styles.
This work builds on recent progress in prompt tuning, such as Soft Prompt Tuning, Passage-Specific Prompt Tuning, and Plug-and-Play Prompts, and represents an important step towards more personalized and natural interactions with LLMs.
While the technical implementation of SPT may present some challenges, the researchers have demonstrated its potential to enhance the quality and engagement of LLM-based dialogues. Further research in this area could lead to even more powerful and user-friendly techniques for customizing language model interactions to individual needs and preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Selective Prompting Tuning for Personalized Conversations with LLMs
Qiushi Huang, Xubo Liu, Tom Ko, Bo Wu, Wenwu Wang, Yu Zhang, Lilian Tang
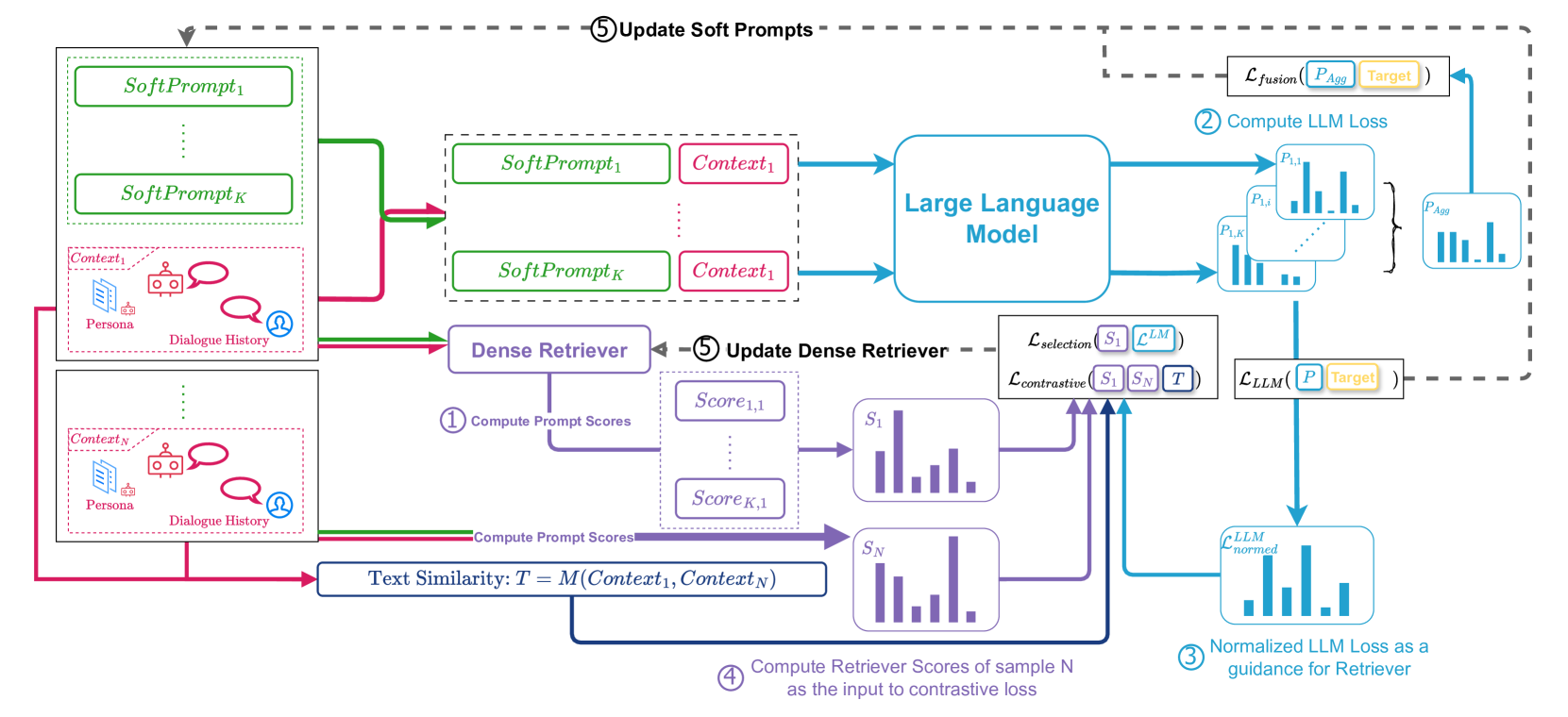
In conversational AI, personalizing dialogues with persona profiles and contextual understanding is essential. Despite large language models' (LLMs) improved response coherence, effective persona integration remains a challenge. In this work, we first study two common approaches for personalizing LLMs: textual prompting and direct fine-tuning. We observed that textual prompting often struggles to yield responses that are similar to the ground truths in datasets, while direct fine-tuning tends to produce repetitive or overly generic replies. To alleviate those issues, we propose textbf{S}elective textbf{P}rompt textbf{T}uning (SPT), which softly prompts LLMs for personalized conversations in a selective way. Concretely, SPT initializes a set of soft prompts and uses a trainable dense retriever to adaptively select suitable soft prompts for LLMs according to different input contexts, where the prompt retriever is dynamically updated through feedback from the LLMs. Additionally, we propose context-prompt contrastive learning and prompt fusion learning to encourage the SPT to enhance the diversity of personalized conversations. Experiments on the CONVAI2 dataset demonstrate that SPT significantly enhances response diversity by up to 90%, along with improvements in other critical performance indicators. Those results highlight the efficacy of SPT in fostering engaging and personalized dialogue generation. The SPT model code (https://github.com/hqsiswiliam/SPT) is publicly available for further exploration.
Read more6/27/2024
0
Passage-specific Prompt Tuning for Passage Reranking in Question Answering with Large Language Models
Xuyang Wu, Zhiyuan Peng, Krishna Sravanthi Rajanala Sai, Hsin-Tai Wu, Yi Fang
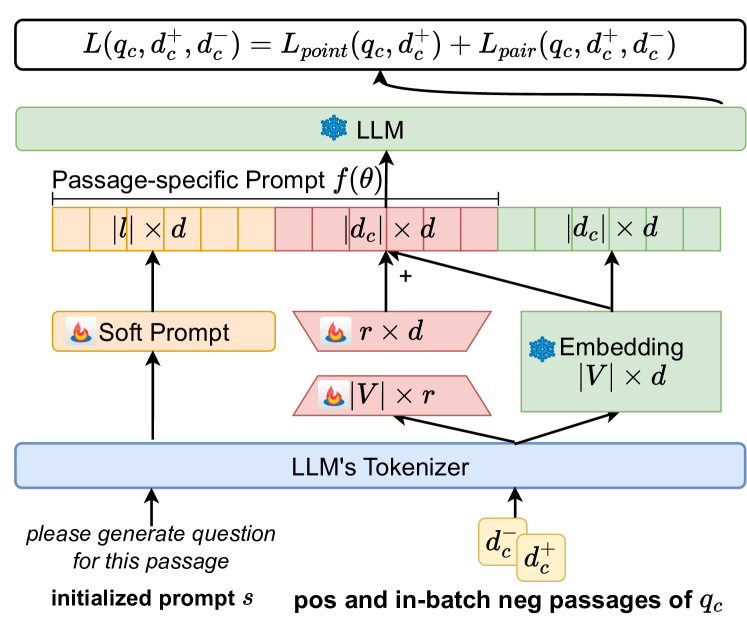
Effective passage retrieval and reranking methods have been widely utilized to identify suitable candidates in open-domain question answering tasks, recent studies have resorted to LLMs for reranking the retrieved passages by the log-likelihood of the question conditioned on each passage. Although these methods have demonstrated promising results, the performance is notably sensitive to the human-written prompt (or hard prompt), and fine-tuning LLMs can be computationally intensive and time-consuming. Furthermore, this approach limits the leverage of question-passage relevance pairs and passage-specific knowledge to enhance the ranking capabilities of LLMs. In this paper, we propose passage-specific prompt tuning for reranking in open-domain question answering (PSPT): a parameter-efficient method that fine-tunes learnable passage-specific soft prompts, incorporating passage-specific knowledge from a limited set of question-passage relevance pairs. The method involves ranking retrieved passages based on the log-likelihood of the model generating the question conditioned on each passage and the learned soft prompt. We conducted extensive experiments utilizing the Llama-2-chat-7B model across three publicly available open-domain question answering datasets and the results demonstrate the effectiveness of the proposed approach.
Read more6/24/2024
💬
0
Soft Prompt Tuning for Augmenting Dense Retrieval with Large Language Models
Zhiyuan Peng, Xuyang Wu, Qifan Wang, Yi Fang
Dense retrieval (DR) converts queries and documents into dense embeddings and measures the similarity between queries and documents in vector space. One of the challenges in DR is the lack of domain-specific training data. While DR models can learn from large-scale public datasets like MS MARCO through transfer learning, evidence shows that not all DR models and domains can benefit from transfer learning equally. Recently, some researchers have resorted to large language models (LLMs) to improve the zero-shot and few-shot DR models. However, the hard prompts or human-written prompts utilized in these works cannot guarantee the good quality of generated weak queries. To tackle this, we propose soft prompt tuning for augmenting DR (SPTAR): For each task, we leverage soft prompt-tuning to optimize a task-specific soft prompt on limited ground truth data and then prompt the LLMs to tag unlabeled documents with weak queries, yielding enough weak document-query pairs to train task-specific dense retrievers. We design a filter to select high-quality example document-query pairs in the prompt to further improve the quality of weak tagged queries. To the best of our knowledge, there is no prior work utilizing soft prompt tuning to augment DR models. The experiments demonstrate that SPTAR outperforms the unsupervised baselines BM25 and the recently proposed LLMs-based augmentation method for DR.
Read more6/18/2024
🤔
0
Revisiting the Power of Prompt for Visual Tuning
Yuzhu Wang, Lechao Cheng, Chaowei Fang, Dingwen Zhang, Manni Duan, Meng Wang
Visual prompt tuning (VPT) is a promising solution incorporating learnable prompt tokens to customize pre-trained models for downstream tasks. However, VPT and its variants often encounter challenges like prompt initialization, prompt length, and subpar performance in self-supervised pretraining, hindering successful contextual adaptation. This study commences by exploring the correlation evolvement between prompts and patch tokens during proficient training. Inspired by the observation that the prompt tokens tend to share high mutual information with patch tokens, we propose initializing prompts with downstream token prototypes. The strategic initialization, a stand-in for the previous initialization, substantially improves performance in fine-tuning. To refine further, we optimize token construction with a streamlined pipeline that maintains excellent performance with almost no increase in computational expenses compared to VPT. Exhaustive experiments show our proposed approach outperforms existing methods by a remarkable margin. For instance, it surpasses full fine-tuning in 19 out of 24 tasks, using less than 0.4% of learnable parameters on the FGVC and VTAB-1K benchmarks. Notably, our method significantly advances the adaptation for self-supervised pretraining, achieving impressive task performance gains of at least 10% to 30%. Besides, the experimental results demonstrate the proposed SPT is robust to prompt lengths and scales well with model capacity and training data size. We finally provide an insightful exploration into the amount of target data facilitating the adaptation of pre-trained models to downstream tasks. The code is available at https://github.com/WangYZ1608/Self-Prompt-Tuning.
Read more5/28/2024