SelectTTS: Synthesizing Anyone's Voice via Discrete Unit-Based Frame Selection

0

Sign in to get full access
Overview
- The paper proposes a new text-to-speech (TTS) model called SelectTTS that can synthesize speech in anyone's voice.
- It uses a discrete unit-based frame selection approach and self-supervised learning to achieve this.
- The model aims to be more scalable and flexible than existing multi-speaker TTS systems.
Plain English Explanation
The paper introduces a new text-to-speech (TTS) system called SelectTTS that can generate speech in anyone's voice. Instead of trying to model every speaker's voice directly, SelectTTS takes a different approach.
The key idea is to build a large database of short speech segments or "units" from many different speakers. When generating new speech, the model selects the appropriate units from this database and strings them together to form the desired voice. This discrete unit-based frame selection allows the model to be more flexible and scale to many speakers, compared to previous multi-speaker TTS systems.
The researchers also use self-supervised learning techniques to train the model, which means they can leverage large amounts of unlabeled speech data to help the model learn good representations of different voices. This makes the training process more efficient and effective.
Overall, the goal of SelectTTS is to provide a scalable and versatile TTS system that can synthesize speech in any target voice, without requiring extensive training data or complex modeling for each individual speaker. This could have applications in areas like personalized digital assistants, text-to-speech for accessibility, or audio dubbing for movies and games.
Technical Explanation
The key technical aspects of the SelectTTS model are:
-
Discrete Unit-Based Frame Selection: Instead of directly modeling each speaker's voice, the model maintains a large database of short speech "units" from many different speakers. When generating new speech, it selects the appropriate units from this database and concatenates them to form the desired voice. This discrete unit-based approach allows the model to be more flexible and scale to many speakers.
-
Self-Supervised Learning: The researchers use self-supervised learning techniques to train the model, which means they can leverage large amounts of unlabeled speech data to help the model learn good representations of different voices. This makes the training process more efficient and effective compared to traditional supervised learning methods that require extensive labeled data.
-
Speaker Encoder and Unit Retrieval: The model has two main components - a speaker encoder that maps a target speaker's voice characteristics into a compact embedding, and a unit retrieval module that selects the appropriate speech units from the database based on this embedding and the input text.
-
Evaluation: The researchers evaluate SelectTTS on several benchmark text-to-speech datasets, comparing it to state-of-the-art multi-speaker TTS models. They find that SelectTTS achieves comparable or better performance in terms of speech quality and speaker similarity.
Critical Analysis
The paper presents a compelling approach to text-to-speech synthesis that aims to be more scalable and flexible than existing multi-speaker TTS systems. The key strengths of the SelectTTS model are its discrete unit-based frame selection and use of self-supervised learning, which allow it to handle a wide range of speakers without the need for extensive per-speaker training data or modeling.
However, the paper also acknowledges some limitations of the current work. For example, the speech unit database may not perfectly capture all the nuances and variations of different speakers' voices, which could impact the quality of the synthesized speech. Additionally, the self-supervised learning approach relies on having access to large amounts of unlabeled speech data, which may not always be readily available.
Further research could explore ways to address these limitations, such as investigating more advanced unit selection and concatenation techniques, or exploring alternative self-supervised learning strategies that can work with smaller datasets. It would also be interesting to see how SelectTTS performs in real-world applications and user studies, which could uncover additional challenges or areas for improvement.
Overall, the SelectTTS model represents an intriguing step forward in the field of text-to-speech synthesis, with the potential to enable more scalable and versatile voice-based technologies in the future.
Conclusion
The SelectTTS paper proposes a novel approach to text-to-speech synthesis that can generate speech in anyone's voice. By using a discrete unit-based frame selection method and leveraging self-supervised learning, the model aims to be more scalable and flexible than traditional multi-speaker TTS systems.
While the current implementation has some limitations, the core ideas behind SelectTTS - such as its discrete unit-based approach and use of self-supervised learning - hold promise for enabling more versatile and accessible voice technologies in the future. As the field of text-to-speech continues to evolve, research like this will be crucial in pushing the boundaries of what's possible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SelectTTS: Synthesizing Anyone's Voice via Discrete Unit-Based Frame Selection
Ismail Rasim Ulgen, Shreeram Suresh Chandra, Junchen Lu, Berrak Sisman
Synthesizing the voices of unseen speakers is a persisting challenge in multi-speaker text-to-speech (TTS). Most multi-speaker TTS models rely on modeling speaker characteristics through speaker conditioning during training. Modeling unseen speaker attributes through this approach has necessitated an increase in model complexity, which makes it challenging to reproduce results and improve upon them. We design a simple alternative to this. We propose SelectTTS, a novel method to select the appropriate frames from the target speaker and decode using frame-level self-supervised learning (SSL) features. We show that this approach can effectively capture speaker characteristics for unseen speakers, and achieves comparable results to other multi-speaker TTS frameworks in both objective and subjective metrics. With SelectTTS, we show that frame selection from the target speaker's speech is a direct way to achieve generalization in unseen speakers with low model complexity. We achieve better speaker similarity performance than SOTA baselines XTTS-v2 and VALL-E with over an 8x reduction in model parameters and a 270x reduction in training data
Read more9/2/2024
🗣️
0
Analyzing Speech Unit Selection for Textless Speech-to-Speech Translation
Jarod Duret (LIA), Yannick Est`eve (LIA), Titouan Parcollet (CAM)
Recent advancements in textless speech-to-speech translation systems have been driven by the adoption of self-supervised learning techniques. Although most state-of-the-art systems adopt a similar architecture to transform source language speech into sequences of discrete representations in the target language, the criteria for selecting these target speech units remains an open question. This work explores the selection process through a study of downstream tasks such as automatic speech recognition, speech synthesis, speaker recognition, and emotion recognition. Interestingly, our findings reveal a discrepancy in the optimization of discrete speech units: units that perform well in resynthesis performance do not necessarily correlate with those that enhance translation efficacy. This discrepancy underscores the nuanced complexity of target feature selection and its impact on the overall performance of speech-to-speech translation systems.
Read more7/29/2024
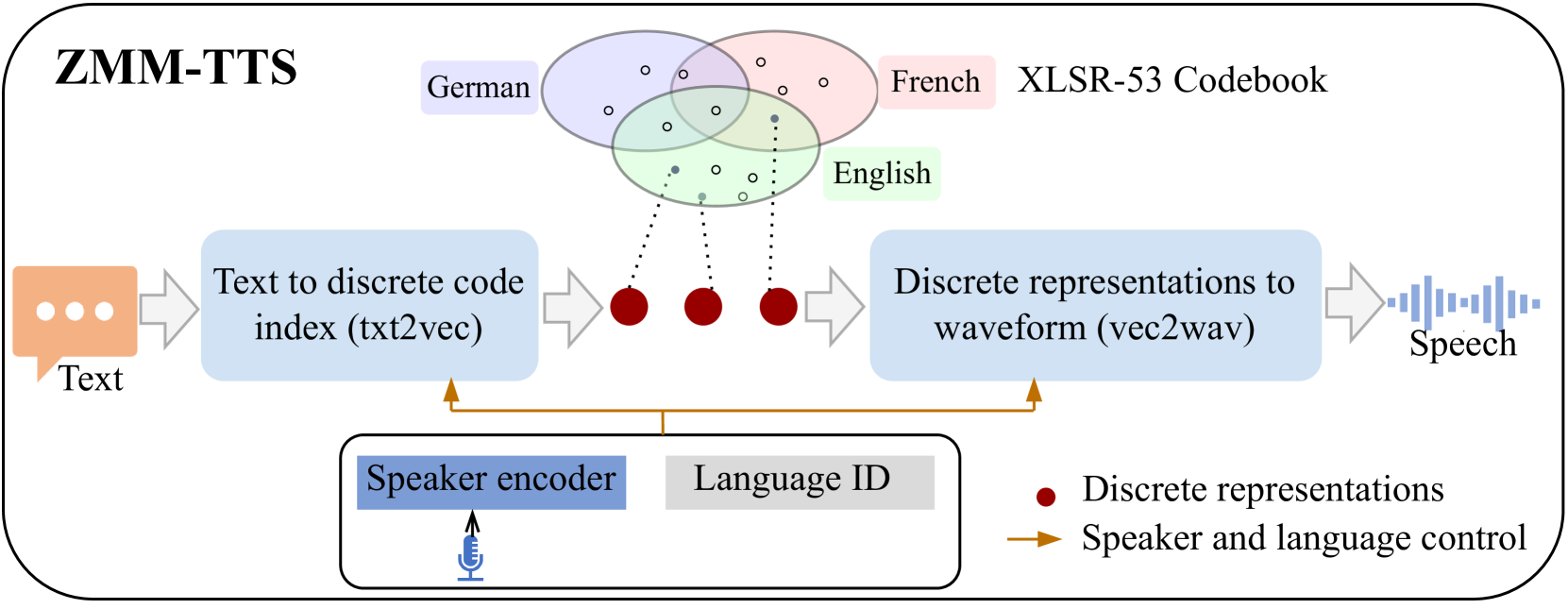
0
ZMM-TTS: Zero-shot Multilingual and Multispeaker Speech Synthesis Conditioned on Self-supervised Discrete Speech Representations
Cheng Gong, Xin Wang, Erica Cooper, Dan Wells, Longbiao Wang, Jianwu Dang, Korin Richmond, Junichi Yamagishi
Neural text-to-speech (TTS) has achieved human-like synthetic speech for single-speaker, single-language synthesis. Multilingual TTS systems are limited to resource-rich languages due to the lack of large paired text and studio-quality audio data. TTS systems are typically built using a single speaker's voices, but there is growing interest in developing systems that can synthesize voices for new speakers using only a few seconds of their speech. This paper presents ZMM-TTS, a multilingual and multispeaker framework utilizing quantized latent speech representations from a large-scale, pre-trained, self-supervised model. Our paper combines text-based and speech-based self-supervised learning models for multilingual speech synthesis. Our proposed model has zero-shot generalization ability not only for unseen speakers but also for unseen languages. We have conducted comprehensive subjective and objective evaluations through a series of experiments. Our model has proven effective in terms of speech naturalness and similarity for both seen and unseen speakers in six high-resource languages. We also tested the efficiency of our method on two hypothetically low-resource languages. The results are promising, indicating that our proposed approach can synthesize audio that is intelligible and has a high degree of similarity to the target speaker's voice, even without any training data for the new, unseen language.
Read more8/28/2024

0
On the Problem of Text-To-Speech Model Selection for Synthetic Data Generation in Automatic Speech Recognition
Nick Rossenbach, Ralf Schluter, Sakriani Sakti
The rapid development of neural text-to-speech (TTS) systems enabled its usage in other areas of natural language processing such as automatic speech recognition (ASR) or spoken language translation (SLT). Due to the large number of different TTS architectures and their extensions, selecting which TTS systems to use for synthetic data creation is not an easy task. We use the comparison of five different TTS decoder architectures in the scope of synthetic data generation to show the impact on CTC-based speech recognition training. We compare the recognition results to computable metrics like NISQA MOS and intelligibility, finding that there are no clear relations to the ASR performance. We also observe that for data generation auto-regressive decoding performs better than non-autoregressive decoding, and propose an approach to quantify TTS generalization capabilities.
Read more8/1/2024