On the Problem of Text-To-Speech Model Selection for Synthetic Data Generation in Automatic Speech Recognition

0

Sign in to get full access
Overview
- Explores the problem of selecting the right text-to-speech (TTS) model for generating synthetic data to improve automatic speech recognition (ASR) systems.
- Highlights the importance of choosing an appropriate TTS model to produce high-quality synthetic speech data that can effectively augment real-world speech data for ASR training.
- Discusses the trade-offs and considerations involved in TTS model selection for synthetic data generation.
Plain English Explanation
The paper looks at the challenge of picking the right text-to-speech (TTS) model to create artificial speech data that can be used to train automatic speech recognition (ASR) systems. The key idea is that by generating synthetic speech, you can expand the training data for ASR models and potentially improve their performance, especially on underrepresented speech styles or accents.
However, the choice of TTS model is important - if the synthetic speech doesn't sound natural or representative enough, it may not provide the desired benefit to the ASR system. The researchers explore the tradeoffs and considerations involved in selecting the appropriate TTS model for this task of generating high-quality synthetic speech data.
Technical Explanation
The paper investigates the problem of selecting the right text-to-speech (TTS) model to generate synthetic speech data that can effectively augment real-world speech data for training automatic speech recognition (ASR) systems.
The authors discuss the key factors to consider when choosing a TTS model for synthetic data generation, such as the naturalness of the generated speech, the match between the synthetic and real-world speech distributions, and the performance impact on the downstream ASR model. They analyze how different TTS models, including phonetic-enhanced language models and large pre-trained TTS systems, can affect the quality and utility of the synthetic speech data.
The paper also explores techniques like data augmentation to improve the performance of ASR models trained on a combination of real and synthetic data. The researchers highlight the trade-offs and considerations involved in selecting the appropriate TTS model for effective synthetic data generation in the context of ASR system development.
Critical Analysis
The paper provides a valuable discussion on the important problem of TTS model selection for synthetic data generation in ASR. It acknowledges the potential benefits of using synthetic speech data to augment real-world training data, but also highlights the critical need to choose the right TTS model to ensure the synthetic data is of high quality and can meaningfully improve ASR performance.
One limitation of the paper is that it does not provide a detailed empirical evaluation of different TTS models and their impact on ASR. While the authors discuss the theoretical considerations, more experimental evidence would be helpful to quantify the performance differences and trade-offs.
Additionally, the paper does not address other potential issues that could arise from relying too heavily on synthetic data, such as model overfitting or the risk of introducing systematic biases. Further research is needed to understand the long-term implications and best practices for incorporating synthetic speech data into ASR system development.
Conclusion
This paper underscores the importance of carefully selecting the appropriate text-to-speech (TTS) model when generating synthetic data to augment training of automatic speech recognition (ASR) systems. The choice of TTS model can significantly impact the quality and utility of the synthetic speech data, which in turn affects the performance of the ASR model.
The researchers highlight the various factors to consider, such as speech naturalness, distribution matching, and downstream ASR impact. While the potential benefits of synthetic data for ASR are clear, the paper underscores the need for careful model selection and further research to fully understand the trade-offs and best practices in this area. Addressing these challenges will be crucial for advancing the state-of-the-art in speech recognition systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the Problem of Text-To-Speech Model Selection for Synthetic Data Generation in Automatic Speech Recognition
Nick Rossenbach, Ralf Schluter, Sakriani Sakti
The rapid development of neural text-to-speech (TTS) systems enabled its usage in other areas of natural language processing such as automatic speech recognition (ASR) or spoken language translation (SLT). Due to the large number of different TTS architectures and their extensions, selecting which TTS systems to use for synthetic data creation is not an easy task. We use the comparison of five different TTS decoder architectures in the scope of synthetic data generation to show the impact on CTC-based speech recognition training. We compare the recognition results to computable metrics like NISQA MOS and intelligibility, finding that there are no clear relations to the ASR performance. We also observe that for data generation auto-regressive decoding performs better than non-autoregressive decoding, and propose an approach to quantify TTS generalization capabilities.
Read more8/1/2024
🏋️
0
On the Effect of Purely Synthetic Training Data for Different Automatic Speech Recognition Architectures
Nick Rossenbach, Benedikt Hilmes, Ralf Schluter
In this work we evaluate the utility of synthetic data for training automatic speech recognition (ASR). We use the ASR training data to train a text-to-speech (TTS) system similar to FastSpeech-2. With this TTS we reproduce the original training data, training ASR systems solely on synthetic data. For ASR, we use three different architectures, attention-based encoder-decoder, hybrid deep neural network hidden Markov model and a Gaussian mixture hidden Markov model, showing the different sensitivity of the models to synthetic data generation. In order to extend previous work, we present a number of ablation studies on the effectiveness of synthetic vs. real training data for ASR. In particular we focus on how the gap between training on synthetic and real data changes by varying the speaker embedding or by scaling the model size. For the latter we show that the TTS models generalize well, even when training scores indicate overfitting.
Read more7/26/2024
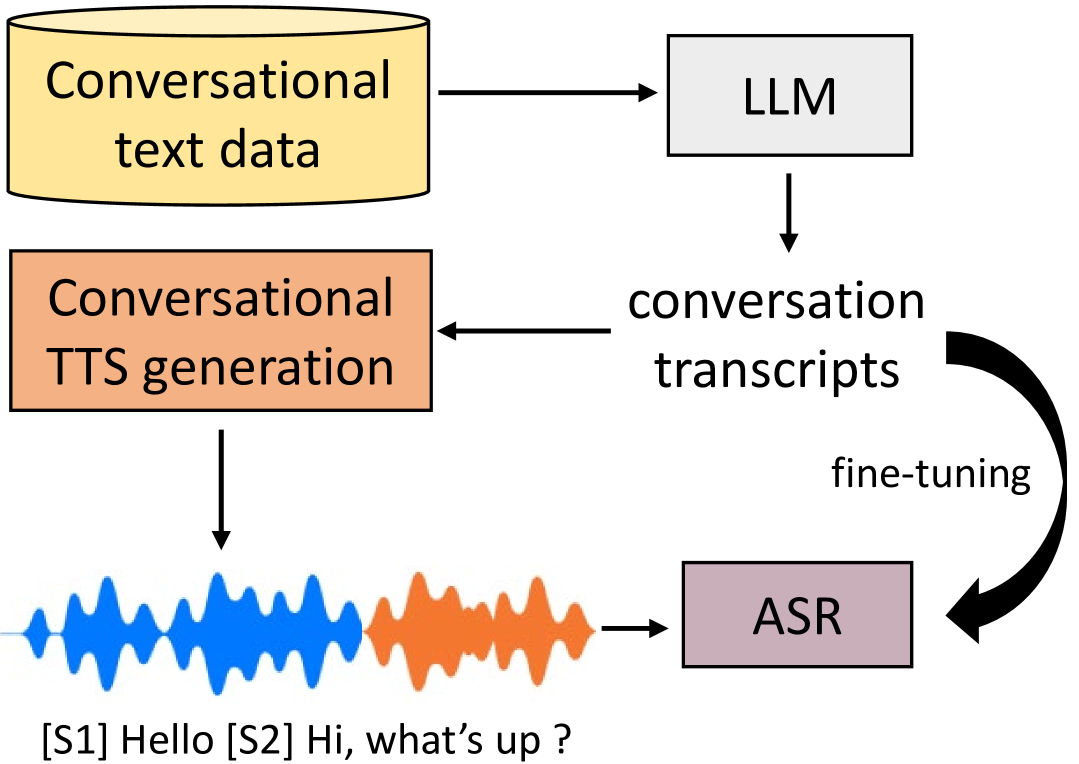
0
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024

0
TTSDS -- Text-to-Speech Distribution Score
Christoph Minixhofer, Ondv{r}ej Klejch, Peter Bell
Many recently published Text-to-Speech (TTS) systems produce audio close to real speech. However, TTS evaluation needs to be revisited to make sense of the results obtained with the new architectures, approaches and datasets. We propose evaluating the quality of synthetic speech as a combination of multiple factors such as prosody, speaker identity, and intelligibility. Our approach assesses how well synthetic speech mirrors real speech by obtaining correlates of each factor and measuring their distance from both real speech datasets and noise datasets. We benchmark 35 TTS systems developed between 2008 and 2024 and show that our score computed as an unweighted average of factors strongly correlates with the human evaluations from each time period.
Read more7/23/2024