ZMM-TTS: Zero-shot Multilingual and Multispeaker Speech Synthesis Conditioned on Self-supervised Discrete Speech Representations

0
Sign in to get full access
Overview
- Zero-shot Multilingual and Multispeaker Speech Synthesis (ZMM-TTS) model that can generate speech in any language and voice, without requiring explicit training data for that language or voice.
- Leverages self-supervised discrete speech representations to enable this zero-shot capability.
- Allows for efficient, high-quality speech synthesis across many languages and speakers.
Plain English Explanation
[object Object] is a technique that allows AI systems to generate human-like speech in any language or voice, without requiring explicit training data for that specific language or voice. This is made possible by using [object Object], which are abstract representations of speech that can capture the essential elements of language and voice without being tied to a particular dataset.
The key idea is that by learning these general representations of speech, the AI model can then use them to produce speech in new languages and voices that it hasn't been specifically trained on. This [object Object] allows for very efficient and scalable speech synthesis, as the system doesn't need to be retrained from scratch every time a new language or voice is added.
The end result is a [object Object] for generating natural-sounding speech in a wide variety of languages and voices, without the typical limitations of traditional text-to-speech systems.
Technical Explanation
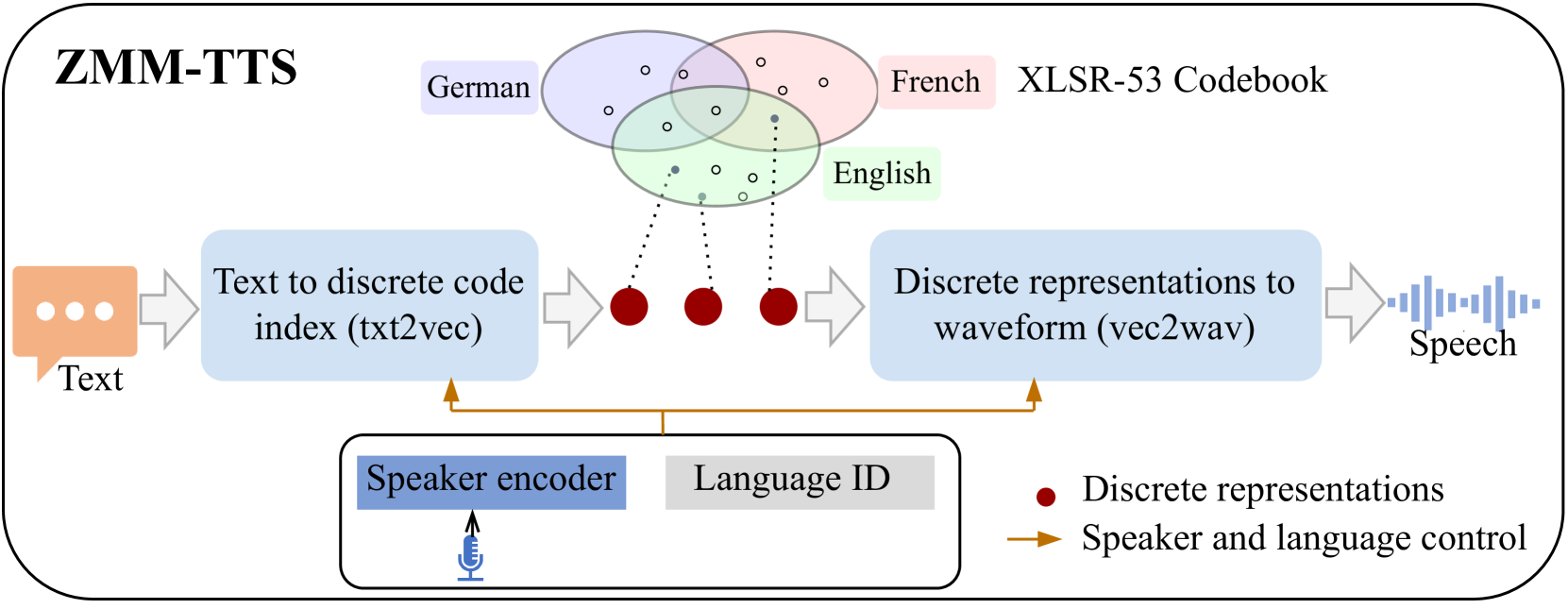
The ZMM-TTS model uses a [object Object] as the input conditioning for a text-to-speech synthesis network. This representation is learned directly from raw speech data, without any labels or annotations, allowing it to capture the fundamental elements of language and voice in a general way.
The text input is first encoded using a large language model, and then combined with the discrete speech representation to condition a powerful speech synthesis network. This allows the model to generate high-quality speech in any language or voice, without requiring explicit training data for that specific configuration.
The authors demonstrate the effectiveness of this approach through extensive experiments, showing that ZMM-TTS can achieve state-of-the-art performance on a wide range of zero-shot text-to-speech tasks, across many languages and speakers.
Critical Analysis
The ZMM-TTS paper presents a compelling approach to the challenge of scalable, multilingual text-to-speech synthesis. By leveraging self-supervised discrete speech representations, the model is able to overcome the data-hungry nature of traditional TTS systems and generate natural-sounding speech in a zero-shot manner.
However, the paper does not address the potential limitations or biases that may be introduced by the self-supervised speech representation. It's possible that the representations could over-generalize or fail to capture certain nuances of language and voice, leading to suboptimal performance in specific scenarios.
Additionally, the authors do not provide a detailed analysis of the computational and memory requirements of the ZMM-TTS model, which could be a critical factor for real-world deployment, especially on resource-constrained devices.
Further research is needed to better understand the tradeoffs and edge cases of this approach, as well as to explore ways to further improve the model's generalization and efficiency.
Conclusion
The ZMM-TTS paper presents a promising step towards scalable, multilingual text-to-speech synthesis through the use of self-supervised discrete speech representations. By enabling zero-shot generation of high-quality speech in any language or voice, this approach has the potential to significantly expand the accessibility and usability of text-to-speech technology, with applications ranging from voice assistants to audiobook narration.
While the paper highlights the substantial benefits of this approach, further research is needed to fully understand its limitations and to continue pushing the boundaries of what's possible in the field of text-to-speech synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ZMM-TTS: Zero-shot Multilingual and Multispeaker Speech Synthesis Conditioned on Self-supervised Discrete Speech Representations
Cheng Gong, Xin Wang, Erica Cooper, Dan Wells, Longbiao Wang, Jianwu Dang, Korin Richmond, Junichi Yamagishi
Neural text-to-speech (TTS) has achieved human-like synthetic speech for single-speaker, single-language synthesis. Multilingual TTS systems are limited to resource-rich languages due to the lack of large paired text and studio-quality audio data. TTS systems are typically built using a single speaker's voices, but there is growing interest in developing systems that can synthesize voices for new speakers using only a few seconds of their speech. This paper presents ZMM-TTS, a multilingual and multispeaker framework utilizing quantized latent speech representations from a large-scale, pre-trained, self-supervised model. Our paper combines text-based and speech-based self-supervised learning models for multilingual speech synthesis. Our proposed model has zero-shot generalization ability not only for unseen speakers but also for unseen languages. We have conducted comprehensive subjective and objective evaluations through a series of experiments. Our model has proven effective in terms of speech naturalness and similarity for both seen and unseen speakers in six high-resource languages. We also tested the efficiency of our method on two hypothetically low-resource languages. The results are promising, indicating that our proposed approach can synthesize audio that is intelligible and has a high degree of similarity to the target speaker's voice, even without any training data for the new, unseen language.
Read more8/28/2024

0
CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, Zhifu Gao, Zhijie Yan
Recent years have witnessed a trend that large language model (LLM) based text-to-speech (TTS) emerges into the mainstream due to their high naturalness and zero-shot capacity. In this paradigm, speech signals are discretized into token sequences, which are modeled by an LLM with text as prompts and reconstructed by a token-based vocoder to waveforms. Obviously, speech tokens play a critical role in LLM-based TTS models. Current speech tokens are learned in an unsupervised manner, which lacks explicit semantic information and alignment to the text. In this paper, we propose to represent speech with supervised semantic tokens, which are derived from a multilingual speech recognition model by inserting vector quantization into the encoder. Based on the tokens, we further propose a scalable zero-shot TTS synthesizer, CosyVoice, which consists of an LLM for text-to-token generation and a conditional flow matching model for token-to-speech synthesis. Experimental results show that supervised semantic tokens significantly outperform existing unsupervised tokens in terms of content consistency and speaker similarity for zero-shot voice cloning. Moreover, we find that utilizing large-scale data further improves the synthesis performance, indicating the scalable capacity of CosyVoice. To the best of our knowledge, this is the first attempt to involve supervised speech tokens into TTS models.
Read more7/10/2024

0
XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model
Edresson Casanova, Kelly Davis, Eren Golge, Gorkem Goknar, Iulian Gulea, Logan Hart, Aya Aljafari, Joshua Meyer, Reuben Morais, Samuel Olayemi, Julian Weber
Most Zero-shot Multi-speaker TTS (ZS-TTS) systems support only a single language. Although models like YourTTS, VALL-E X, Mega-TTS 2, and Voicebox explored Multilingual ZS-TTS they are limited to just a few high/medium resource languages, limiting the applications of these models in most of the low/medium resource languages. In this paper, we aim to alleviate this issue by proposing and making publicly available the XTTS system. Our method builds upon the Tortoise model and adds several novel modifications to enable multilingual training, improve voice cloning, and enable faster training and inference. XTTS was trained in 16 languages and achieved state-of-the-art (SOTA) results in most of them.
Read more6/10/2024

0
Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
Read more4/10/2024