SelEx: Self-Expertise in Fine-Grained Generalized Category Discovery

0
Sign in to get full access
Overview
- SelEx is a novel method for fine-grained generalized category discovery
- It learns a hierarchical representation that captures both coarse and fine-grained concepts
- SelEx outperforms state-of-the-art methods on several fine-grained classification benchmarks
Plain English Explanation
SelEx is a machine learning technique that can discover and organize a large number of detailed categories from visual data. Rather than just learning broad categories, SelEx is able to identify many specific subcategories within those broader groups.
This is done by learning a hierarchical representation - a multi-layered understanding of the data that captures both coarse-grained and fine-grained concepts. The model essentially teaches itself to become an expert on the nuanced details within the broader categories.
Experiments show that SelEx outperforms other self-supervised learning methods at fine-grained visual classification tasks. By uncovering the latent expertise within the model, SelEx is able to discover a richer set of detailed categories compared to previous approaches.
Technical Explanation
SelEx learns a hierarchical representation that captures both coarse and fine-grained visual concepts. The key idea is to leverage the model's own specialization to discover a more nuanced set of categories.
The approach involves two main steps:
- Self-supervised pretraining: The model is first trained on a large dataset using a self-supervised objective to learn general visual representations.
- Self-expertise discovery: The pretrained model is then fine-tuned using a novel loss function that encourages the model to discover its own specialized sub-concepts within the broader categories.
This contextual information helps the model uncover a rich hierarchical structure, outperforming previous methods on several fine-grained classification benchmarks.
Critical Analysis
The paper provides a thorough evaluation of SelEx on multiple datasets, showing consistent improvements over prior work. However, the authors acknowledge that SelEx may be limited in its ability to discover completely novel categories outside of the model's existing specialization.
Additionally, the self-expertise discovery process relies on a specialized loss function, which could be computationally expensive or unstable to optimize in certain cases. Further research may be needed to simplify or generalize this aspect of the approach.
Overall, SelEx represents an interesting step towards more nuanced and hierarchical representation learning for fine-grained category discovery. But there is still room for improvement, especially in terms of the model's ability to uncover truly unexpected or unfamiliar concepts.
Conclusion
SelEx is a novel method that leverages a model's own self-specialization to discover a rich hierarchy of fine-grained visual categories. By learning a multi-layered representation of both coarse and detailed concepts, SelEx outperforms state-of-the-art methods on several benchmarks.
This work highlights the potential of self-expertise as a powerful signal for enhancing representation learning and category discovery. As machine learning models become more sophisticated, techniques like SelEx may play an important role in building systems with a deeper, more nuanced understanding of the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SelEx: Self-Expertise in Fine-Grained Generalized Category Discovery
Sarah Rastegar, Mohammadreza Salehi, Yuki M. Asano, Hazel Doughty, Cees G. M. Snoek
In this paper, we address Generalized Category Discovery, aiming to simultaneously uncover novel categories and accurately classify known ones. Traditional methods, which lean heavily on self-supervision and contrastive learning, often fall short when distinguishing between fine-grained categories. To address this, we introduce a novel concept called `self-expertise', which enhances the model's ability to recognize subtle differences and uncover unknown categories. Our approach combines unsupervised and supervised self-expertise strategies to refine the model's discernment and generalization. Initially, hierarchical pseudo-labeling is used to provide `soft supervision', improving the effectiveness of self-expertise. Our supervised technique differs from traditional methods by utilizing more abstract positive and negative samples, aiding in the formation of clusters that can generalize to novel categories. Meanwhile, our unsupervised strategy encourages the model to sharpen its category distinctions by considering within-category examples as `hard' negatives. Supported by theoretical insights, our empirical results showcase that our method outperforms existing state-of-the-art techniques in Generalized Category Discovery across several fine-grained datasets. Our code is available at: https://github.com/SarahRastegar/SelEx.
Read more8/27/2024

0
A Generic Method for Fine-grained Category Discovery in Natural Language Texts
Chang Tian, Matthew B. Blaschko, Wenpeng Yin, Mingzhe Xing, Yinliang Yue, Marie-Francine Moens
Fine-grained category discovery using only coarse-grained supervision is a cost-effective yet challenging task. Previous training methods focus on aligning query samples with positive samples and distancing them from negatives. They often neglect intra-category and inter-category semantic similarities of fine-grained categories when navigating sample distributions in the embedding space. Furthermore, some evaluation techniques that rely on pre-collected test samples are inadequate for real-time applications. To address these shortcomings, we introduce a method that successfully detects fine-grained clusters of semantically similar texts guided by a novel objective function. The method uses semantic similarities in a logarithmic space to guide sample distributions in the Euclidean space and to form distinct clusters that represent fine-grained categories. We also propose a centroid inference mechanism to support real-time applications. The efficacy of the method is both theoretically justified and empirically confirmed on three benchmark tasks. The proposed objective function is integrated in multiple contrastive learning based neural models. Its results surpass existing state-of-the-art approaches in terms of Accuracy, Adjusted Rand Index and Normalized Mutual Information of the detected fine-grained categories. Code and data will be available at https://github.com/XX upon publication.
Read more6/21/2024
👀
0
Self-Training: A Survey
Massih-Reza Amini, Vasilii Feofanov, Loic Pauletto, Lies Hadjadj, Emilie Devijver, Yury Maximov
Semi-supervised algorithms aim to learn prediction functions from a small set of labeled observations and a large set of unlabeled observations. Because this framework is relevant in many applications, they have received a lot of interest in both academia and industry. Among the existing techniques, self-training methods have undoubtedly attracted greater attention in recent years. These models are designed to find the decision boundary on low density regions without making additional assumptions about the data distribution, and use the unsigned output score of a learned classifier, or its margin, as an indicator of confidence. The working principle of self-training algorithms is to learn a classifier iteratively by assigning pseudo-labels to the set of unlabeled training samples with a margin greater than a certain threshold. The pseudo-labeled examples are then used to enrich the labeled training data and to train a new classifier in conjunction with the labeled training set. In this paper, we present self-training methods for binary and multi-class classification; as well as their variants and two related approaches, namely consistency-based approaches and transductive learning. We examine the impact of significant self-training features on various methods, using different general and image classification benchmarks, and we discuss our ideas for future research in self-training. To the best of our knowledge, this is the first thorough and complete survey on this subject.
Read more5/28/2024
0
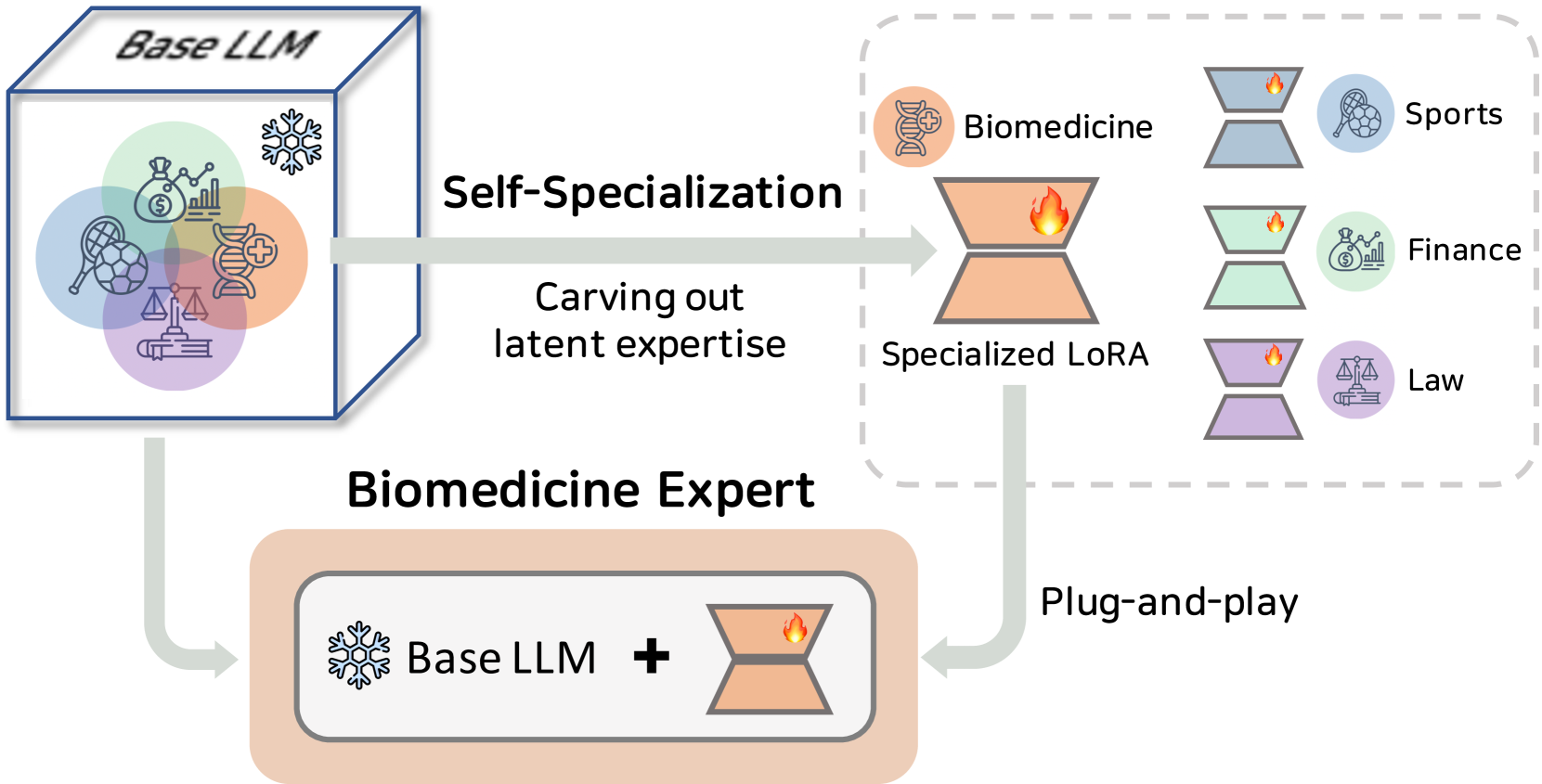
Self-Specialization: Uncovering Latent Expertise within Large Language Models
Junmo Kang, Hongyin Luo, Yada Zhu, Jacob Hansen, James Glass, David Cox, Alan Ritter, Rogerio Feris, Leonid Karlinsky
Recent works have demonstrated the effectiveness of self-alignment in which a large language model is aligned to follow general instructions using instructional data generated from the model itself starting from a handful of human-written seeds. Instead of general alignment, in this work, we focus on self-alignment for expert domain specialization (e.g., biomedicine, finance). As a preliminary, we quantitively show the marginal effect that generic instruction-following training has on downstream expert domains' performance. To remedy this, we propose self-specialization - allowing for effective model specialization while achieving cross-task generalization by leveraging only a few labeled seeds. Self-specialization offers a data- and parameter-efficient way of carving out an expert model out of a generalist pre-trained LLM. Exploring a variety of popular open large models as a base for specialization, our experimental results in both biomedical and financial domains show that our self-specialized models outperform their base models by a large margin, and even larger models that are generally instruction-tuned or that have been adapted to the target domain by other means.
Read more6/7/2024