Self-Cooperation Knowledge Distillation for Novel Class Discovery

0

Sign in to get full access
Overview
- This paper presents a novel approach called "Self-Cooperation Knowledge Distillation" for discovering new classes of data in machine learning models.
- The key idea is to leverage the model's own knowledge to discover novel classes, without requiring any additional labeled data.
- This is achieved by having the model "teach itself" using a self-distillation process, which helps the model identify and learn about new classes in the data.
Plain English Explanation
Machine learning models are often trained on a fixed set of known classes or categories. However, in many real-world scenarios, there may be new, previously unseen classes that emerge over time. Continual novel class discovery via feature enhancement and CKD: Contrastive Knowledge Distillation from Sample-wise are two examples of research exploring this problem.
The "Self-Cooperation Knowledge Distillation" approach proposed in this paper aims to address this challenge. The key insight is that the model itself can be leveraged to discover new classes, without requiring any additional labeled data. The model essentially "teaches itself" about the new classes through a self-distillation process.
This self-distillation process involves the model generating its own "soft" labels or predictions, and then using those predictions to learn about the new classes. By cooperating with its own outputs, the model can identify and learn the characteristics of the novel classes, allowing it to expand its knowledge over time.
This approach is particularly useful in scenarios where obtaining labeled data for new classes is difficult or expensive, such as in medical imaging or industrial applications. By allowing the model to discover new classes on its own, it can continuously adapt and improve its performance without the need for constant human intervention.
Technical Explanation
The core idea behind "Self-Cooperation Knowledge Distillation" is to leverage the model's own knowledge to discover novel classes, without requiring any additional labeled data. This is achieved through a self-distillation process, where the model generates its own "soft" labels or predictions and then uses those predictions to learn about the new classes.
The proposed approach consists of two main components:
-
Self-Cooperation Learning: In this stage, the model is trained on the known classes using standard supervised learning. Concurrently, the model generates its own "soft" labels or predictions for the input data, and then uses these predictions to learn about the novel classes through a self-distillation process.
-
Novel Class Discovery: The model's self-generated predictions are used to identify potential novel classes. This is done by analyzing the model's confidence in its own predictions and identifying regions of the feature space where the model is uncertain. These regions are then used to discover and learn about the new classes.
The authors note that this approach is related to Practical Approach to Novel Class Discovery in Tabular Data and Guiding Frame-Level CTC Alignments Using Self-Knowledge Distillation, which also explore the idea of using a model's own knowledge to discover novel classes.
Through extensive experiments on various benchmark datasets, the authors demonstrate the effectiveness of their "Self-Cooperation Knowledge Distillation" approach in discovering novel classes while maintaining high performance on the known classes.
Critical Analysis
The "Self-Cooperation Knowledge Distillation" approach presented in this paper is a novel and promising technique for discovering new classes in machine learning models. By leveraging the model's own knowledge, it avoids the need for additional labeled data, which can be a significant bottleneck in many real-world applications.
One potential limitation of this approach is that it relies on the model's ability to accurately identify regions of the feature space where novel classes may exist. If the model's initial knowledge is limited or biased, it may fail to identify these regions correctly, leading to suboptimal novel class discovery. Further research may be needed to address this issue and improve the robustness of the approach.
Additionally, the authors mention that their approach is related to Self-Knowledge Distillation: Learning Ambiguity, which explores a similar idea of using a model's own knowledge to learn about new concepts. It would be interesting to see a more detailed comparison of these related approaches and how they differ in their specific techniques and applications.
Overall, the "Self-Cooperation Knowledge Distillation" approach is a compelling contribution to the field of novel class discovery, and it has the potential to significantly impact a wide range of machine learning applications where adapting to new data is crucial.
Conclusion
The "Self-Cooperation Knowledge Distillation" approach presented in this paper offers a novel solution for discovering new classes in machine learning models without the need for additional labeled data. By leveraging the model's own knowledge through a self-distillation process, the approach can identify and learn about new classes, allowing the model to continuously expand its understanding of the data.
This technique has important implications for real-world applications where adapting to new and emerging data is crucial, such as medical imaging, industrial automation, and many others. By reducing the reliance on labeled data, the "Self-Cooperation Knowledge Distillation" approach can help make machine learning models more flexible, scalable, and responsive to the changing needs of the application domain.
As the field of machine learning continues to evolve, techniques like "Self-Cooperation Knowledge Distillation" will be increasingly important in enabling models to learn and grow in an autonomous and efficient manner, paving the way for more robust and adaptable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Cooperation Knowledge Distillation for Novel Class Discovery
Yuzheng Wang, Zhaoyu Chen, Dingkang Yang, Yunquan Sun, Lizhe Qi
Novel Class Discovery (NCD) aims to discover unknown and novel classes in an unlabeled set by leveraging knowledge already learned about known classes. Existing works focus on instance-level or class-level knowledge representation and build a shared representation space to achieve performance improvements. However, a long-neglected issue is the potential imbalanced number of samples from known and novel classes, pushing the model towards dominant classes. Therefore, these methods suffer from a challenging trade-off between reviewing known classes and discovering novel classes. Based on this observation, we propose a Self-Cooperation Knowledge Distillation (SCKD) method to utilize each training sample (whether known or novel, labeled or unlabeled) for both review and discovery. Specifically, the model's feature representations of known and novel classes are used to construct two disjoint representation spaces. Through spatial mutual information, we design a self-cooperation learning to encourage model learning from the two feature representation spaces from itself. Extensive experiments on six datasets demonstrate that our method can achieve significant performance improvements, achieving state-of-the-art performance.
Read more7/4/2024

0
NC-NCD: Novel Class Discovery for Node Classification
Yue Hou, Xueyuan Chen, He Zhu, Romei Liu, Bowen Shi, Jiaheng Liu, Junran Wu, Ke Xu
Novel Class Discovery (NCD) involves identifying new categories within unlabeled data by utilizing knowledge acquired from previously established categories. However, existing NCD methods often struggle to maintain a balance between the performance of old and new categories. Discovering unlabeled new categories in a class-incremental way is more practical but also more challenging, as it is frequently hindered by either catastrophic forgetting of old categories or an inability to learn new ones. Furthermore, the implementation of NCD on continuously scalable graph-structured data remains an under-explored area. In response to these challenges, we introduce for the first time a more practical NCD scenario for node classification (i.e., NC-NCD), and propose a novel self-training framework with prototype replay and distillation called SWORD, adopted to our NC-NCD setting. Our approach enables the model to cluster unlabeled new category nodes after learning labeled nodes while preserving performance on old categories without reliance on old category nodes. SWORD achieves this by employing a self-training strategy to learn new categories and preventing the forgetting of old categories through the joint use of feature prototypes and knowledge distillation. Extensive experiments on four common benchmarks demonstrate the superiority of SWORD over other state-of-the-art methods.
Read more7/26/2024
✨
0
Continual Novel Class Discovery via Feature Enhancement and Adaptation
Yifan Yu, Shaokun Wang, Yuhang He, Junzhe Chen, Yihong Gong
Continual Novel Class Discovery (CNCD) aims to continually discover novel classes without labels while maintaining the recognition capability for previously learned classes. The main challenges faced by CNCD include the feature-discrepancy problem, the inter-session confusion problem, etc. In this paper, we propose a novel Feature Enhancement and Adaptation method for the CNCD to tackle the above challenges, which consists of a guide-to-novel framework, a centroid-to-samples similarity constraint (CSS), and a boundary-aware prototype constraint (BAP). More specifically, the guide-to-novel framework is established to continually discover novel classes under the guidance of prior distribution. Afterward, the CSS is designed to constrain the relationship between centroid-to-samples similarities of different classes, thereby enhancing the distinctiveness of features among novel classes. Finally, the BAP is proposed to keep novel class features aware of the positions of other class prototypes during incremental sessions, and better adapt novel class features to the shared feature space. Experimental results on three benchmark datasets demonstrate the superiority of our method, especially in more challenging protocols with more incremental sessions.
Read more5/13/2024
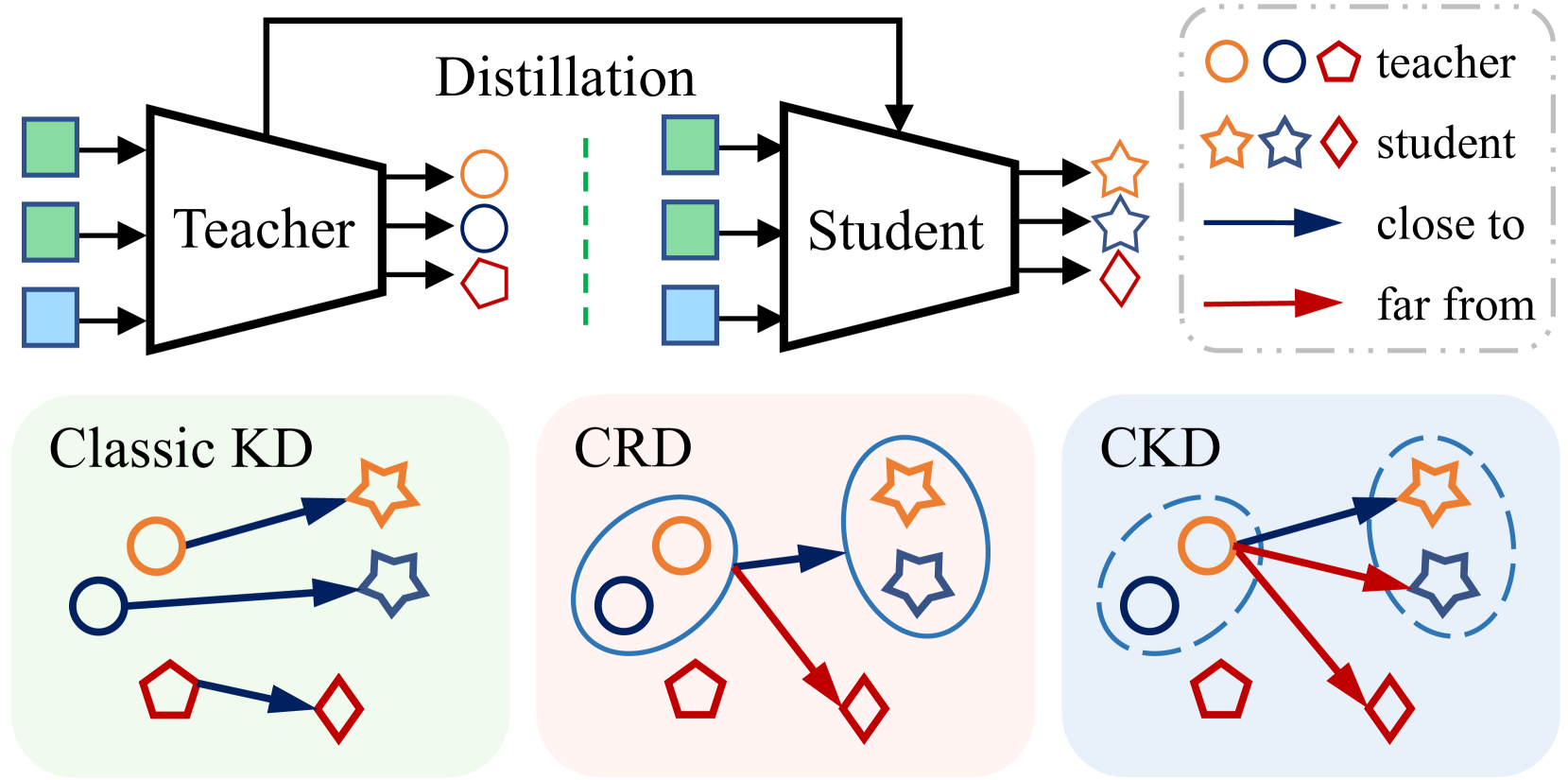
0
CKD: Contrastive Knowledge Distillation from A Sample-wise Perspective
Wencheng Zhu, Xin Zhou, Pengfei Zhu, Yu Wang, Qinghua Hu
In this paper, we present a simple yet effective contrastive knowledge distillation approach, which can be formulated as a sample-wise alignment problem with intra- and inter-sample constraints. Unlike traditional knowledge distillation methods that concentrate on maximizing feature similarities or preserving class-wise semantic correlations between teacher and student features, our method attempts to recover the dark knowledge by aligning sample-wise teacher and student logits. Specifically, our method first minimizes logit differences within the same sample by considering their numerical values, thus preserving intra-sample similarities. Next, we bridge semantic disparities by leveraging dissimilarities across different samples. Note that constraints on intra-sample similarities and inter-sample dissimilarities can be efficiently and effectively reformulated into a contrastive learning framework with newly designed positive and negative pairs. The positive pair consists of the teacher's and student's logits derived from an identical sample, while the negative pairs are formed by using logits from different samples. With this formulation, our method benefits from the simplicity and efficiency of contrastive learning through the optimization of InfoNCE, yielding a run-time complexity that is far less than $O(n^2)$, where $n$ represents the total number of training samples. Furthermore, our method can eliminate the need for hyperparameter tuning, particularly related to temperature parameters and large batch sizes. We conduct comprehensive experiments on three datasets including CIFAR-100, ImageNet-1K, and MS COCO. Experimental results clearly confirm the effectiveness of the proposed method on both image classification and object detection tasks. Our source codes will be publicly available at https://github.com/wencheng-zhu/CKD.
Read more4/23/2024