Self-Knowledge Distillation for Learning Ambiguity

0

Sign in to get full access
Overview
- This paper proposes a novel approach called "Self-Knowledge Distillation for Learning Ambiguity" (SKDA) to improve the performance of machine learning models in tasks that involve ambiguous or uncertain inputs.
- The key idea is to use a teacher-student framework where the teacher model learns to capture the inherent ambiguity in the data, and then transfers this knowledge to the student model through a distillation process.
- The authors demonstrate the effectiveness of SKDA on several benchmark datasets, showing that it outperforms other knowledge distillation techniques in tasks like image classification and natural language processing.
Plain English Explanation
The paper introduces a new way to train machine learning models to handle ambiguous or uncertain inputs. The main challenge in these tasks is that the model needs to learn not just a single correct answer, but to capture the inherent uncertainty or ambiguity in the data.
The SKDA approach works by first training a "teacher" model that learns to understand the ambiguity in the training data. This teacher model then shares its knowledge with a "student" model through a process called "knowledge distillation."
The key insight is that by transferring the teacher's understanding of ambiguity to the student, the student model can learn to make more nuanced and accurate predictions, even in the face of uncertain or ambiguous inputs. This can be particularly useful in real-world applications where the data is often messy or there may be multiple valid interpretations.
The authors show that this SKDA approach outperforms other knowledge distillation techniques on a range of tasks, including image classification and natural language processing. This suggests that the ability to learn and represent ambiguity is a valuable skill for machine learning models, and that the SKDA method is an effective way to imbue models with this capability.
Technical Explanation
The paper introduces a novel knowledge distillation framework called "Self-Knowledge Distillation for Learning Ambiguity" (SKDA) to address the challenge of training machine learning models to handle ambiguous or uncertain inputs.
The key idea behind SKDA is to first train a "teacher" model that is capable of capturing the inherent ambiguity in the training data. This teacher model is then used to guide the training of a "student" model through a knowledge distillation process.
Specifically, the teacher model is trained using a standard loss function, but with an additional term that encourages the model to output a distribution over possible labels, rather than a single predicted label. This teaches the teacher model to represent the uncertainty or ambiguity in the data.
During the distillation phase, the student model is trained to mimic the output distributions of the teacher model, in addition to learning from the ground-truth labels. This allows the student model to absorb the teacher's understanding of ambiguity, and apply it to make more nuanced predictions on new, unseen data.
The authors demonstrate the effectiveness of SKDA on several benchmark datasets, including image classification and natural language processing tasks. They show that the SKDA-trained student models outperform those trained using other knowledge distillation techniques, as well as the original teacher models.
Guiding Frame-Level CTC Alignments Using Self-Supervision and Knowledge Distillation for Learning Automatic Scoring Models in Science Education are two related works that also explore the use of knowledge distillation to improve model performance in the presence of uncertain or ambiguous inputs.
Critical Analysis
The SKDA approach presented in this paper is a promising step towards building more robust and versatile machine learning models. By explicitly teaching models to represent and reason about ambiguity, the authors have shown that it is possible to achieve better performance on a range of tasks involving uncertain or ambiguous inputs.
One potential limitation of the SKDA approach is that it relies on the ability to train an effective "teacher" model that can accurately capture the inherent ambiguity in the training data. In some cases, this may be challenging, particularly if the data itself is noisy or the sources of ambiguity are not well-understood.
Additionally, the authors do not explore the interpretability or explainability of the models trained using SKDA. Understanding why these models make the predictions they do, and how they represent ambiguity, could be an important area for future research, especially as these models are deployed in real-world applications.
Further research could also investigate the potential tradeoffs between the accuracy gains achieved by SKDA and the increased model complexity or computational requirements. It would be valuable to understand the scenarios where the benefits of SKDA outweigh these potential drawbacks.
Despite these potential limitations, the SKDA approach represents an important contribution to the field of machine learning, particularly in its ability to imbue models with a more nuanced understanding of the world and the inherent uncertainty that often accompanies real-world data.
Conclusion
The "Self-Knowledge Distillation for Learning Ambiguity" (SKDA) framework proposed in this paper offers a novel approach to training machine learning models that can effectively handle ambiguous or uncertain inputs. By teaching models to represent and reason about inherent ambiguity in the data, the SKDA method has been shown to outperform other knowledge distillation techniques on a range of benchmark tasks.
This work represents an important step forward in building more robust and versatile machine learning models, which could have significant implications for a wide variety of real-world applications where ambiguity and uncertainty are pervasive. As the field of AI continues to advance, the ability to capture and reason about ambiguity will likely become an increasingly valuable skill for machine learning models to possess.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Knowledge Distillation for Learning Ambiguity
Hancheol Park, Soyeong Jeong, Sukmin Cho, Jong C. Park
Recent language models have shown remarkable performance on natural language understanding (NLU) tasks. However, they are often sub-optimal when faced with ambiguous samples that can be interpreted in multiple ways, over-confidently predicting a single label without consideration for its correctness. To address this issue, we propose a novel self-knowledge distillation method that enables models to learn label distributions more accurately by leveraging knowledge distilled from their lower layers. This approach also includes a learning phase that re-calibrates the unnecessarily strengthened confidence for training samples judged as extremely ambiguous based on the distilled distribution knowledge. We validate our method on diverse NLU benchmark datasets and the experimental results demonstrate its effectiveness in producing better label distributions. Particularly, through the process of re-calibrating the confidence for highly ambiguous samples, the issue of over-confidence when predictions for unseen samples do not match with their ground-truth labels has been significantly alleviated. This has been shown to contribute to generating better distributions than the existing state-of-the-art method. Moreover, our method is more efficient in training the models compared to the existing method, as it does not involve additional training processes to refine label distributions.
Read more6/17/2024
0
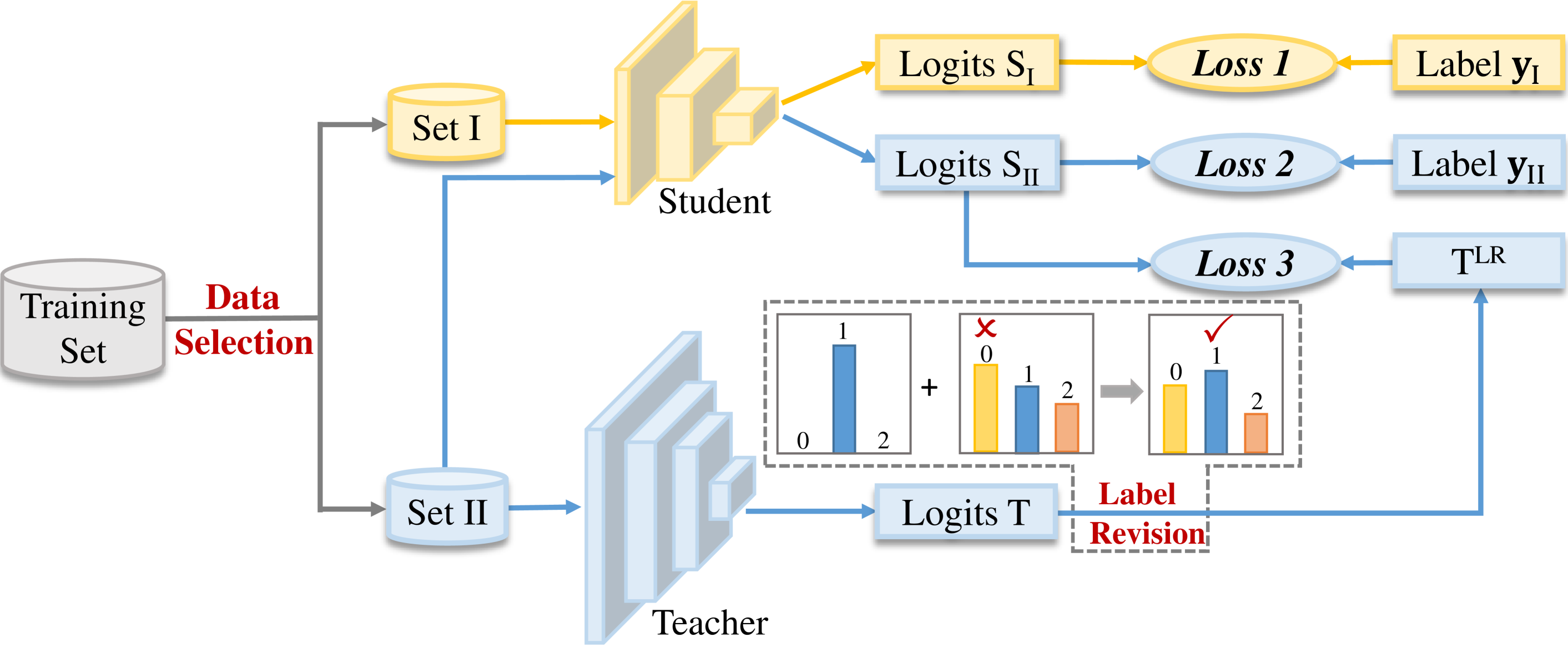
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
Read more4/8/2024
🌿
0
Distilling Robustness into Natural Language Inference Models with Domain-Targeted Augmentation
Joe Stacey, Marek Rei
Knowledge distillation optimises a smaller student model to behave similarly to a larger teacher model, retaining some of the performance benefits. While this method can improve results on in-distribution examples, it does not necessarily generalise to out-of-distribution (OOD) settings. We investigate two complementary methods for improving the robustness of the resulting student models on OOD domains. The first approach augments the distillation with generated unlabelled examples that match the target distribution. The second method upsamples data points among the training set that are similar to the target distribution. When applied on the task of natural language inference (NLI), our experiments on MNLI show that distillation with these modifications outperforms previous robustness solutions. We also find that these methods improve performance on OOD domains even beyond the target domain.
Read more7/26/2024

0
Knowledge Distillation of LLM for Automatic Scoring of Science Education Assessments
Ehsan Latif, Luyang Fang, Ping Ma, Xiaoming Zhai
This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 3% and 2% higher scoring accuracy than ANN and TinyBERT, respectively, and comparable accuracy to the teacher model. Furthermore, the student model size is 0.03M, 4,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
Read more6/13/2024