Self-Learning Symmetric Multi-view Probabilistic Clustering

0
🔗
Sign in to get full access
Overview
- Multi-view Clustering (MVC) aims to learn knowledge from multiple views of data to improve clustering performance.
- Most existing MVC methods are not applicable or require additional steps for handling incomplete data (missing views).
- Noise and outliers can significantly degrade the overall clustering performance, which are not well addressed by most existing methods.
Plain English Explanation
The paper proposes a novel framework called Self-Learning Symmetric Multi-view Probabilistic Clustering (SLS-MPC) that can handle both incomplete and complete multi-view data. SLS-MPC introduces a symmetric multi-view probability estimation approach that can work with any number of views, even when some views are missing. It then uses a self-learning probability function to learn the individual distribution of each view without needing any prior knowledge or hyperparameters.
To further improve the clustering performance, SLS-MPC applies a graph-context-aware refinement step that uses path propagation and co-neighbor propagation to alleviate the impact of noise and outliers. Finally, it proposes a probabilistic clustering algorithm that iteratively adjusts the clustering assignments by maximizing the joint probability, without requiring any category information.
The key innovations of SLS-MPC are its ability to handle incomplete data, its self-learning approach to estimate view-specific distributions, and its graph-based refinement to cope with noisy data - all of which lead to improved clustering performance compared to previous state-of-the-art methods.
Technical Explanation
SLS-MPC introduces a symmetric multi-view probability estimation approach that can handle any number of views, even with missing data. This is achieved by transforming the multi-view pairwise posterior matching probability into a composition of each view's individual distribution.
The self-learning probability function in SLS-MPC learns the individual distribution of each view without requiring any prior knowledge or hyperparameters. This allows the framework to adapt to the characteristics of each view and avoids the need for manual parameter tuning.
To address the impact of noise and outliers, SLS-MPC employs a graph-context-aware refinement step. This involves using path propagation and co-neighbor propagation to refine the pairwise probability, leveraging the graph structure of the data.
Finally, SLS-MPC proposes a probabilistic clustering algorithm that iteratively adjusts the clustering assignments by maximizing the joint probability, without needing any category information. This allows the framework to discover the underlying cluster structure of the data in an unsupervised manner.
Critical Analysis
The paper highlights the limitations of existing MVC methods in handling incomplete data and dealing with noise or outliers. SLS-MPC's ability to address these challenges is a significant contribution to the field.
However, the paper does not provide a detailed analysis of the computational complexity or scalability of the proposed framework. As the number of views or the size of the dataset increases, the performance and feasibility of SLS-MPC may need further investigation.
Additionally, the paper could have explored the interpretability of the learned view-specific distributions and their potential applications beyond clustering, such as in data analysis or visualization.
Conclusion
The Self-Learning Symmetric Multi-view Probabilistic Clustering (SLS-MPC) framework proposed in this paper represents a notable advancement in the field of Multi-view Clustering. By introducing a novel symmetric probability estimation, a self-learning approach to view-specific distributions, and a graph-context-aware refinement, SLS-MPC can effectively handle incomplete data and noisy inputs, leading to improved clustering performance.
This research paves the way for more robust and versatile multi-view clustering algorithms, with potential applications in areas such as image analysis, document classification, and recommendation systems. The insights and techniques presented in this paper could inspire further developments in the field of multi-view learning and data analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔗
0
Self-Learning Symmetric Multi-view Probabilistic Clustering
Junjie Liu, Junlong Liu, Rongxin Jiang, Yaowu Chen, Chen Shen, Jieping Ye
Multi-view Clustering (MVC) has achieved significant progress, with many efforts dedicated to learn knowledge from multiple views. However, most existing methods are either not applicable or require additional steps for incomplete MVC. Such a limitation results in poor-quality clustering performance and poor missing view adaptation. Besides, noise or outliers might significantly degrade the overall clustering performance, which are not handled well by most existing methods. In this paper, we propose a novel unified framework for incomplete and complete MVC named self-learning symmetric multi-view probabilistic clustering (SLS-MPC). SLS-MPC proposes a novel symmetric multi-view probability estimation and equivalently transforms multi-view pairwise posterior matching probability into composition of each view's individual distribution, which tolerates data missing and might extend to any number of views. Then, SLS-MPC proposes a novel self-learning probability function without any prior knowledge and hyper-parameters to learn each view's individual distribution. Next, graph-context-aware refinement with path propagation and co-neighbor propagation is used to refine pairwise probability, which alleviates the impact of noise and outliers. Finally, SLS-MPC proposes a probabilistic clustering algorithm to adjust clustering assignments by maximizing the joint probability iteratively without category information. Extensive experiments on multiple benchmarks show that SLS-MPC outperforms previous state-of-the-art methods.
Read more8/19/2024
0
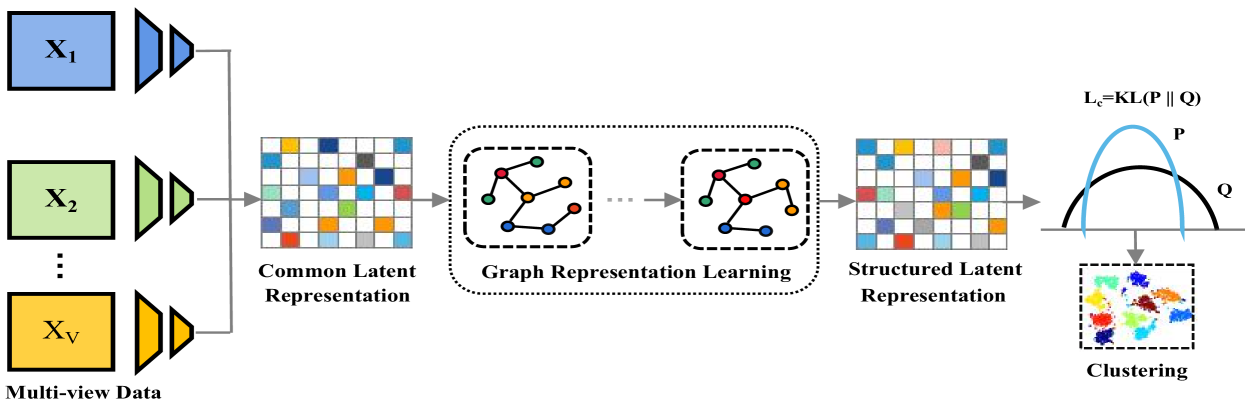
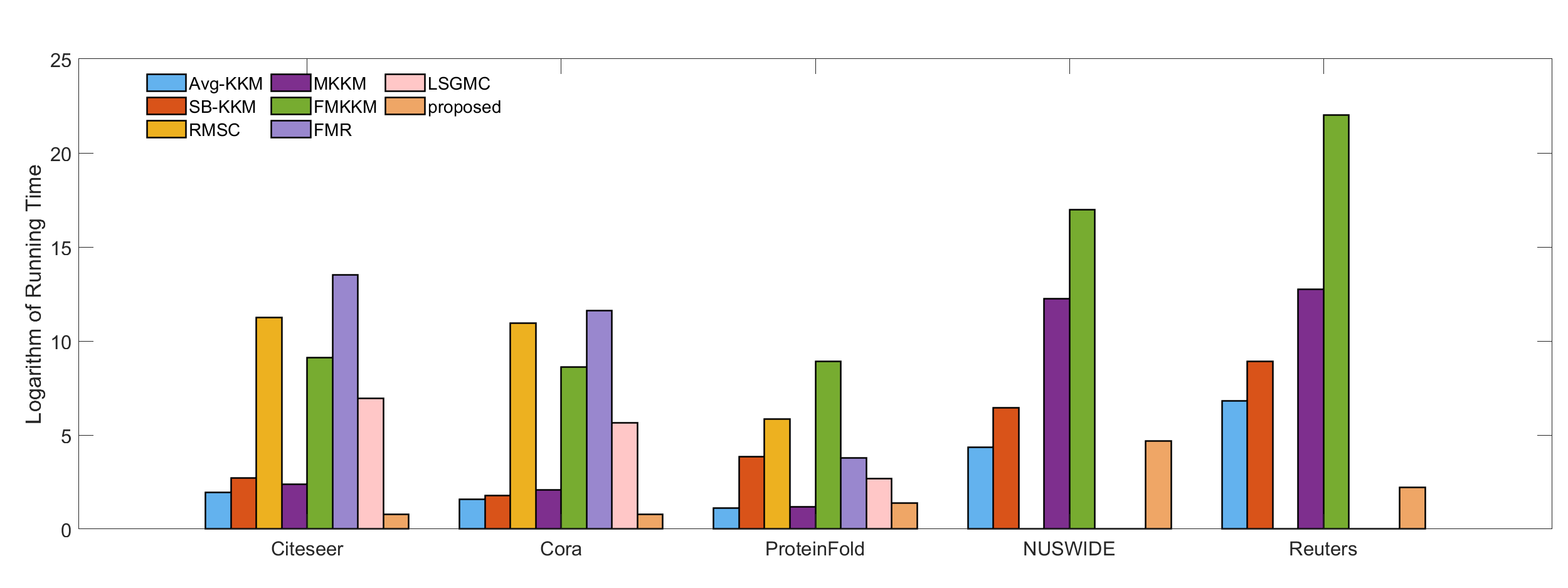
SLRL: Structured Latent Representation Learning for Multi-view Clustering
Zhangci Xiong, Meng Cao
In recent years, Multi-View Clustering (MVC) has attracted increasing attention for its potential to reduce the annotation burden associated with large datasets. The aim of MVC is to exploit the inherent consistency and complementarity among different views, thereby integrating information from multiple perspectives to improve clustering outcomes. Despite extensive research in MVC, most existing methods focus predominantly on harnessing complementary information across views to enhance clustering effectiveness, often neglecting the structural information among samples, which is crucial for exploring sample correlations. To address this gap, we introduce a novel framework, termed Structured Latent Representation Learning based Multi-View Clustering method (SLRL). SLRL leverages both the complementary and structural information. Initially, it learns a common latent representation for all views. Subsequently, to exploit the structural information among samples, a k-nearest neighbor graph is constructed from this common latent representation. This graph facilitates enhanced sample interaction through graph learning techniques, leading to a structured latent representation optimized for clustering. Extensive experiments demonstrate that SLRL not only competes well with existing methods but also sets new benchmarks in various multi-view datasets.
Read more7/12/2024
0
One-Step Late Fusion Multi-view Clustering with Compressed Subspace
Qiyuan Ou, Pei Zhang, Sihang Zhou, En Zhu
Late fusion multi-view clustering (LFMVC) has become a rapidly growing class of methods in the multi-view clustering (MVC) field, owing to its excellent computational speed and clustering performance. One bottleneck faced by existing late fusion methods is that they are usually aligned to the average kernel function, which makes the clustering performance highly dependent on the quality of datasets. Another problem is that they require subsequent k-means clustering after obtaining the consensus partition matrix to get the final discrete labels, and the resulting separation of the label learning and cluster structure optimization processes limits the integrity of these models. To address the above issues, we propose an integrated framework named One-Step Late Fusion Multi-view Clustering with Compressed Subspace (OS-LFMVC-CS). Specifically, we use the consensus subspace to align the partition matrix while optimizing the partition fusion, and utilize the fused partition matrix to guide the learning of discrete labels. A six-step iterative optimization approach with verified convergence is proposed. Sufficient experiments on multiple datasets validate the effectiveness and efficiency of our proposed method.
Read more5/29/2024

0
Multi-level Reliable Guidance for Unpaired Multi-view Clustering
Like Xin, Wanqi Yang, Lei Wang, Ming Yang
In this paper, we address the challenging problem of unpaired multi-view clustering (UMC), aiming to perform effective joint clustering using unpaired observed samples across multiple views. Commonly, traditional incomplete multi-view clustering (IMC) methods often depend on paired samples to capture complementary information between views. However, the strategy becomes impractical in UMC due to the absence of paired samples. Although some researchers have attempted to tackle the issue by preserving consistent cluster structures across views, they frequently neglect the confidence of these cluster structures, especially for boundary samples and uncertain cluster structures during the initial training. Therefore, we propose a method called Multi-level Reliable Guidance for UMC (MRG-UMC), which leverages multi-level clustering to aid in learning a trustworthy cluster structure across inner-view, cross-view, and common-view, respectively. Specifically, within each view, multi-level clustering fosters a trustworthy cluster structure across different levels and reduces clustering error. In cross-view learning, reliable view guidance enhances the confidence of the cluster structures in other views. Similarly, within the multi-level framework, the incorporation of a common view aids in aligning different views, thereby reducing the clustering error and uncertainty of cluster structure. Finally, as evidenced by extensive experiments, our method for UMC demonstrates significant efficiency improvements compared to 20 state-of-the-art methods.
Read more7/2/2024