SLRL: Structured Latent Representation Learning for Multi-view Clustering

0
Sign in to get full access
Overview
- This paper presents a novel approach called Structured Latent Representation Learning (SLRL) for multi-view clustering.
- SLRL learns a structured latent representation that captures the underlying relationships between different views of the data.
- The method leverages a k-nearest neighbor graph and graph representation learning to extract a unified latent representation.
- Experiments on several real-world datasets demonstrate the effectiveness of SLRL compared to other state-of-the-art multi-view clustering methods.
Plain English Explanation
When we have data that can be viewed from multiple perspectives or "views" (e.g., images with associated text captions), it can be helpful to find a unified way to represent that data that captures the relationships between the different views. SLRL: Structured Latent Representation Learning for Multi-view Clustering introduces a method called Structured Latent Representation Learning (SLRL) to do just that.
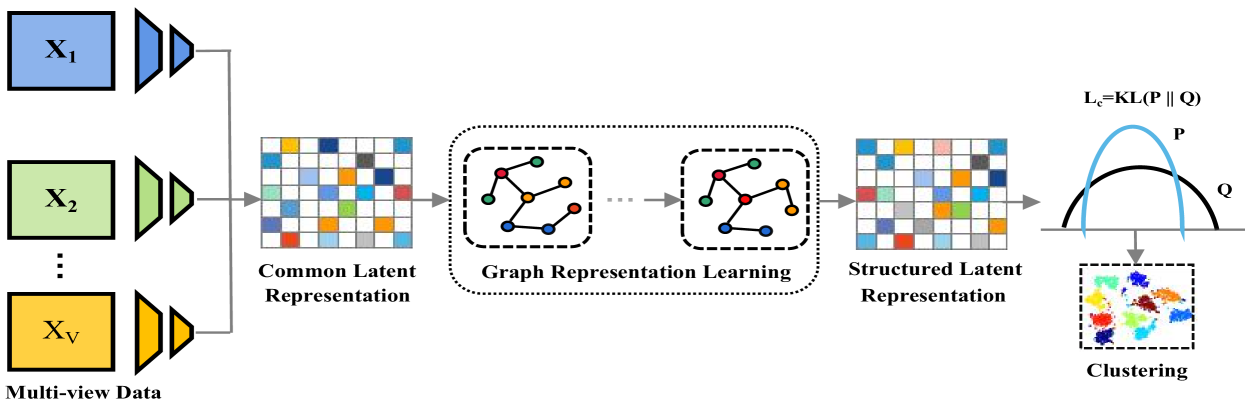
The key idea behind SLRL is to learn a structured latent representation of the data that reflects the underlying connections between the different views. To do this, the method first builds a k-nearest neighbor graph, which shows how the data points are related to their closest neighbors. It then uses graph representation learning techniques to extract a unified latent representation that captures those relationships.
By learning this structured latent representation, SLRL is able to perform multi-view clustering - grouping together data points that are similar across all of their views. The authors show that SLRL outperforms other state-of-the-art multi-view clustering methods on a variety of real-world datasets, demonstrating the power of this approach.
Technical Explanation
SLRL: Structured Latent Representation Learning for Multi-view Clustering introduces a novel framework called Structured Latent Representation Learning (SLRL) for multi-view clustering. The key idea is to learn a structured latent representation that captures the underlying relationships between different views of the data.
The method first constructs a k-nearest neighbor (k-NN) graph, which encodes the local neighborhood structure of the data points. It then applies graph representation learning techniques to extract a unified latent representation that reflects the connections between the different views. Specifically, SLRL uses a graph convolutional network (GCN) to learn the latent representation.
The authors formulate the optimization problem to jointly learn the latent representation and perform multi-view clustering. This is achieved by incorporating a clustering loss that encourages similar data points in the latent space to be assigned to the same cluster, while dissimilar points are assigned to different clusters.
Experiments on several real-world datasets, including Multi-View Multi-Representation Self-Supervised Learning (MV-MR-SSL), Learning Multi-View Molecular Representations: From Structured to Unstructured Data, and One-Step Late Fusion for Multi-view Clustering, demonstrate the effectiveness of SLRL compared to other state-of-the-art multi-view clustering methods.
Critical Analysis
The SLRL: Structured Latent Representation Learning for Multi-view Clustering paper presents a compelling approach to multi-view clustering, but it is important to consider some potential limitations and areas for further research.
One potential concern is the reliance on the k-nearest neighbor graph, which may be sensitive to the choice of the k parameter and could be affected by the curse of dimensionality in high-dimensional datasets. The authors acknowledge this issue and suggest exploring alternative graph construction methods in future work.
Additionally, the paper does not provide a deep analysis of the learned latent representations or the interpretability of the clustering results. Further research could investigate Interpretable Multi-view Clustering techniques to better understand the underlying structure captured by the SLRL model.
Finally, the experiments in the paper are conducted on relatively small-scale datasets, and it would be valuable to assess the scalability and performance of SLRL on larger, more complex real-world datasets. Exploring the robustness of the method to noise, missing data, or other challenging scenarios would also be a fruitful direction for future research.
Conclusion
SLRL: Structured Latent Representation Learning for Multi-view Clustering presents a novel approach to multi-view clustering that learns a structured latent representation to capture the underlying relationships between different views of the data. By leveraging a k-nearest neighbor graph and graph representation learning, the method is able to outperform other state-of-the-art multi-view clustering techniques on several real-world datasets.
While the paper demonstrates the potential of this approach, further research is needed to address the method's limitations and explore its broader applicability. Investigating alternative graph construction methods, interpretability of the learned representations, and scalability to larger datasets are all important directions for future work. Overall, the SLRL framework represents a promising step forward in the field of multi-view clustering and data integration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SLRL: Structured Latent Representation Learning for Multi-view Clustering
Zhangci Xiong, Meng Cao
In recent years, Multi-View Clustering (MVC) has attracted increasing attention for its potential to reduce the annotation burden associated with large datasets. The aim of MVC is to exploit the inherent consistency and complementarity among different views, thereby integrating information from multiple perspectives to improve clustering outcomes. Despite extensive research in MVC, most existing methods focus predominantly on harnessing complementary information across views to enhance clustering effectiveness, often neglecting the structural information among samples, which is crucial for exploring sample correlations. To address this gap, we introduce a novel framework, termed Structured Latent Representation Learning based Multi-View Clustering method (SLRL). SLRL leverages both the complementary and structural information. Initially, it learns a common latent representation for all views. Subsequently, to exploit the structural information among samples, a k-nearest neighbor graph is constructed from this common latent representation. This graph facilitates enhanced sample interaction through graph learning techniques, leading to a structured latent representation optimized for clustering. Extensive experiments demonstrate that SLRL not only competes well with existing methods but also sets new benchmarks in various multi-view datasets.
Read more7/12/2024
🔗
0
Self-Learning Symmetric Multi-view Probabilistic Clustering
Junjie Liu, Junlong Liu, Rongxin Jiang, Yaowu Chen, Chen Shen, Jieping Ye
Multi-view Clustering (MVC) has achieved significant progress, with many efforts dedicated to learn knowledge from multiple views. However, most existing methods are either not applicable or require additional steps for incomplete MVC. Such a limitation results in poor-quality clustering performance and poor missing view adaptation. Besides, noise or outliers might significantly degrade the overall clustering performance, which are not handled well by most existing methods. In this paper, we propose a novel unified framework for incomplete and complete MVC named self-learning symmetric multi-view probabilistic clustering (SLS-MPC). SLS-MPC proposes a novel symmetric multi-view probability estimation and equivalently transforms multi-view pairwise posterior matching probability into composition of each view's individual distribution, which tolerates data missing and might extend to any number of views. Then, SLS-MPC proposes a novel self-learning probability function without any prior knowledge and hyper-parameters to learn each view's individual distribution. Next, graph-context-aware refinement with path propagation and co-neighbor propagation is used to refine pairwise probability, which alleviates the impact of noise and outliers. Finally, SLS-MPC proposes a probabilistic clustering algorithm to adjust clustering assignments by maximizing the joint probability iteratively without category information. Extensive experiments on multiple benchmarks show that SLS-MPC outperforms previous state-of-the-art methods.
Read more8/19/2024
0
URRL-IMVC: Unified and Robust Representation Learning for Incomplete Multi-View Clustering
Ge Teng, Ting Mao, Chen Shen, Xiang Tian, Xuesong Liu, Yaowu Chen, Jieping Ye
Incomplete multi-view clustering (IMVC) aims to cluster multi-view data that are only partially available. This poses two main challenges: effectively leveraging multi-view information and mitigating the impact of missing views. Prevailing solutions employ cross-view contrastive learning and missing view recovery techniques. However, they either neglect valuable complementary information by focusing only on consensus between views or provide unreliable recovered views due to the absence of supervision. To address these limitations, we propose a novel Unified and Robust Representation Learning for Incomplete Multi-View Clustering (URRL-IMVC). URRL-IMVC directly learns a unified embedding that is robust to view missing conditions by integrating information from multiple views and neighboring samples. Firstly, to overcome the limitations of cross-view contrastive learning, URRL-IMVC incorporates an attention-based auto-encoder framework to fuse multi-view information and generate unified embeddings. Secondly, URRL-IMVC directly enhances the robustness of the unified embedding against view-missing conditions through KNN imputation and data augmentation techniques, eliminating the need for explicit missing view recovery. Finally, incremental improvements are introduced to further enhance the overall performance, such as the Clustering Module and the customization of the Encoder. We extensively evaluate the proposed URRL-IMVC framework on various benchmark datasets, demonstrating its state-of-the-art performance. Furthermore, comprehensive ablation studies are performed to validate the effectiveness of our design.
Read more7/15/2024

0
Enhanced Latent Multi-view Subspace Clustering
Long Shi, Lei Cao, Jun Wang, Badong Chen
Latent multi-view subspace clustering has been demonstrated to have desirable clustering performance. However, the original latent representation method vertically concatenates the data matrices from multiple views into a single matrix along the direction of dimensionality to recover the latent representation matrix, which may result in an incomplete information recovery. To fully recover the latent space representation, we in this paper propose an Enhanced Latent Multi-view Subspace Clustering (ELMSC) method. The ELMSC method involves constructing an augmented data matrix that enhances the representation of multi-view data. Specifically, we stack the data matrices from various views into the block-diagonal locations of the augmented matrix to exploit the complementary information. Meanwhile, the non-block-diagonal entries are composed based on the similarity between different views to capture the consistent information. In addition, we enforce a sparse regularization for the non-diagonal blocks of the augmented self-representation matrix to avoid redundant calculations of consistency information. Finally, a novel iterative algorithm based on the framework of Alternating Direction Method of Multipliers (ADMM) is developed to solve the optimization problem for ELMSC. Extensive experiments on real-world datasets demonstrate that our proposed ELMSC is able to achieve higher clustering performance than some state-of-art multi-view clustering methods.
Read more8/28/2024