Self-Supervised and Few-Shot Learning for Robust Bioaerosol Monitoring

0

Sign in to get full access
Overview
- This paper explores the use of self-supervised and few-shot learning techniques to improve the robustness of bioaerosol monitoring systems.
- The researchers developed a novel deep learning architecture that can effectively learn from limited labeled data, leveraging self-supervised pretraining and few-shot fine-tuning.
- The proposed approach was evaluated on real-world bioaerosol datasets, demonstrating improved performance and generalization compared to traditional supervised learning methods.
Plain English Explanation
Bioaerosol monitoring is crucial for detecting and responding to biological threats, such as the spread of infectious diseases or the release of harmful particles in the air. However, building reliable bioaerosol monitoring systems can be challenging, as they often require large amounts of labeled data for training machine learning models.
This paper presents a new approach that can learn to accurately classify bioaerosols using only a small amount of labeled data. The key idea is to first train the model using a self-supervised learning technique, which allows it to discover patterns and features in the data without needing labels. Then, the model is fine-tuned using a few labeled examples, a process known as few-shot learning.
By combining self-supervised pretraining and few-shot fine-tuning, the researchers were able to develop a model that can generalize well and make accurate predictions, even when only a small amount of labeled data is available. This is particularly useful in real-world scenarios, where collecting and labeling large bioaerosol datasets can be time-consuming and expensive.
The researchers tested their approach on several real-world bioaerosol datasets and found that it outperformed traditional supervised learning methods in terms of both accuracy and robustness. This suggests that their technique could be a valuable tool for building more effective and efficient bioaerosol monitoring systems, which could have important implications for public health, biosecurity, and environmental monitoring.
Technical Explanation
The paper presents a novel deep learning architecture that leverages self-supervised learning and few-shot learning techniques to improve the robustness of bioaerosol monitoring systems.
The proposed approach begins with a self-supervised pretraining stage, where the model is trained to learn useful representations from the bioaerosol data without the need for labeled examples. This is achieved by designing a self-supervised task, such as predicting the relative position of different particles in the input data. By learning to solve this pretext task, the model can discover important features and patterns in the data that are relevant for the ultimate classification objective.
After the self-supervised pretraining, the model is fine-tuned using a small number of labeled examples through a few-shot learning approach. This allows the model to adapt its learned representations to the specific classification task at hand, while leveraging the knowledge gained during the self-supervised stage.
The researchers evaluated their approach on multiple real-world bioaerosol datasets, comparing its performance to traditional supervised learning methods. The results showed that the combined self-supervised and few-shot learning strategy outperformed the baselines, demonstrating improved accuracy, generalization, and robustness to limited labeled data.
The key technical innovations in this paper include:
- A novel self-supervised pretraining objective tailored for bioaerosol data.
- A few-shot fine-tuning approach that effectively leverages the self-supervised representations.
- A comprehensive evaluation on challenging real-world bioaerosol datasets.
The success of this approach highlights the potential of self-supervised learning and few-shot learning techniques for building robust and data-efficient machine learning models in the bioaerosol monitoring domain.
Critical Analysis
The paper presents a well-designed and thorough study, with several strengths:
- The proposed approach of combining self-supervised pretraining and few-shot fine-tuning is a novel and promising solution for addressing the data scarcity challenge in bioaerosol monitoring.
- The evaluation on multiple real-world datasets provides a comprehensive assessment of the technique's performance and robustness.
- The technical details of the self-supervised pretraining and few-shot learning components are well-explained and could serve as a helpful reference for future research in this area.
However, the paper also has a few potential limitations:
- The specific self-supervised pretraining task used in the experiments may not be universally applicable, and further research is needed to explore alternative pretext tasks that could be more effective for different types of bioaerosol data.
- The paper does not provide a detailed analysis of the learned representations or the inner workings of the model, which could offer additional insights into the reasons for the observed performance improvements.
- While the results demonstrate the effectiveness of the proposed approach, the paper does not provide a direct comparison to other state-of-the-art few-shot learning or self-supervised learning techniques in the bioaerosol domain.
Future research could address these limitations by:
- Investigating a broader range of self-supervised pretraining objectives and their impact on the few-shot learning performance.
- Conducting a more in-depth analysis of the learned representations and their contribution to the model's generalization capabilities.
- Benchmarking the proposed approach against other recent few-shot learning and self-supervised learning methods in the bioaerosol monitoring field.
Overall, this paper presents a promising step towards more robust and data-efficient bioaerosol monitoring systems, and the techniques explored could have broader implications for other domains where labeled data is scarce.
Conclusion
This paper introduces a novel deep learning approach that combines self-supervised pretraining and few-shot fine-tuning to improve the robustness and performance of bioaerosol monitoring systems. By leveraging self-supervised learning to discover useful representations from unlabeled data and then fine-tuning the model with a small number of labeled examples, the researchers were able to develop a system that outperformed traditional supervised learning methods.
The success of this approach highlights the potential of self-supervised learning and few-shot learning techniques for building more efficient and effective machine learning models in the bioaerosol monitoring domain. This could have important implications for public health, biosecurity, and environmental monitoring, where reliable and data-efficient bioaerosol detection is crucial.
The paper provides a solid foundation for future research in this area, and the techniques explored could potentially be applied to other domains where labeled data is scarce. By continuing to push the boundaries of self-supervised and few-shot learning, researchers can develop more robust and adaptable machine learning solutions that can better address real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Supervised and Few-Shot Learning for Robust Bioaerosol Monitoring
Adrian Willi, Pascal Baumann, Sophie Erb, Fabian Groger, Yanick Zeder, Simone Lionetti
Real-time bioaerosol monitoring is improving the quality of life for people affected by allergies, but it often relies on deep-learning models which pose challenges for widespread adoption. These models are typically trained in a supervised fashion and require considerable effort to produce large amounts of annotated data, an effort that must be repeated for new particles, geographical regions, or measurement systems. In this work, we show that self-supervised learning and few-shot learning can be combined to classify holographic images of bioaerosol particles using a large collection of unlabelled data and only a few examples for each particle type. We first demonstrate that self-supervision on pictures of unidentified particles from ambient air measurements enhances identification even when labelled data is abundant. Most importantly, it greatly improves few-shot classification when only a handful of labelled images are available. Our findings suggest that real-time bioaerosol monitoring workflows can be substantially optimized, and the effort required to adapt models for different situations considerably reduced.
Read more6/17/2024
0
New!Self-supervised Learning for Acoustic Few-Shot Classification
Jingyong Liang, Bernd Meyer, Issac Ning Lee, Thanh-Toan Do
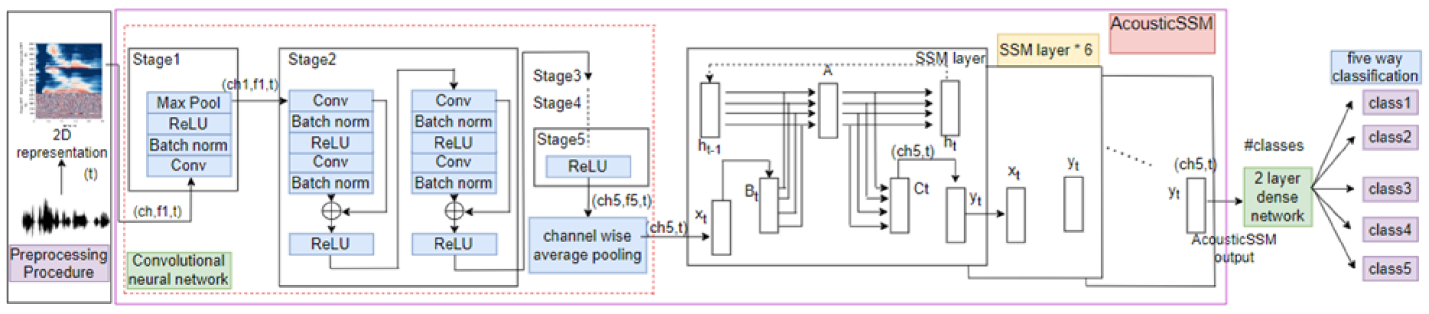
Labelled data are limited and self-supervised learning is one of the most important approaches for reducing labelling requirements. While it has been extensively explored in the image domain, it has so far not received the same amount of attention in the acoustic domain. Yet, reducing labelling is a key requirement for many acoustic applications. Specifically in bioacoustic, there are rarely sufficient labels for fully supervised learning available. This has led to the widespread use of acoustic recognisers that have been pre-trained on unrelated data for bioacoustic tasks. We posit that training on the actual task data and combining self-supervised pre-training with few-shot classification is a superior approach that has the ability to deliver high accuracy even when only a few labels are available. To this end, we introduce and evaluate a new architecture that combines CNN-based preprocessing with feature extraction based on state space models (SSMs). This combination is motivated by the fact that CNN-based networks alone struggle to capture temporal information effectively, which is crucial for classifying acoustic signals. SSMs, specifically S4 and Mamba, on the other hand, have been shown to have an excellent ability to capture long-range dependencies in sequence data. We pre-train this architecture using contrastive learning on the actual task data and subsequent fine-tuning with an extremely small amount of labelled data. We evaluate the performance of this proposed architecture for ($n$-shot, $n$-class) classification on standard benchmarks as well as real-world data. Our evaluation shows that it outperforms state-of-the-art architectures on the few-shot classification problem.
Read more9/17/2024

0
A Survey of Few-Shot Learning for Biomedical Time Series
Chenqi Li, Timothy Denison, Tingting Zhu
Advancements in wearable sensor technologies and the digitization of medical records have contributed to the unprecedented ubiquity of biomedical time series data. Data-driven models have tremendous potential to assist clinical diagnosis and improve patient care by improving long-term monitoring capabilities, facilitating early disease detection and intervention, as well as promoting personalized healthcare delivery. However, accessing extensively labeled datasets to train data-hungry deep learning models encounters many barriers, such as long-tail distribution of rare diseases, cost of annotation, privacy and security concerns, data-sharing regulations, and ethical considerations. An emerging approach to overcome the scarcity of labeled data is to augment AI methods with human-like capabilities to leverage past experiences to learn new tasks with limited examples, called few-shot learning. This survey provides a comprehensive review and comparison of few-shot learning methods for biomedical time series applications. The clinical benefits and limitations of such methods are discussed in relation to traditional data-driven approaches. This paper aims to provide insights into the current landscape of few-shot learning for biomedical time series and its implications for future research and applications.
Read more5/7/2024

0
Integration of Self-Supervised BYOL in Semi-Supervised Medical Image Recognition
Hao Feng, Yuanzhe Jia, Ruijia Xu, Mukesh Prasad, Ali Anaissi, Ali Braytee
Image recognition techniques heavily rely on abundant labeled data, particularly in medical contexts. Addressing the challenges associated with obtaining labeled data has led to the prominence of self-supervised learning and semi-supervised learning, especially in scenarios with limited annotated data. In this paper, we proposed an innovative approach by integrating self-supervised learning into semi-supervised models to enhance medical image recognition. Our methodology commences with pre-training on unlabeled data utilizing the BYOL method. Subsequently, we merge pseudo-labeled and labeled datasets to construct a neural network classifier, refining it through iterative fine-tuning. Experimental results on three different datasets demonstrate that our approach optimally leverages unlabeled data, outperforming existing methods in terms of accuracy for medical image recognition.
Read more4/17/2024