Self-supervised Learning for Acoustic Few-Shot Classification

0
Sign in to get full access
Overview
- This paper explores using self-supervised learning to improve few-shot acoustic classification, where the goal is to accurately classify audio samples with very few labeled examples.
- The key idea is to use self-supervised learning to pre-train a model on a large unlabeled audio dataset, then fine-tune it on the few-shot classification task.
- The authors evaluate their approach on several bioacoustic classification datasets and show significant performance improvements over traditional few-shot learning methods.
Plain English Explanation
In many real-world audio classification problems, such as identifying different animal species by their calls, we often have access to a large amount of unlabeled audio data but only a small number of labeled examples. Self-supervised learning can be used to take advantage of this unlabeled data and learn useful audio representations that can then be fine-tuned for the specific few-shot classification task at hand.
The key idea is to train a neural network model on a self-supervised task, like predicting the temporal relationship between different segments of an audio clip. This allows the model to learn general audio features without any labeled data. The authors then take this pre-trained model and fine-tune it on the few-shot classification dataset, which only has a small number of labeled examples.
By leveraging the self-supervised pre-training, the model is able to achieve much better few-shot classification performance compared to traditional methods that don't use any unlabeled data. The authors demonstrate this on several bioacoustic classification datasets, where the goal is to identify different animal species from their recorded calls.
Technical Explanation
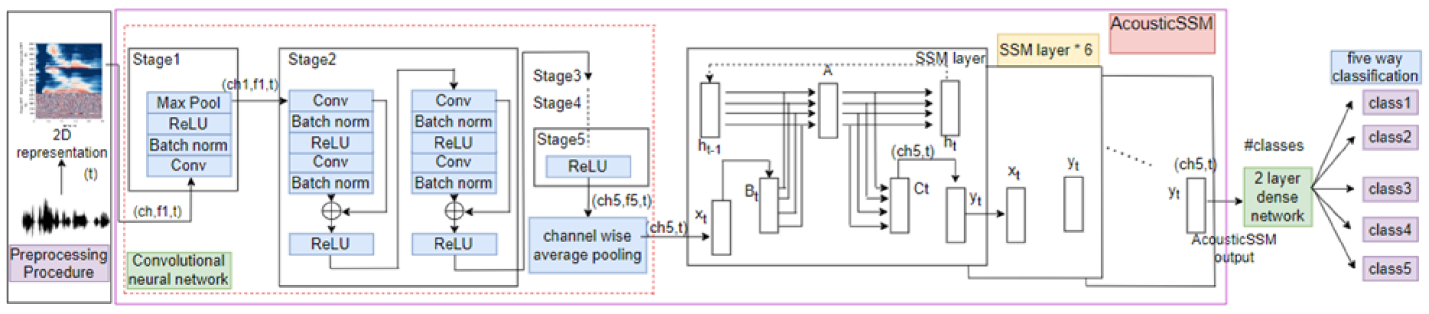
The authors propose an acoustic self-supervised model (Acoustic SSM) for few-shot classification. The core idea is to use self-supervised pre-training on a large unlabeled audio dataset to learn useful audio representations, and then fine-tune this pre-trained model on the few-shot classification task.
For the self-supervised pre-training, the authors use a contrastive objective that predicts the temporal relationship between different segments of an audio clip. Specifically, the model takes an audio clip as input and predicts whether pairs of segments are temporally adjacent or not. This allows the model to learn general audio features without any labeled data.
The authors then fine-tune this pre-trained model on the few-shot classification datasets. For the classification task, the model takes an audio clip as input and outputs a probability distribution over the target classes. During training, the model is optimized to correctly classify the few labeled examples.
The authors evaluate their Acoustic SSM approach on several bioacoustic classification datasets, including bird, frog, and insect call recordings. They show that Acoustic SSM significantly outperforms traditional few-shot learning methods, such as prototypical networks and matching networks, by leveraging the self-supervised pre-training.
Critical Analysis
The key strength of this work is the effective use of self-supervised learning to improve the performance of few-shot acoustic classification. By pre-training on unlabeled audio data, the model is able to learn useful audio representations that can then be efficiently fine-tuned on the few-shot tasks.
However, the paper does not explore the broader applicability of the Acoustic SSM approach beyond the bioacoustic domains studied. It would be interesting to see how well the self-supervised pre-training generalizes to other audio classification tasks, such as speech recognition or music analysis.
Additionally, the paper does not provide much insight into the specific audio features learned during the self-supervised pre-training stage. Further analysis of the learned representations could shed light on what types of audio patterns are most informative for few-shot classification.
Overall, this work demonstrates the promising potential of self-supervised learning for few-shot audio classification, but there is still room for further research to fully understand the capabilities and limitations of this approach.
Conclusion
This paper presents a novel approach for few-shot acoustic classification that leverages self-supervised learning. By pre-training a model on a large unlabeled audio dataset, the authors are able to learn useful audio representations that can be efficiently fine-tuned on few-shot classification tasks.
The results show significant performance improvements over traditional few-shot learning methods, particularly in the context of bioacoustic classification. This highlights the power of self-supervised learning for tackling data-efficient audio recognition problems, which have important applications in fields like ecology and conservation.
While the paper focuses on bioacoustic domains, the general principles could be extended to other audio classification tasks. Further research into the specific audio features learned during self-supervised pre-training could also yield valuable insights for the broader field of audio representation learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Self-supervised Learning for Acoustic Few-Shot Classification
Jingyong Liang, Bernd Meyer, Issac Ning Lee, Thanh-Toan Do
Labelled data are limited and self-supervised learning is one of the most important approaches for reducing labelling requirements. While it has been extensively explored in the image domain, it has so far not received the same amount of attention in the acoustic domain. Yet, reducing labelling is a key requirement for many acoustic applications. Specifically in bioacoustic, there are rarely sufficient labels for fully supervised learning available. This has led to the widespread use of acoustic recognisers that have been pre-trained on unrelated data for bioacoustic tasks. We posit that training on the actual task data and combining self-supervised pre-training with few-shot classification is a superior approach that has the ability to deliver high accuracy even when only a few labels are available. To this end, we introduce and evaluate a new architecture that combines CNN-based preprocessing with feature extraction based on state space models (SSMs). This combination is motivated by the fact that CNN-based networks alone struggle to capture temporal information effectively, which is crucial for classifying acoustic signals. SSMs, specifically S4 and Mamba, on the other hand, have been shown to have an excellent ability to capture long-range dependencies in sequence data. We pre-train this architecture using contrastive learning on the actual task data and subsequent fine-tuning with an extremely small amount of labelled data. We evaluate the performance of this proposed architecture for ($n$-shot, $n$-class) classification on standard benchmarks as well as real-world data. Our evaluation shows that it outperforms state-of-the-art architectures on the few-shot classification problem.
Read more9/17/2024

0
Leveraging Self-supervised Audio Representations for Data-Efficient Acoustic Scene Classification
Yiqiang Cai, Shengchen Li, Xi Shao
Acoustic scene classification (ASC) predominantly relies on supervised approaches. However, acquiring labeled data for training ASC models is often costly and time-consuming. Recently, self-supervised learning (SSL) has emerged as a powerful method for extracting features from unlabeled audio data, benefiting many downstream audio tasks. This paper proposes a data-efficient and low-complexity ASC system by leveraging self-supervised audio representations extracted from general-purpose audio datasets. We introduce BEATs, an audio SSL pre-trained model, to extract the general representations from AudioSet. Through extensive experiments, it has been demonstrated that the self-supervised audio representations can help to achieve high ASC accuracy with limited labeled fine-tuning data. Furthermore, we find that ensembling the SSL models fine-tuned with different strategies contributes to a further performance improvement. To meet low-complexity requirements, we use knowledge distillation to transfer the self-supervised knowledge from large teacher models to an efficient student model. The experimental results suggest that the self-supervised teachers effectively improve the classification accuracy of the student model. Our best-performing system obtains an average accuracy of 56.7%.
Read more8/28/2024

0
Self-Supervised and Few-Shot Learning for Robust Bioaerosol Monitoring
Adrian Willi, Pascal Baumann, Sophie Erb, Fabian Groger, Yanick Zeder, Simone Lionetti
Real-time bioaerosol monitoring is improving the quality of life for people affected by allergies, but it often relies on deep-learning models which pose challenges for widespread adoption. These models are typically trained in a supervised fashion and require considerable effort to produce large amounts of annotated data, an effort that must be repeated for new particles, geographical regions, or measurement systems. In this work, we show that self-supervised learning and few-shot learning can be combined to classify holographic images of bioaerosol particles using a large collection of unlabelled data and only a few examples for each particle type. We first demonstrate that self-supervision on pictures of unidentified particles from ambient air measurements enhances identification even when labelled data is abundant. Most importantly, it greatly improves few-shot classification when only a handful of labelled images are available. Our findings suggest that real-time bioaerosol monitoring workflows can be substantially optimized, and the effort required to adapt models for different situations considerably reduced.
Read more6/17/2024
0
Music auto-tagging in the long tail: A few-shot approach
T. Aleksandra Ma, Alexander Lerch
In the realm of digital music, using tags to efficiently organize and retrieve music from extensive databases is crucial for music catalog owners. Human tagging by experts is labor-intensive but mostly accurate, whereas automatic tagging through supervised learning has approached satisfying accuracy but is restricted to a predefined set of training tags. Few-shot learning offers a viable solution to expand beyond this small set of predefined tags by enabling models to learn from only a few human-provided examples to understand tag meanings and subsequently apply these tags autonomously. We propose to integrate few-shot learning methodology into multi-label music auto-tagging by using features from pre-trained models as inputs to a lightweight linear classifier, also known as a linear probe. We investigate different popular pre-trained features, as well as different few-shot parametrizations with varying numbers of classes and samples per class. Our experiments demonstrate that a simple model with pre-trained features can achieve performance close to state-of-the-art models while using significantly less training data, such as 20 samples per tag. Additionally, our linear probe performs competitively with leading models when trained on the entire training dataset. The results show that this transfer learning-based few-shot approach could effectively address the issue of automatically assigning long-tail tags with only limited labeled data.
Read more9/18/2024