Self-Supervised Learning for Medical Image Data with Anatomy-Oriented Imaging Planes

0
Sign in to get full access
Overview
- This paper presents a self-supervised learning approach for medical image data using anatomy-oriented imaging planes.
- The method leverages the inherent structure of medical images to learn useful representations without requiring manual annotations.
- The authors demonstrate the effectiveness of their approach on various medical imaging tasks, including image classification and segmentation.
Plain English Explanation
In the field of medical imaging, researchers often rely on manual annotations from experts to train machine learning models. However, this process can be time-consuming and expensive. To address this challenge, the authors of this paper have developed a self-supervised learning approach that can learn useful representations from medical image data without the need for manual annotations.
The key idea behind their approach is to exploit the inherent structure of medical images, such as the specific anatomical planes (e.g., axial, coronal, sagittal) in which they are typically acquired. By training the model to recognize and reason about these anatomical planes, the authors show that the learned representations can be effectively transferred to a variety of medical imaging tasks, including classification and segmentation.
The bootstrapping chest CT image understanding by distilling and clinical-oriented multi-level contrastive learning method papers present similar self-supervised learning approaches for medical imaging data, demonstrating the importance of this research direction.
Technical Explanation
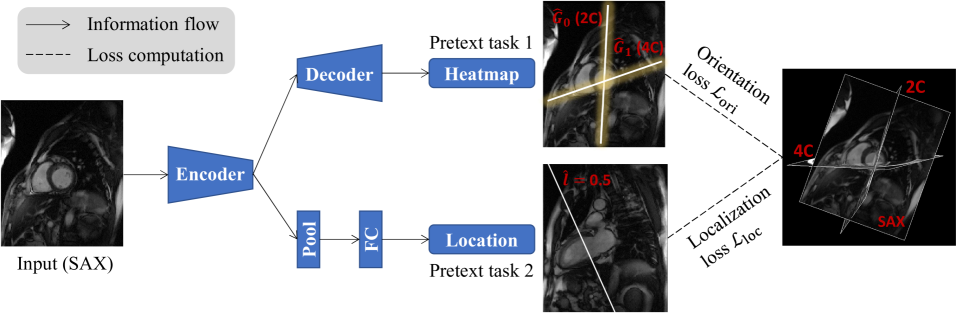
The authors propose a self-supervised learning framework that leverages the inherent structure of medical images, specifically the anatomical planes in which they are typically acquired. Their approach involves training a neural network to recognize and reason about these anatomical planes, which serves as a pretext task for learning useful representations.
The network architecture consists of a backbone encoder that takes a medical image as input and produces a feature representation. This feature representation is then passed through a multi-head prediction module, where each head is responsible for predicting the orientation of the input image with respect to a specific anatomical plane (e.g., axial, coronal, sagittal).
During training, the model is optimized to minimize the classification loss associated with correctly identifying the anatomical plane of each input image. The authors show that the learned representations can be effectively transferred to various medical imaging tasks, such as image classification and segmentation, outperforming models trained from scratch or with standard transfer learning approaches.
The authors also demonstrate the ability of their method to train like a medical resident, leveraging the prior knowledge and context inherent in medical image data to improve the learning process.
Critical Analysis
The authors present a compelling approach to leveraging the inherent structure of medical images for self-supervised learning. Their use of anatomical plane prediction as a pretext task is a clever way to capture the underlying spatial and contextual information in medical data without relying on manual annotations.
One potential limitation of the study is the lack of a detailed analysis of the learned representations. While the authors demonstrate the effectiveness of their approach on various downstream tasks, a deeper exploration of the specific features and patterns learned by the model could provide additional insights into the mechanism behind the performance improvements.
Additionally, the authors do not discuss the scalability of their approach to larger and more diverse medical imaging datasets. As the size and complexity of the data grow, the ability of the model to generalize and maintain its performance may become an important consideration.
Further research could also explore the integration of domain-specific knowledge, such as clinical-oriented multi-level contrastive learning, to further enhance the learned representations and improve the model's performance on clinically relevant tasks.
Conclusion
This paper presents a novel self-supervised learning approach for medical image data that leverages the inherent structure of anatomical imaging planes. By training the model to recognize and reason about these planes, the authors demonstrate the ability to learn useful representations that can be effectively transferred to a variety of medical imaging tasks.
The proposed method offers a promising avenue for reducing the reliance on manual annotations in medical imaging, which can be time-consuming and expensive. The authors' work highlights the potential of self-supervised learning techniques to unlock the value of large-scale medical image datasets and advance the field of medical image analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Supervised Learning for Medical Image Data with Anatomy-Oriented Imaging Planes
Tianwei Zhang, Dong Wei, Mengmeng Zhu, Shi Gu, Yefeng Zheng
Self-supervised learning has emerged as a powerful tool for pretraining deep networks on unlabeled data, prior to transfer learning of target tasks with limited annotation. The relevance between the pretraining pretext and target tasks is crucial to the success of transfer learning. Various pretext tasks have been proposed to utilize properties of medical image data (e.g., three dimensionality), which are more relevant to medical image analysis than generic ones for natural images. However, previous work rarely paid attention to data with anatomy-oriented imaging planes, e.g., standard cardiac magnetic resonance imaging views. As these imaging planes are defined according to the anatomy of the imaged organ, pretext tasks effectively exploiting this information can pretrain the networks to gain knowledge on the organ of interest. In this work, we propose two complementary pretext tasks for this group of medical image data based on the spatial relationship of the imaging planes. The first is to learn the relative orientation between the imaging planes and implemented as regressing their intersecting lines. The second exploits parallel imaging planes to regress their relative slice locations within a stack. Both pretext tasks are conceptually straightforward and easy to implement, and can be combined in multitask learning for better representation learning. Thorough experiments on two anatomical structures (heart and knee) and representative target tasks (semantic segmentation and classification) demonstrate that the proposed pretext tasks are effective in pretraining deep networks for remarkably boosted performance on the target tasks, and superior to other recent approaches.
Read more4/9/2024

0
Self-Supervised Alignment Learning for Medical Image Segmentation
Haofeng Li, Yiming Ouyang, Xiang Wan
Recently, self-supervised learning (SSL) methods have been used in pre-training the segmentation models for 2D and 3D medical images. Most of these methods are based on reconstruction, contrastive learning and consistency regularization. However, the spatial correspondence of 2D slices from a 3D medical image has not been fully exploited. In this paper, we propose a novel self-supervised alignment learning framework to pre-train the neural network for medical image segmentation. The proposed framework consists of a new local alignment loss and a global positional loss. We observe that in the same 3D scan, two close 2D slices usually contain similar anatomic structures. Thus, the local alignment loss is proposed to make the pixel-level features of matched structures close to each other. Experimental results show that the proposed alignment learning is competitive with existing self-supervised pre-training approaches on CT and MRI datasets, under the setting of limited annotations.
Read more6/26/2024

0
MedMAE: A Self-Supervised Backbone for Medical Imaging Tasks
Anubhav Gupta, Islam Osman, Mohamed S. Shehata, John W. Braun
Medical imaging tasks are very challenging due to the lack of publicly available labeled datasets. Hence, it is difficult to achieve high performance with existing deep-learning models as they require a massive labeled dataset to be trained effectively. An alternative solution is to use pre-trained models and fine-tune them using the medical imaging dataset. However, all existing models are pre-trained using natural images, which is a completely different domain from that of medical imaging, which leads to poor performance due to domain shift. To overcome these problems, we propose a large-scale unlabeled dataset of medical images and a backbone pre-trained using the proposed dataset with a self-supervised learning technique called Masked autoencoder. This backbone can be used as a pre-trained model for any medical imaging task, as it is trained to learn a visual representation of different types of medical images. To evaluate the performance of the proposed backbone, we used four different medical imaging tasks. The results are compared with existing pre-trained models. These experiments show the superiority of our proposed backbone in medical imaging tasks.
Read more7/23/2024

0
Structure-aware World Model for Probe Guidance via Large-scale Self-supervised Pre-train
Haojun Jiang, Meng Li, Zhenguo Sun, Ning Jia, Yu Sun, Shaqi Luo, Shiji Song, Gao Huang
The complex structure of the heart leads to significant challenges in echocardiography, especially in acquisition cardiac ultrasound images. Successful echocardiography requires a thorough understanding of the structures on the two-dimensional plane and the spatial relationships between planes in three-dimensional space. In this paper, we innovatively propose a large-scale self-supervised pre-training method to acquire a cardiac structure-aware world model. The core innovation lies in constructing a self-supervised task that requires structural inference by predicting masked structures on a 2D plane and imagining another plane based on pose transformation in 3D space. To support large-scale pre-training, we collected over 1.36 million echocardiograms from ten standard views, along with their 3D spatial poses. In the downstream probe guidance task, we demonstrate that our pre-trained model consistently reduces guidance errors across the ten most common standard views on the test set with 0.29 million samples from 74 routine clinical scans, indicating that structure-aware pre-training benefits the scanning.
Read more7/22/2024