Self-supervised Preference Optimization: Enhance Your Language Model with Preference Degree Awareness

0
Sign in to get full access
Overview
- Introduces "self-supervised preference optimization" to enhance language models with preference degree awareness
- Proposes a method to train language models to generate content that aligns with user preferences
- Aims to improve language model performance on tasks that require understanding and expressing user preferences
Plain English Explanation
One of the key challenges in developing advanced language models is ensuring they can accurately capture and express human preferences. The paper "Self-supervised Preference Optimization: Enhance Your Language Model with Preference Degree Awareness" proposes a new approach called "self-supervised preference optimization" to address this issue.
The core idea is to train language models not just to generate grammatically correct text, but to do so in a way that aligns with user preferences. This could be useful for applications like content creation, personal assistants, or interactive systems where the model needs to understand and generate content that matches the user's tastes and priorities.
The method works by having the model learn to predict the "preference degree" of different text outputs - that is, how much the user would like or dislike that content. The model is then trained to generate text that maximizes this predicted preference score, creating content that should be more tailored to the user's preferences.
By incorporating this preference awareness into the language model, the researchers aim to improve its performance on tasks that require understanding and expressing user preferences, beyond just general language understanding and generation.
Technical Explanation
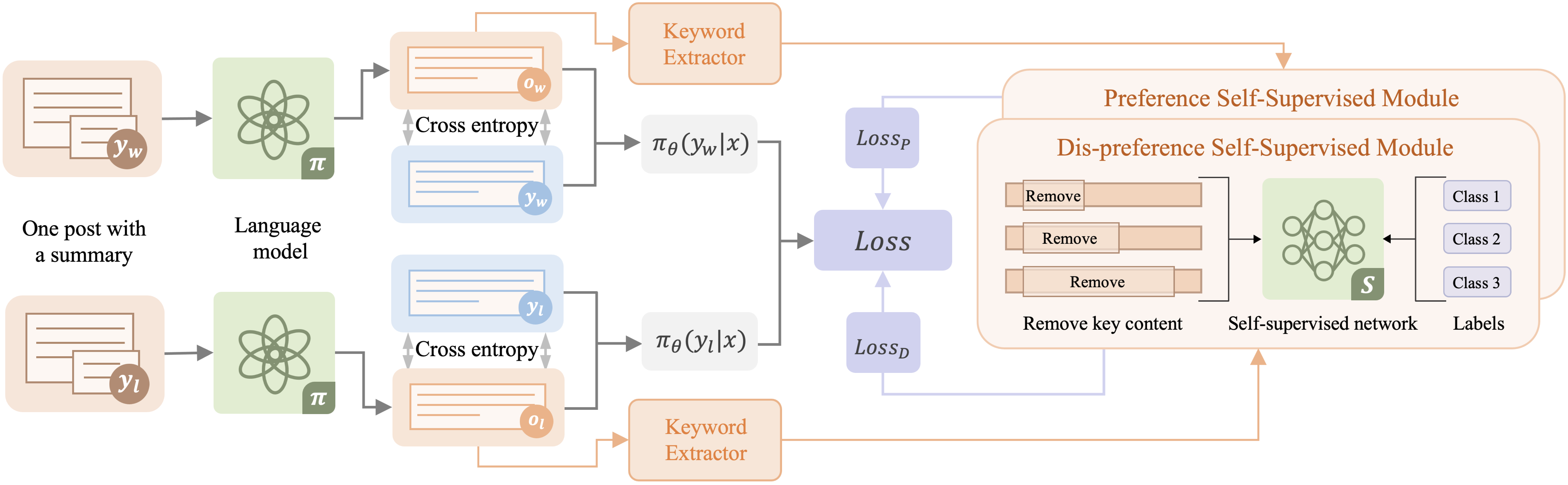
The paper introduces a "self-supervised preference optimization" training approach for language models. The key idea is to have the model learn to predict a "preference degree" score for each generated text output, and then use that score to guide the model towards generating more preferred content.
Specifically, the model is trained on two parallel tasks:
- Standard language modeling, predicting the next token in a sequence.
- Predicting the preference degree of the generated text, on a scale from dislike to like.
The preference degree prediction is trained on a dataset of human-annotated text, where the preference score for each example is provided. The language model is then trained to maximize this preference score, in addition to minimizing the standard language modeling loss.
The researchers experiment with different architectures for modeling the preference degree, including a separate "preference head" and integrating the preference prediction directly into the language model. They also explore ways to balance the preference optimization with the standard language modeling objective.
Through extensive experiments, the authors demonstrate that this self-supervised preference optimization approach leads to significant improvements in the language model's ability to generate content aligned with user preferences, compared to standard language models. They also show benefits on downstream tasks that require understanding and expressing preferences.
Critical Analysis
The "self-supervised preference optimization" approach proposed in this paper is a novel and promising direction for enhancing language models. By explicitly training the model to understand and generate content that aligns with user preferences, it addresses an important limitation of standard language models.
However, the paper does acknowledge some potential limitations and areas for further research:
- The preference degree annotations used for training may be noisy or biased, which could impact the model's performance.
- There are open questions around how to best balance the preference optimization objective with standard language modeling, to avoid sacrificing general language capabilities.
- The approach has been evaluated on limited preference-related tasks, and its broader applicability and real-world impact remain to be seen.
Additionally, one could raise further questions about the ethical implications of optimizing language models for user preferences. There are risks around amplifying individual biases, creating "filter bubbles," or generating content that manipulates user preferences. Careful consideration of these societal impacts will be crucial as this technology develops.
Conclusion
The "self-supervised preference optimization" method introduced in this paper represents an important step forward in enhancing language models to better understand and express human preferences. By training the model to predict and optimize for user preference scores, it can generate content that is more tailored to individual tastes and priorities.
This capability could have significant implications for a wide range of applications, from content creation and personal assistants to interactive systems and beyond. As the authors note, further research is needed to fully realize the potential of this approach and address potential limitations and ethical concerns.
Overall, this paper presents a novel and promising direction for the field of natural language processing, with the potential to create language models that are more personalized, relevant, and aligned with user preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Self-supervised Preference Optimization: Enhance Your Language Model with Preference Degree Awareness
Jian Li, Haojing Huang, Yujia Zhang, Pengfei Xu, Xi Chen, Rui Song, Lida Shi, Jingwen Wang, Hao Xu
Recently, there has been significant interest in replacing the reward model in Reinforcement Learning with Human Feedback (RLHF) methods for Large Language Models (LLMs), such as Direct Preference Optimization (DPO) and its variants. These approaches commonly use a binary cross-entropy mechanism on pairwise samples, i.e., minimizing and maximizing the loss based on preferred or dis-preferred responses, respectively. However, while this training strategy omits the reward model, it also overlooks the varying preference degrees within different responses. We hypothesize that this is a key factor hindering LLMs from sufficiently understanding human preferences. To address this problem, we propose a novel Self-supervised Preference Optimization (SPO) framework, which constructs a self-supervised preference degree loss combined with the alignment loss, thereby helping LLMs improve their ability to understand the degree of preference. Extensive experiments are conducted on two widely used datasets of different tasks. The results demonstrate that SPO can be seamlessly integrated with existing preference optimization methods and significantly boost their performance to achieve state-of-the-art performance. We also conduct detailed analyses to offer comprehensive insights into SPO, which verifies its effectiveness. The code is available at https://github.com/lijian16/SPO.
Read more9/27/2024
💬
4
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea Finn
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
Read more7/31/2024

0
New Desiderata for Direct Preference Optimization
Xiangkun Hu, Tong He, David Wipf
Large language models in the past have typically relied on some form of reinforcement learning with human feedback (RLHF) to better align model responses with human preferences. However, because of oft-observed instabilities when implementing these RLHF pipelines, various reparameterization techniques have recently been introduced to sidestep the need for separately learning an RL reward model. Instead, directly fine-tuning for human preferences is achieved via the minimization of a single closed-form training objective, a process originally referred to as direct preference optimization (DPO) and followed by several notable descendants. Although effective in certain real-world settings, we introduce new evaluation criteria that serve to highlight unresolved shortcomings in the ability of existing DPO methods to interpolate between a pre-trained reference model and empirical measures of human preferences, as well as unavoidable trade-offs in how low- and high-quality responses are regularized and constraints are handled. Our insights then motivate an alternative DPO-like loss that provably mitigates these limitations. Empirical results serve to corroborate notable aspects of our analyses.
Read more7/15/2024
0
Soft Preference Optimization: Aligning Language Models to Expert Distributions
Arsalan Sharifnassab, Sina Ghiassian, Saber Salehkaleybar, Surya Kanoria, Dale Schuurmans
We propose Soft Preference Optimization (SPO), a method for aligning generative models, such as Large Language Models (LLMs), with human preferences, without the need for a reward model. SPO optimizes model outputs directly over a preference dataset through a natural loss function that integrates preference loss with a regularization term across the model's entire output distribution rather than limiting it to the preference dataset. Although SPO does not require the assumption of an existing underlying reward model, we demonstrate that, under the Bradley-Terry (BT) model assumption, it converges to a softmax of scaled rewards, with the distribution's softness adjustable via the softmax exponent, an algorithm parameter. We showcase SPO's methodology, its theoretical foundation, and its comparative advantages in simplicity, computational efficiency, and alignment precision.
Read more5/29/2024