Soft Preference Optimization: Aligning Language Models to Expert Distributions

0
Sign in to get full access
Overview
- This paper proposes a novel approach called "Soft Preference Optimization" to align large language models with expert distributions.
- The researchers aim to train language models that produce outputs matching the preferences of domain experts, rather than just maximizing likelihood on a dataset.
- The paper explores several techniques for this, including token-level direct preference optimization, self-play preference optimization, and provably robust direct preference optimization.
Plain English Explanation
The researchers want to train language models - AI systems that can generate human-like text - in a way that makes their outputs match what domain experts (people with specialized knowledge) would prefer, rather than just optimizing for generating text that is statistically similar to a dataset.
For example, perhaps a medical expert would prefer a language model to generate text about treatments that are grounded in the latest scientific evidence, rather than just generating plausible-sounding text about treatments. Or an ethics expert might want a language model to generate text that aligns with moral principles, not just text that sounds natural.
The key idea is to shift the training process to directly optimize for the preferences of these expert users, rather than just the overall statistical properties of the training data. The paper explores several technical approaches to achieve this, such as token-level direct preference optimization, where the model is trained to predict the experts' preferred token at each step, and self-play preference optimization, where the model plays a game against itself to learn the expert preferences.
By aligning language models with expert preferences, the researchers hope to create AI systems that are more reliable, trustworthy, and beneficial to society, rather than just optimizing for generic text generation.
Technical Explanation
The paper presents several techniques for "Soft Preference Optimization" to align language models with expert distributions:
-
Token-level direct preference optimization: The model is trained to predict the expert's preferred token at each step, in addition to maximizing the overall likelihood of the text.
-
Self-play preference optimization: The model plays a game against itself, where one version acts as the "expert" providing feedback to the other version, which then tries to align its outputs to match the expert's preferences.
-
Provably robust direct preference optimization: The researchers develop a method to align the language model with expert preferences even in the presence of noisy or imperfect feedback from the experts.
The paper also explores techniques for regularizing self-play language models to improve their performance and methods for enabling "weak-to-strong" extrapolation to accelerate the alignment process.
Through extensive experiments, the researchers demonstrate that these techniques can effectively align language models with expert preferences, resulting in outputs that are more reliable, trustworthy, and beneficial compared to models trained solely on maximizing likelihood.
Critical Analysis
The paper presents a compelling approach to aligning language models with expert preferences, which is an important step towards developing AI systems that are more reliable and beneficial to society. However, the researchers acknowledge several limitations and potential areas for further research:
-
The effectiveness of the approach may depend on the quality and consistency of the expert feedback provided during training. Obtaining high-quality expert input at scale could be challenging in practice.
-
The paper primarily focuses on textual outputs, but aligning language models with expert preferences for other modalities, such as image or video generation, may require additional research.
-
The long-term implications of deploying language models aligned with expert preferences are not fully explored. There may be concerns around the centralization of power and the potential for misuse by those in control of the expert feedback.
-
The paper does not address potential issues around the representativeness and diversity of the experts involved, which could lead to biases or the exclusion of certain perspectives.
Further research is needed to address these challenges and explore the broader societal implications of this approach to language model alignment.
Conclusion
This paper presents a novel approach called "Soft Preference Optimization" to align large language models with the preferences of domain experts, rather than just optimizing for maximum likelihood on a dataset. By training the models to directly match expert preferences, the researchers aim to create AI systems that are more reliable, trustworthy, and beneficial to society.
The paper explores several technical approaches, including token-level direct preference optimization, self-play preference optimization, and provably robust direct preference optimization, and demonstrates their effectiveness through extensive experiments.
While the proposed techniques represent an important step forward, the researchers acknowledge several limitations and areas for further research, such as the challenges of obtaining high-quality expert feedback at scale and the potential broader societal implications of this approach. Continued work in this area could lead to the development of more responsible and beneficial AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Soft Preference Optimization: Aligning Language Models to Expert Distributions
Arsalan Sharifnassab, Sina Ghiassian, Saber Salehkaleybar, Surya Kanoria, Dale Schuurmans
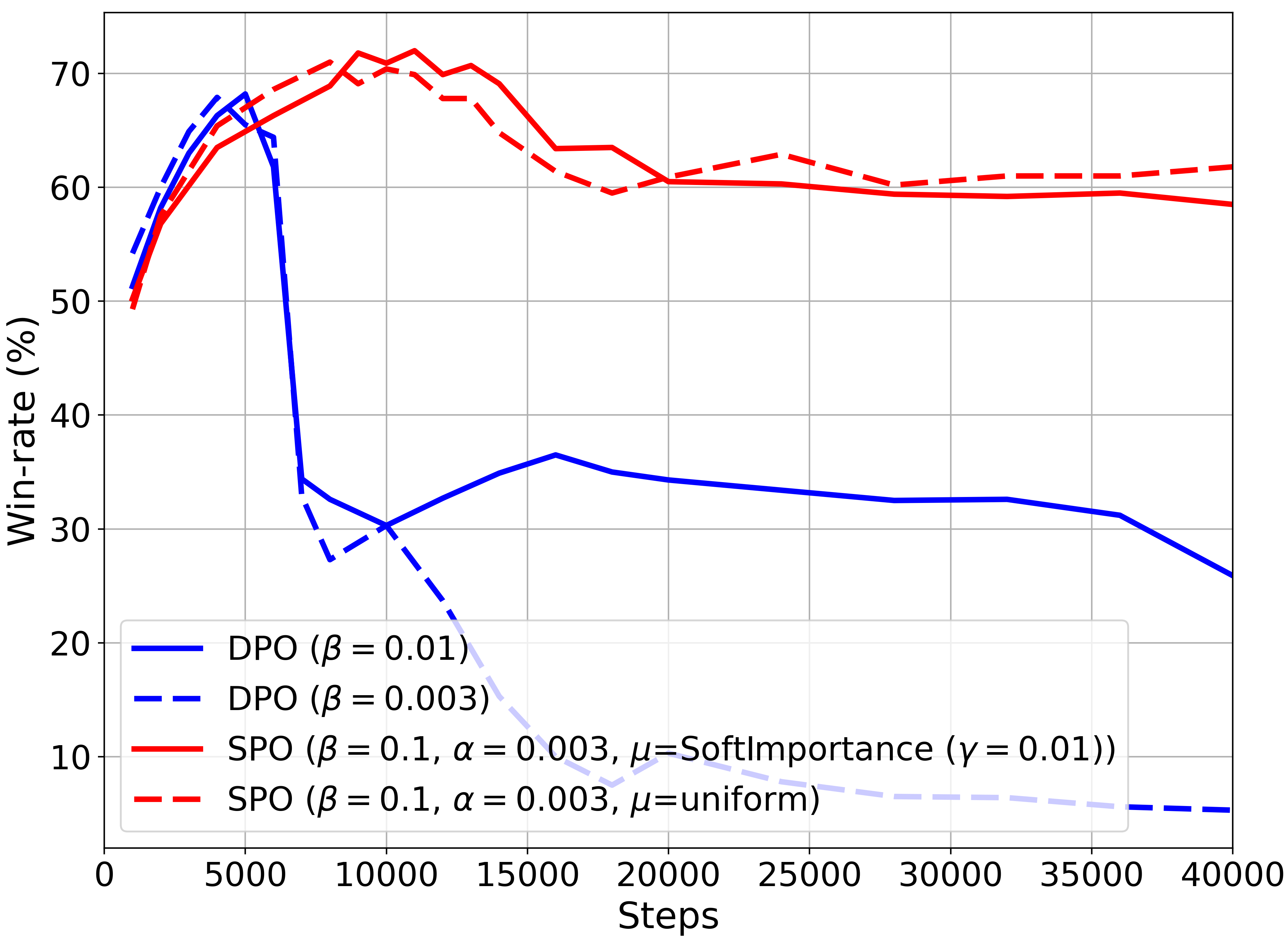
We propose Soft Preference Optimization (SPO), a method for aligning generative models, such as Large Language Models (LLMs), with human preferences, without the need for a reward model. SPO optimizes model outputs directly over a preference dataset through a natural loss function that integrates preference loss with a regularization term across the model's entire output distribution rather than limiting it to the preference dataset. Although SPO does not require the assumption of an existing underlying reward model, we demonstrate that, under the Bradley-Terry (BT) model assumption, it converges to a softmax of scaled rewards, with the distribution's softness adjustable via the softmax exponent, an algorithm parameter. We showcase SPO's methodology, its theoretical foundation, and its comparative advantages in simplicity, computational efficiency, and alignment precision.
Read more5/29/2024
📶
0
SPO: Multi-Dimensional Preference Sequential Alignment With Implicit Reward Modeling
Xingzhou Lou, Junge Zhang, Jian Xie, Lifeng Liu, Dong Yan, Kaiqi Huang
Human preference alignment is critical in building powerful and reliable large language models (LLMs). However, current methods either ignore the multi-dimensionality of human preferences (e.g. helpfulness and harmlessness) or struggle with the complexity of managing multiple reward models. To address these issues, we propose Sequential Preference Optimization (SPO), a method that sequentially fine-tunes LLMs to align with multiple dimensions of human preferences. SPO avoids explicit reward modeling, directly optimizing the models to align with nuanced human preferences. We theoretically derive closed-form optimal SPO policy and loss function. Gradient analysis is conducted to show how SPO manages to fine-tune the LLMs while maintaining alignment on previously optimized dimensions. Empirical results on LLMs of different size and multiple evaluation datasets demonstrate that SPO successfully aligns LLMs across multiple dimensions of human preferences and significantly outperforms the baselines.
Read more5/22/2024
0
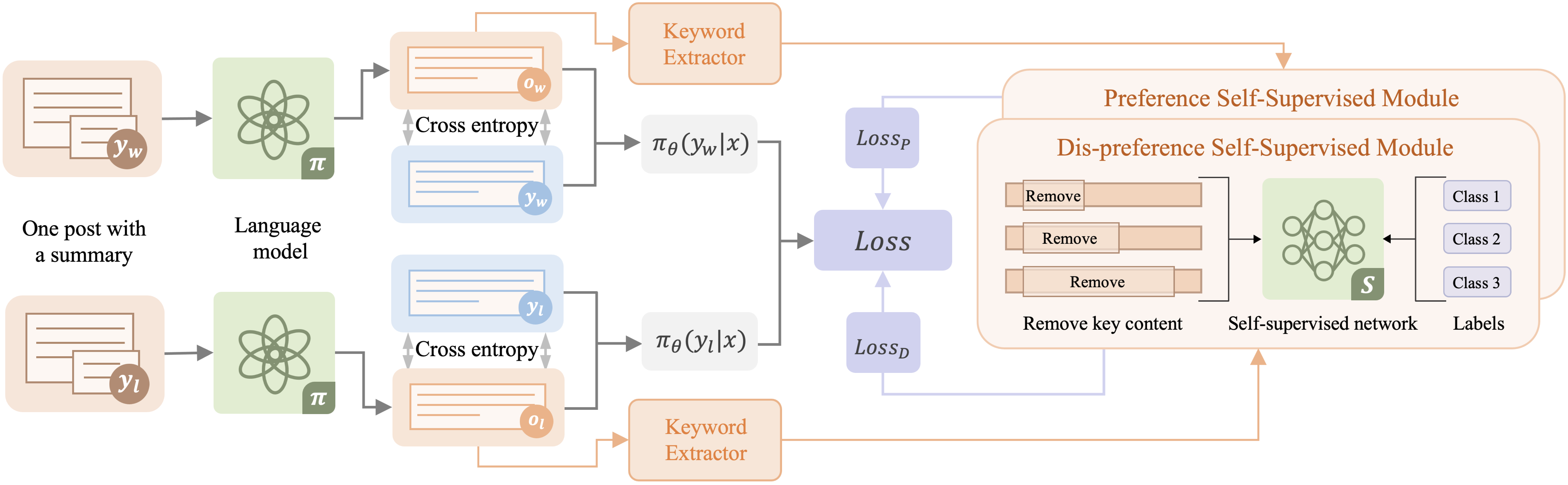
New!Self-supervised Preference Optimization: Enhance Your Language Model with Preference Degree Awareness
Jian Li, Haojing Huang, Yujia Zhang, Pengfei Xu, Xi Chen, Rui Song, Lida Shi, Jingwen Wang, Hao Xu
Recently, there has been significant interest in replacing the reward model in Reinforcement Learning with Human Feedback (RLHF) methods for Large Language Models (LLMs), such as Direct Preference Optimization (DPO) and its variants. These approaches commonly use a binary cross-entropy mechanism on pairwise samples, i.e., minimizing and maximizing the loss based on preferred or dis-preferred responses, respectively. However, while this training strategy omits the reward model, it also overlooks the varying preference degrees within different responses. We hypothesize that this is a key factor hindering LLMs from sufficiently understanding human preferences. To address this problem, we propose a novel Self-supervised Preference Optimization (SPO) framework, which constructs a self-supervised preference degree loss combined with the alignment loss, thereby helping LLMs improve their ability to understand the degree of preference. Extensive experiments are conducted on two widely used datasets of different tasks. The results demonstrate that SPO can be seamlessly integrated with existing preference optimization methods and significantly boost their performance to achieve state-of-the-art performance. We also conduct detailed analyses to offer comprehensive insights into SPO, which verifies its effectiveness. The code is available at https://github.com/lijian16/SPO.
Read more9/27/2024
0
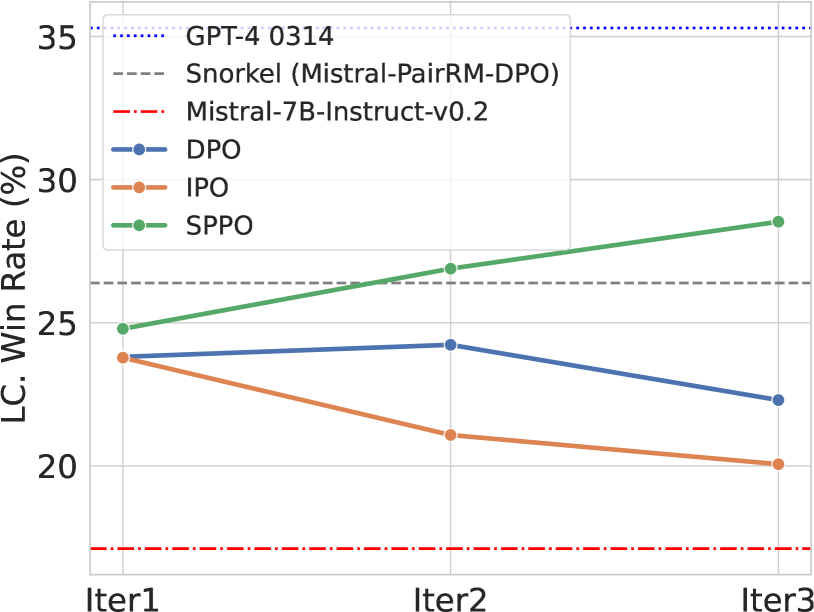
Self-Play Preference Optimization for Language Model Alignment
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, Quanquan Gu
Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed Self-Play Preference Optimization (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys a theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Starting from a stronger base model Llama-3-8B-Instruct, we are able to achieve a length-controlled win rate of 38.77%. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models. Codes are available at https://github.com/uclaml/SPPO.
Read more6/17/2024