Self-supervised Reflective Learning through Self-distillation and Online Clustering for Speaker Representation Learning

0

Sign in to get full access
Overview
- This paper presents a self-supervised reflective learning approach for speaker representation learning.
- The approach leverages self-distillation and online clustering to learn robust and discriminative speaker representations without the need for labeled data.
- The proposed method outperforms state-of-the-art self-supervised and supervised speaker verification models on several benchmark datasets.
Plain English Explanation
The paper describes a new way to train speech recognition systems to identify speakers without needing a lot of labeled training data. The key idea is to have the system learn from its own outputs, rather than relying on human-labeled examples.
The system works by first training a model to extract features from speech recordings. This model is then used to generate "pseudo-labels" for unlabeled speech data, clustering the data into groups that represent different speakers. The model is then fine-tuned using these automatically generated labels, a process called self-distillation.
This allows the model to learn robust and discriminative representations of speakers without the need for expensive and time-consuming human labeling. The authors show that this approach outperforms state-of-the-art self-supervised and supervised speaker verification models on several benchmark datasets.
Technical Explanation
The paper proposes a self-supervised reflective learning approach for speaker representation learning, leveraging self-distillation and online clustering. The key steps are:
- Pre-training a speaker feature extractor model on unlabeled speech data using a self-supervised contrastive learning objective.
- Using this pre-trained model to generate pseudo-labels for the unlabeled data through online clustering.
- Fine-tuning the feature extractor model using a self-distillation objective, where the model is trained to match its own outputs on the pseudo-labeled data.
- Iterating steps 2-3 to further refine the speaker representations.
The authors evaluate the proposed approach on several speaker verification benchmarks, demonstrating that it outperforms state-of-the-art self-supervised and supervised methods. The self-supervised multi-view contrastive learning and online clustering enable the model to learn robust and discriminative speaker representations without the need for expensive human labeling.
Critical Analysis
The paper presents a well-designed and effective approach for self-supervised speaker representation learning. The key strengths are the use of self-distillation and online clustering, which allow the model to iteratively refine its representations without human labels.
However, the paper does not address potential limitations or caveats of the approach. For example, the performance of the online clustering step may degrade as the number of speakers increases, and the self-distillation process could lead to compounding errors if the initial pseudo-labels are noisy.
Additionally, the paper focuses on speaker verification, but it would be interesting to see how the learned representations would transfer to other speech-related tasks, such as speaker diarization or speech recognition. Further research in these areas could help validate the broader applicability of the proposed method.
Overall, the paper makes a valuable contribution to the field of self-supervised speech representation learning, but additional analysis and exploration of the approach's limitations and broader applications would strengthen the work.
Conclusion
This paper presents a novel self-supervised reflective learning approach for speaker representation learning that leverages self-distillation and online clustering. By automatically generating pseudo-labels and fine-tuning the model accordingly, the proposed method is able to learn robust and discriminative speaker representations without the need for expensive human labeling.
The authors demonstrate that their approach outperforms state-of-the-art self-supervised and supervised speaker verification models on several benchmark datasets. This work represents an important step forward in the development of self-supervised speech representation learning, with the potential to significantly reduce the cost and effort required to build high-performing speech recognition systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-supervised Reflective Learning through Self-distillation and Online Clustering for Speaker Representation Learning
Danwei Cai, Zexin Cai, Ming Li
Speaker representation learning is critical for modern voice recognition systems. While supervised learning techniques require extensive labeled data, unsupervised methodologies can leverage vast unlabeled corpora, offering a scalable solution. This paper introduces self-supervised reflective learning (SSRL), a novel paradigm that streamlines existing iterative unsupervised frameworks. SSRL integrates self-supervised knowledge distillation with online clustering to refine pseudo labels and train the model without iterative bottlenecks. Specifically, a teacher model continually refines pseudo labels through online clustering, providing dynamic supervision signals to train the student model. The student model undergoes noisy student training with input and model noise to boost its modeling capacity. The teacher model is updated via an exponential moving average of the student, acting as an ensemble of past iterations. Further, a pseudo label queue retains historical labels for consistency, and noisy label modeling directs learning towards clean samples. Experiments on VoxCeleb show SSRL's superiority over current iterative approaches, surpassing the performance of a 5-round method in just a single training round. Ablation studies validate the contributions of key components like noisy label modeling and pseudo label queues. Moreover, consistent improvements in pseudo labeling and the convergence of cluster counts demonstrate SSRL's effectiveness in deciphering unlabeled data. This work marks an important advancement in efficient and accurate speaker representation learning through the novel reflective learning paradigm.
Read more7/17/2024

0
Self-Distillation Prototypes Network: Learning Robust Speaker Representations without Supervision
Yafeng Chen, Siqi Zheng, Hui Wang, Luyao Cheng, Qian Chen, Shiliang Zhang, Wen Wang
Training speaker-discriminative and robust speaker verification systems without explicit speaker labels remains a persisting challenge. In this paper, we propose a new self-supervised speaker verification approach, Self-Distillation Prototypes Network (SDPN), which effectively facilitates self-supervised speaker representation learning. SDPN assigns the representation of the augmented views of an utterance to the same prototypes as the representation of the original view, thereby enabling effective knowledge transfer between the views. Originally, due to the lack of negative pairs in the SDPN training process, the network tends to align positive pairs very closely in the embedding space, a phenomenon known as model collapse. To alleviate this problem, we introduce a diversity regularization term to embeddings in SDPN. Comprehensive experiments on the VoxCeleb datasets demonstrate the superiority of SDPN in self-supervised speaker verification. SDPN sets a new state-of-the-art on the VoxCeleb1 speaker verification evaluation benchmark, achieving Equal Error Rate 1.80%, 1.99%, and 3.62% for trial VoxCeleb1-O, VoxCeleb1-E and VoxCeleb1-H respectively, without using any speaker labels in training.
Read more6/26/2024

0
Leave No One Behind: Online Self-Supervised Self-Distillation for Sequential Recommendation
Shaowei Wei, Zhengwei Wu, Xin Li, Qintong Wu, Zhiqiang Zhang, Jun Zhou, Lihong Gu, Jinjie Gu
Sequential recommendation methods play a pivotal role in modern recommendation systems. A key challenge lies in accurately modeling user preferences in the face of data sparsity. To tackle this challenge, recent methods leverage contrastive learning (CL) to derive self-supervision signals by maximizing the mutual information of two augmented views of the original user behavior sequence. Despite their effectiveness, CL-based methods encounter a limitation in fully exploiting self-supervision signals for users with limited behavior data, as users with extensive behaviors naturally offer more information. To address this problem, we introduce a novel learning paradigm, named Online Self-Supervised Self-distillation for Sequential Recommendation ($S^4$Rec), effectively bridging the gap between self-supervised learning and self-distillation methods. Specifically, we employ online clustering to proficiently group users by their distinct latent intents. Additionally, an adversarial learning strategy is utilized to ensure that the clustering procedure is not affected by the behavior length factor. Subsequently, we employ self-distillation to facilitate the transfer of knowledge from users with extensive behaviors (teachers) to users with limited behaviors (students). Experiments conducted on four real-world datasets validate the effectiveness of the proposed methodfootnote{Code is available at https://github.com/xjaw/S4Rec
Read more4/12/2024
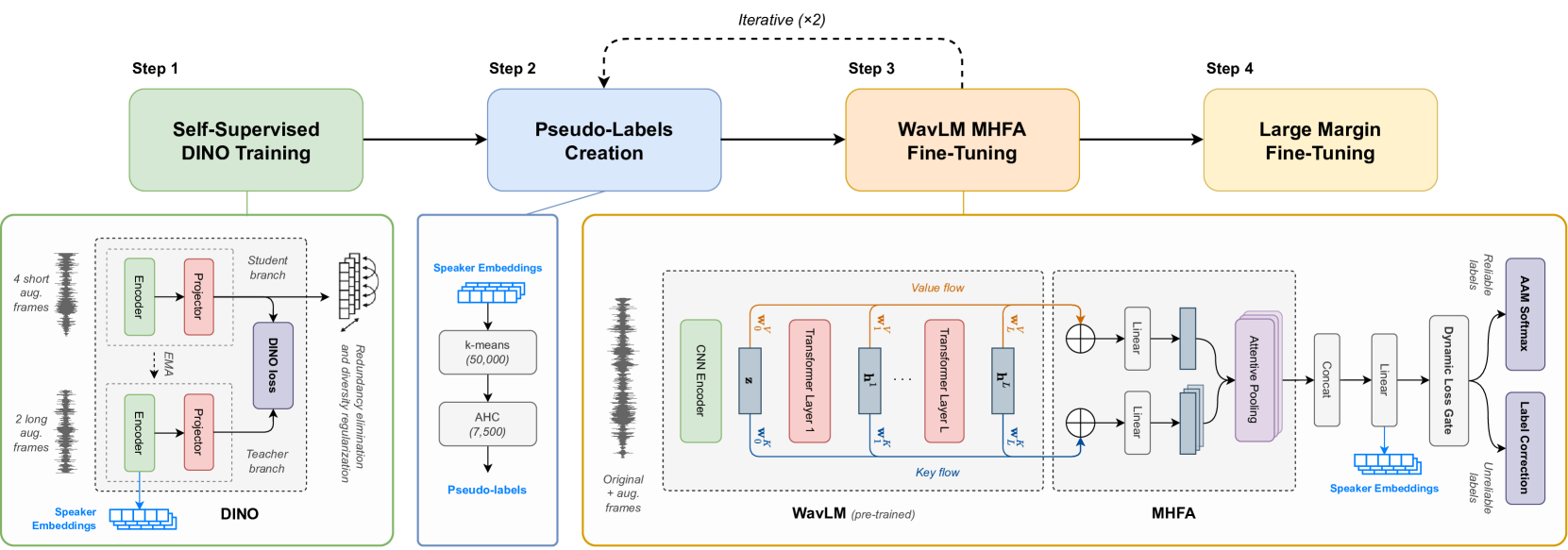
0
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
Read more6/5/2024