Self-Taught Recognizer: Toward Unsupervised Adaptation for Speech Foundation Models

0
Sign in to get full access
Overview
- This research paper proposes a self-taught speech recognition model called "Self-Taught Recognizer" (STAR) that can adapt to new domains without requiring labeled data.
- The model leverages unsupervised learning techniques to learn from unlabeled speech data, allowing it to adapt to different accents, speaking styles, and environments.
- The authors demonstrate the effectiveness of STAR on various speech recognition benchmarks, showing that it can outperform traditional supervised models in low-resource settings.
Plain English Explanation
The paper introduces a new speech recognition model called the "Self-Taught Recognizer" (STAR) that can adapt to new situations without needing a lot of labeled training data. Traditional speech recognition models are trained on large datasets of transcribed speech, which can be expensive and time-consuming to collect. In contrast, the STAR model uses unsupervised learning techniques to learn directly from unlabeled speech data, allowing it to adapt to different accents, speaking styles, and environmental conditions.
The key idea behind STAR is to extract useful information about speech patterns and linguistic features from the unlabeled data, and then use this knowledge to improve the model's performance on new speech recognition tasks. By leveraging this self-taught approach, the researchers show that STAR can outperform traditional supervised models, especially in low-resource settings where labeled data is scarce.
This type of adaptive speech recognition technology could have important applications, such as improving accessibility for people with diverse speech patterns or enabling more robust speech interfaces for autonomous systems. Overall, the STAR model represents a promising step towards more flexible and adaptable speech recognition systems.
Technical Explanation
The STAR model builds on recent advances in self-supervised learning for speech processing, such as self-supervised pretraining of text recognizers and the Conformer architecture for robust automatic speech recognition. The key innovation in STAR is the use of an unsupervised adaptation module that can fine-tune the model's parameters based on unlabeled speech data from the target domain.
The adaptation module consists of several components:
- Contrastive Representation Learning: This module learns useful speech representations by training the model to distinguish between different speech segments in the unlabeled data.
- Pseudo-Labeling: The model generates its own "pseudo-labels" for the unlabeled data, which are then used to fine-tune the main speech recognition model.
- Domain Adversarial Training: This component encourages the model to learn domain-invariant features, making it more robust to changes in the input distribution.
The authors evaluate STAR on several speech recognition benchmarks, including LibriSpeech, CommonVoice, and Switchboard. They show that STAR can outperform supervised baselines, especially in low-resource settings where labeled data is scarce. The model also demonstrates strong performance on cross-domain adaptation tasks, suggesting that the unsupervised adaptation strategies are effective at capturing linguistic and acoustic patterns that generalize well to new environments.
Critical Analysis
One potential limitation of the STAR approach is that it relies on the availability of a large amount of unlabeled speech data from the target domain. In some real-world scenarios, such data may not be easily accessible or may have significant biases or imbalances. The authors acknowledge this issue and suggest that future work could explore ways to address it, such as by leveraging transfer learning techniques or incorporating additional unsupervised learning strategies.
Another area for further research could be to investigate the interpretability and transparency of the STAR model. While the unsupervised adaptation modules seem to be effective, it may be valuable to better understand the specific linguistic and acoustic features that the model is learning and how they contribute to its improved performance. This could help to build trust in the model's outputs and potentially lead to insights that could benefit the broader field of speech recognition.
Overall, the STAR model represents an interesting and promising approach to adaptive speech recognition that could have important practical applications. The authors have done a thorough job of evaluating the model's performance and highlighting its strengths and limitations. Further research in this area could lead to even more robust and flexible speech recognition systems in the future.
Conclusion
The "Self-Taught Recognizer" (STAR) proposed in this paper is a novel speech recognition model that can adapt to new domains without requiring labeled training data. By leveraging unsupervised learning techniques to extract useful information from unlabeled speech data, STAR is able to outperform traditional supervised models, especially in low-resource settings.
The key innovations in STAR include its contrastive representation learning, pseudo-labeling, and domain adversarial training modules, which work together to enable effective unsupervised adaptation. The authors' evaluation of STAR on various speech recognition benchmarks demonstrates the model's strong performance and its potential to enhance the flexibility and accessibility of speech interfaces.
Overall, this research represents an important step towards more adaptable and versatile speech recognition systems, with promising applications in areas like assistive technology and autonomous systems. As the field of speech processing continues to evolve, the STAR approach could serve as a foundation for future advancements in unsupervised and self-supervised learning for speech recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Taught Recognizer: Toward Unsupervised Adaptation for Speech Foundation Models
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Chengwei Qin, Pin-Yu Chen, Eng Siong Chng, Chao Zhang
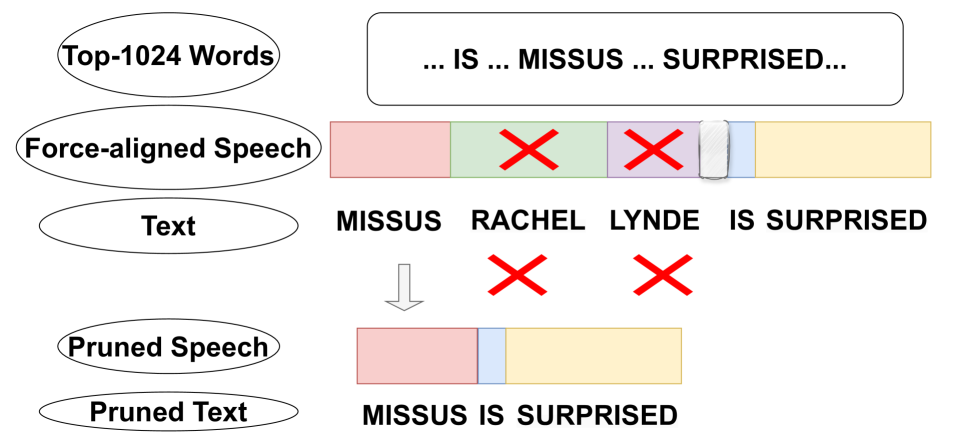
We propose an unsupervised adaptation framework, Self-TAught Recognizer (STAR), which leverages unlabeled data to enhance the robustness of automatic speech recognition (ASR) systems in diverse target domains, such as noise and accents. STAR is developed for prevalent speech foundation models based on Transformer-related architecture with auto-regressive decoding (e.g., Whisper, Canary). Specifically, we propose a novel indicator that empirically integrates step-wise information during decoding to assess the token-level quality of pseudo labels without ground truth, thereby guiding model updates for effective unsupervised adaptation. Experimental results show that STAR achieves an average of 13.5% relative reduction in word error rate across 14 target domains, and it sometimes even approaches the upper-bound performance of supervised adaptation. Surprisingly, we also observe that STAR prevents the adapted model from the common catastrophic forgetting problem without recalling source-domain data. Furthermore, STAR exhibits high data efficiency that only requires less than one-hour unlabeled data, and seamless generality to alternative large speech models and speech translation tasks. Our code aims to open source to the research communities.
Read more5/24/2024
0
Towards Unsupervised Speech Recognition Without Pronunciation Models
Junrui Ni, Liming Wang, Yang Zhang, Kaizhi Qian, Heting Gao, Mark Hasegawa-Johnson, Chang D. Yoo
Recent advancements in supervised automatic speech recognition (ASR) have achieved remarkable performance, largely due to the growing availability of large transcribed speech corpora. However, most languages lack sufficient paired speech and text data to effectively train these systems. In this article, we tackle the challenge of developing ASR systems without paired speech and text corpora by proposing the removal of reliance on a phoneme lexicon. We explore a new research direction: word-level unsupervised ASR. Using a curated speech corpus containing only high-frequency English words, our system achieves a word error rate of nearly 20% without parallel transcripts or oracle word boundaries. Furthermore, we experimentally demonstrate that an unsupervised speech recognizer can emerge from joint speech-to-speech and text-to-text masked token-infilling. This innovative model surpasses the performance of previous unsupervised ASR models trained with direct distribution matching.
Read more6/13/2024
🤷
0
Unsupervised Online Continual Learning for Automatic Speech Recognition
Steven Vander Eeckt, Hugo Van hamme
Adapting Automatic Speech Recognition (ASR) models to new domains leads to Catastrophic Forgetting (CF) of previously learned information. This paper addresses CF in the challenging context of Online Continual Learning (OCL), with tasks presented as a continuous data stream with unknown boundaries. We extend OCL for ASR into the unsupervised realm, by leveraging self-training (ST) to facilitate unsupervised adaptation, enabling models to adapt continually without label dependency and without forgetting previous knowledge. Through comparative analysis of various OCL and ST methods across two domain adaptation experiments, we show that UOCL suffers from significantly less forgetting compared to supervised OCL, allowing UOCL methods to approach the performance levels of supervised OCL. Our proposed UOCL extensions further boosts UOCL's efficacy. Our findings represent a significant step towards continually adaptable ASR systems, capable of leveraging unlabeled data across diverse domains.
Read more6/19/2024

0
Personalized Speech Recognition for Children with Test-Time Adaptation
Zhonghao Shi, Harshvardhan Srivastava, Xuan Shi, Shrikanth Narayanan, Maja J. Matari'c
Accurate automatic speech recognition (ASR) for children is crucial for effective real-time child-AI interaction, especially in educational applications. However, off-the-shelf ASR models primarily pre-trained on adult data tend to generalize poorly to children's speech due to the data domain shift from adults to children. Recent studies have found that supervised fine-tuning on children's speech data can help bridge this domain shift, but human annotations may be impractical to obtain for real-world applications and adaptation at training time can overlook additional domain shifts occurring at test time. We devised a novel ASR pipeline to apply unsupervised test-time adaptation (TTA) methods for child speech recognition, so that ASR models pre-trained on adult speech can be continuously adapted to each child speaker at test time without further human annotations. Our results show that ASR models adapted with TTA methods significantly outperform the unadapted off-the-shelf ASR baselines both on average and statistically across individual child speakers. Our analysis also discovered significant data domain shifts both between child speakers and within each child speaker, which further motivates the need for test-time adaptation.
Read more9/24/2024