STaR: Distilling Speech Temporal Relation for Lightweight Speech Self-Supervised Learning Models

0
Sign in to get full access
Overview
- The paper proposes a new self-supervised learning method called "STaR" (Speech Temporal Relation) to train lightweight speech recognition models.
- STaR distills the temporal relation information from a larger pre-trained model to the target lightweight model, allowing it to learn efficient representations without extensive training.
- The technique is designed to improve the performance of small speech models on downstream tasks while keeping the model size and inference time low.
Plain English Explanation
Speech recognition models, which convert audio into text, are an important technology with many real-world applications. However, the most accurate models can be large and computationally intensive, making them challenging to deploy on resource-constrained devices like smartphones.
The researchers behind the STaR paper wanted to find a way to train smaller, more efficient speech models without sacrificing too much accuracy. Their key insight was that a lot of the important information in speech data is about the temporal relationships between different sounds and words - when they occur relative to each other.
So they developed a technique called "Speech Temporal Relation (STaR) distillation" that allows a smaller model to learn these temporal patterns from a larger, more powerful pre-trained model. By distilling this temporal relation knowledge, the smaller model can build effective representations of speech without needing to be trained on as much raw data.
The result is a speech recognition model that is much lighter and faster, but can still perform well on downstream tasks like transcription, thanks to the temporal relation knowledge it gained from the larger teacher model. This could enable speech AI to be deployed more widely on edge devices where compute and memory are limited.
Technical Explanation
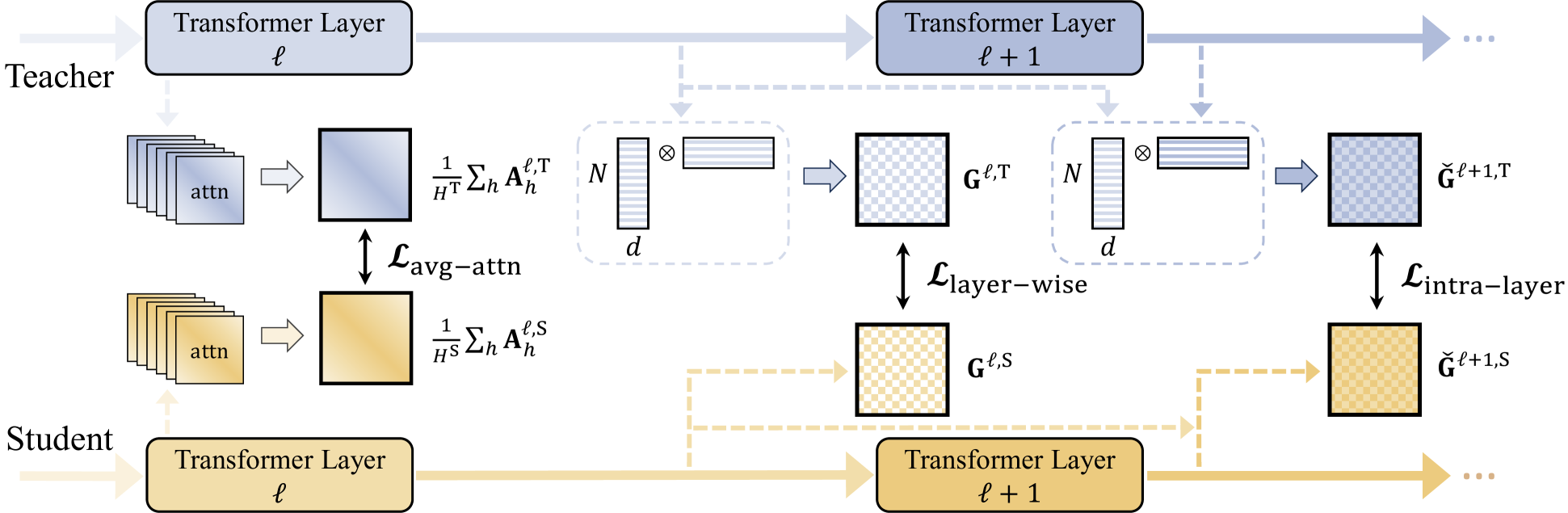
The core of the STaR approach is a distillation process that transfers temporal relation information from a larger pre-trained speech model to a smaller target model.
The first key component is [object Object]. This takes the attention maps from the pre-trained model's self-attention layers and averages them to capture the overall temporal relationships in the speech data. The target model then learns to match these averaged attention maps through a distillation loss.
The second component is [object Object]. This encourages the target model to learn representations that preserve the temporal ordering of speech frames, by having it predict whether pairs of frames come from the same or different parts of the audio.
Together, these two distillation techniques allow the smaller model to efficiently learn useful speech representations focused on temporal patterns, without needing to be trained on the full speech dataset from scratch like the larger pre-trained model was.
The researchers evaluate STaR on a range of speech recognition benchmarks, showing it can achieve strong performance with much smaller model sizes and faster inference times compared to fully trained models. They also demonstrate its effectiveness in downstream tasks like voice activity detection and speaker diarization.
Critical Analysis
The STaR approach seems well-designed to address the challenge of building efficient speech models for real-world deployment. By targeting temporal relation learning, the authors leverage a key characteristic of speech data that is often overlooked in standard self-supervised techniques.
However, the paper does not provide much insight into the limitations of the method or areas for potential improvement. For example, it's unclear how STaR would perform on noisy or non-English speech data, or how the distillation process might be further optimized.
Additionally, the authors focus mainly on model size and inference speed as the key metrics, but don't discuss other important factors like training efficiency, sample complexity, or robustness. There may be tradeoffs in these areas that are worth exploring.
Overall, the STaR technique is a promising step towards more practical speech AI, but further research is needed to fully understand its strengths, weaknesses, and the best ways to apply it in real-world scenarios. Readers should think critically about the broader implications and potential issues that were not addressed in the paper.
Conclusion
The STaR paper presents an innovative approach to training lightweight, efficient speech recognition models through self-supervised learning of temporal relations. By distilling this key information from a larger pre-trained model, the method allows smaller models to achieve strong performance on downstream tasks without the need for extensive training.
This work demonstrates the value of focusing on the unique characteristics of speech data, rather than relying solely on generic self-supervision techniques. The STaR approach could enable speech AI to be deployed more widely on resource-constrained edge devices, with potential applications in areas like voice assistants, translation, and audio analysis.
While the paper has some limitations in its scope, the core ideas behind STaR are a significant contribution to the field of efficient speech modeling. As the demand for accurate yet lightweight speech technologies continues to grow, techniques like this will be crucial for bridging the gap between research and real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
STaR: Distilling Speech Temporal Relation for Lightweight Speech Self-Supervised Learning Models
Kangwook Jang, Sungnyun Kim, Hoirin Kim
Albeit great performance of Transformer-based speech selfsupervised learning (SSL) models, their large parameter size and computational cost make them unfavorable to utilize. In this study, we propose to compress the speech SSL models by distilling speech temporal relation (STaR). Unlike previous works that directly match the representation for each speech frame, STaR distillation transfers temporal relation between speech frames, which is more suitable for lightweight student with limited capacity. We explore three STaR distillation objectives and select the best combination as the final STaR loss. Our model distilled from HuBERT BASE achieves an overall score of 79.8 on SUPERB benchmark, the best performance among models with up to 27 million parameters. We show that our method is applicable across different speech SSL models and maintains robust performance with further reduced parameters.
Read more4/26/2024
0
Self-Taught Recognizer: Toward Unsupervised Adaptation for Speech Foundation Models
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Chengwei Qin, Pin-Yu Chen, Eng Siong Chng, Chao Zhang
We propose an unsupervised adaptation framework, Self-TAught Recognizer (STAR), which leverages unlabeled data to enhance the robustness of automatic speech recognition (ASR) systems in diverse target domains, such as noise and accents. STAR is developed for prevalent speech foundation models based on Transformer-related architecture with auto-regressive decoding (e.g., Whisper, Canary). Specifically, we propose a novel indicator that empirically integrates step-wise information during decoding to assess the token-level quality of pseudo labels without ground truth, thereby guiding model updates for effective unsupervised adaptation. Experimental results show that STAR achieves an average of 13.5% relative reduction in word error rate across 14 target domains, and it sometimes even approaches the upper-bound performance of supervised adaptation. Surprisingly, we also observe that STAR prevents the adapted model from the common catastrophic forgetting problem without recalling source-domain data. Furthermore, STAR exhibits high data efficiency that only requires less than one-hour unlabeled data, and seamless generality to alternative large speech models and speech translation tasks. Our code aims to open source to the research communities.
Read more5/24/2024

0
LASER: Learning by Aligning Self-supervised Representations of Speech for Improving Content-related Tasks
Amit Meghanani, Thomas Hain
Self-supervised learning (SSL)-based speech models are extensively used for full-stack speech processing. However, it has been observed that improving SSL-based speech representations using unlabeled speech for content-related tasks is challenging and computationally expensive. Recent attempts have been made to address this issue with cost-effective self-supervised fine-tuning (SSFT) approaches. Continuing in this direction, a cost-effective SSFT method named LASER: Learning by Aligning Self-supervised Representations is presented. LASER is based on the soft-DTW alignment loss with temporal regularisation term. Experiments are conducted with HuBERT and WavLM models and evaluated on the SUPERB benchmark for two content-related tasks: automatic speech recognition (ASR) and phoneme recognition (PR). A relative improvement of 3.7% and 8.2% for HuBERT, and 4.1% and 11.7% for WavLM are observed, for the ASR and PR tasks respectively, with only < 3 hours of fine-tuning on a single GPU.
Read more6/14/2024

0
To Distill or Not to Distill? On the Robustness of Robust Knowledge Distillation
Abdul Waheed, Karima Kadaoui, Muhammad Abdul-Mageed
Arabic is known to present unique challenges for Automatic Speech Recognition (ASR). On one hand, its rich linguistic diversity and wide range of dialects complicate the development of robust, inclusive models. On the other, current multilingual ASR models are compute-intensive and lack proper comprehensive evaluations. In light of these challenges, we distill knowledge from large teacher models into smaller student variants that are more efficient. We also introduce a novel human-annotated dataset covering five under-represented Arabic dialects for evaluation. We further evaluate both our models and existing SoTA multilingual models on both standard available benchmarks and our new dialectal data. Our best-distilled model's overall performance ($45.0$% WER) surpasses that of a SoTA model twice its size (SeamlessM4T-large-v2, WER=$47.0$%) and its teacher model (Whisper-large-v2, WER=$55.1$%), and its average performance on our new dialectal data ($56.9$% WER) outperforms all other models. To gain more insight into the poor performance of these models on dialectal data, we conduct an error analysis and report the main types of errors the different models tend to make. The GitHub repository for the project is available at url{https://github.com/UBC-NLP/distill-whisper-ar}.
Read more6/10/2024