Self-training Room Layout Estimation via Geometry-aware Ray-casting

0

Sign in to get full access
Overview
- This paper presents a self-training method for room layout estimation using geometry-aware ray-casting.
- The approach leverages multi-view consistency and geometry constraints to train a model to predict room layouts from a single image.
- The method demonstrates improved performance compared to prior work on room layout estimation.
Plain English Explanation
The goal of this research is to develop a system that can accurately estimate the layout of a room, such as the positions and orientations of the walls, floor, and ceiling, from a single photograph. This is a challenging task because rooms can have complex shapes and the camera perspective can distort the appearance of the room.
To address this, the researchers propose a self-training approach that allows the model to learn from its own predictions. The key idea is to use multi-view consistency - the fact that the room layout should appear consistent from multiple viewpoints - as well as geometric constraints to guide the model's learning.
The model is first trained on a small dataset of labeled room images. It then uses this initial knowledge to make predictions on unlabeled images. The consistency of these predictions across multiple viewpoints of the same room, as well as their alignment with geometric constraints, is used to refine the model's understanding. This self-training process allows the model to iteratively improve its room layout estimation capabilities without requiring expensive manual labeling of large datasets.
The researchers show that this approach outperforms previous methods for room layout estimation, demonstrating the potential of leveraging multi-view geometry and self-supervision to tackle this challenging computer vision problem.
Technical Explanation
The paper proposes a self-training framework for room layout estimation that incorporates multi-view consistency and geometry-aware ray-casting to guide the learning process.
The model is first trained on a small dataset of room images with ground truth layout annotations. It uses a deep neural network to predict the layout of a room from a single input image.
To improve the model's performance, the researchers introduce a self-training procedure that leverages unlabeled data. The model makes initial layout predictions on the unlabeled images, and then evaluates the consistency of these predictions across multiple viewpoints of the same room. It also checks the alignment of the predictions with 3D geometric constraints derived from the room's structure.
The consistency and geometric scores are used to select high-confidence predictions, which are then added to the training dataset. This allows the model to iteratively refine its understanding of room layouts without requiring expensive manual annotations.
The paper's experiments demonstrate that this self-training approach, combined with the use of multi-view consistency and geometric priors, leads to significant improvements in room layout estimation accuracy compared to prior methods, including those that rely on transformer-based architectures.
Critical Analysis
The paper presents a compelling approach to room layout estimation that leverages self-training and geometric constraints. The key strengths of the method are its ability to learn from unlabeled data and its grounding in the underlying 3D geometry of the room.
However, the paper does not extensively explore the limitations of the proposed approach. For example, it is unclear how the method would perform on rooms with highly irregular or complex shapes, or in the presence of occlusions or cluttered environments. Additionally, the paper does not discuss the computational efficiency of the self-training process, which could be an important consideration for real-world deployment.
Further research could investigate ways to make the self-training process more robust, such as by incorporating additional geometric cues or exploring alternative methods for selecting high-confidence predictions. Evaluating the approach on a wider range of room types and real-world scenarios would also help to better understand its strengths and limitations.
Conclusion
This paper introduces a novel self-training framework for room layout estimation that leverages multi-view consistency and geometry-aware ray-casting to improve model performance. By incorporating these geometric constraints and allowing the model to learn from its own predictions, the researchers demonstrate significant gains over prior state-of-the-art methods.
While the paper does not fully explore the limitations of the approach, the underlying ideas of using self-supervision and geometric priors to tackle complex vision problems are promising. Further development and evaluation of this method could lead to more accurate and robust room layout estimation systems, with potential applications in areas such as interior design, robot navigation, and virtual/augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-training Room Layout Estimation via Geometry-aware Ray-casting
Bolivar Solarte, Chin-Hsuan Wu, Jin-Cheng Jhang, Jonathan Lee, Yi-Hsuan Tsai, Min Sun
In this paper, we introduce a novel geometry-aware self-training framework for room layout estimation models on unseen scenes with unlabeled data. Our approach utilizes a ray-casting formulation to aggregate multiple estimates from different viewing positions, enabling the computation of reliable pseudo-labels for self-training. In particular, our ray-casting approach enforces multi-view consistency along all ray directions and prioritizes spatial proximity to the camera view for geometry reasoning. As a result, our geometry-aware pseudo-labels effectively handle complex room geometries and occluded walls without relying on assumptions such as Manhattan World or planar room walls. Evaluation on publicly available datasets, including synthetic and real-world scenarios, demonstrates significant improvements in current state-of-the-art layout models without using any human annotation.
Read more7/23/2024
0
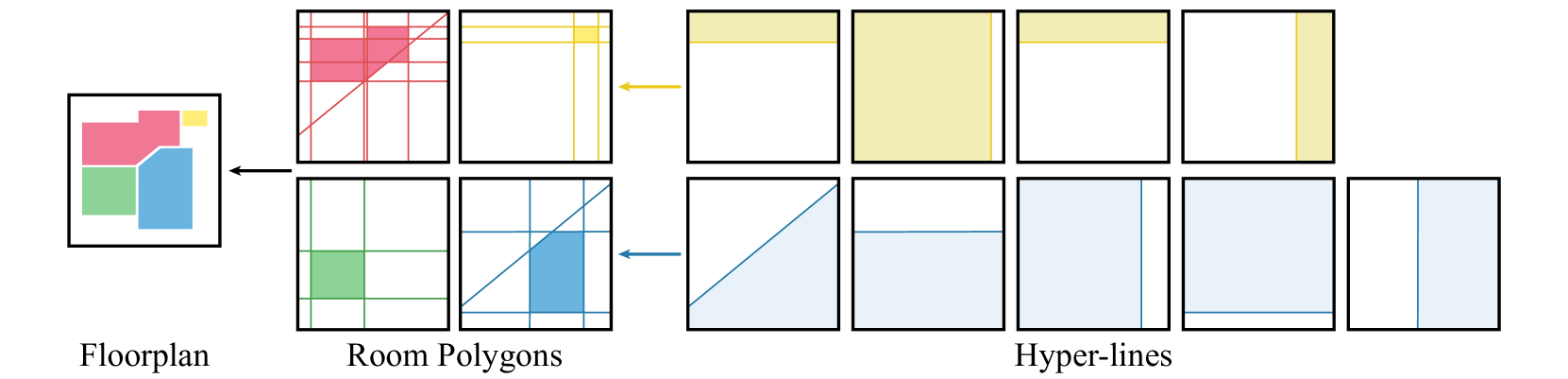
FRI-Net: Floorplan Reconstruction via Room-wise Implicit Representation
Honghao Xu, Juzhan Xu, Zeyu Huang, Pengfei Xu, Hui Huang, Ruizhen Hu
In this paper, we introduce a novel method called FRI-Net for 2D floorplan reconstruction from 3D point cloud. Existing methods typically rely on corner regression or box regression, which lack consideration for the global shapes of rooms. To address these issues, we propose a novel approach using a room-wise implicit representation with structural regularization to characterize the shapes of rooms in floorplans. By incorporating geometric priors of room layouts in floorplans into our training strategy, the generated room polygons are more geometrically regular. We have conducted experiments on two challenging datasets, Structured3D and SceneCAD. Our method demonstrates improved performance compared to state-of-the-art methods, validating the effectiveness of our proposed representation for floorplan reconstruction.
Read more7/16/2024

0
PolyRoom: Room-aware Transformer for Floorplan Reconstruction
Yuzhou Liu, Lingjie Zhu, Xiaodong Ma, Hanqiao Ye, Xiang Gao, Xianwei Zheng, Shuhan Shen
Reconstructing geometry and topology structures from raw unstructured data has always been an important research topic in indoor mapping research. In this paper, we aim to reconstruct the floorplan with a vectorized representation from point clouds. Despite significant advancements achieved in recent years, current methods still encounter several challenges, such as missing corners or edges, inaccuracies in corner positions or angles, self-intersecting or overlapping polygons, and potentially implausible topology. To tackle these challenges, we present PolyRoom, a room-aware Transformer that leverages uniform sampling representation, room-aware query initialization, and room-aware self-attention for floorplan reconstruction. Specifically, we adopt a uniform sampling floorplan representation to enable dense supervision during training and effective utilization of angle information. Additionally, we propose a room-aware query initialization scheme to prevent non-polygonal sequences and introduce room-aware self-attention to enhance memory efficiency and model performance. Experimental results on two widely used datasets demonstrate that PolyRoom surpasses current state-of-the-art methods both quantitatively and qualitatively. Our code is available at: https://github.com/3dv-casia/PolyRoom/.
Read more7/16/2024
0
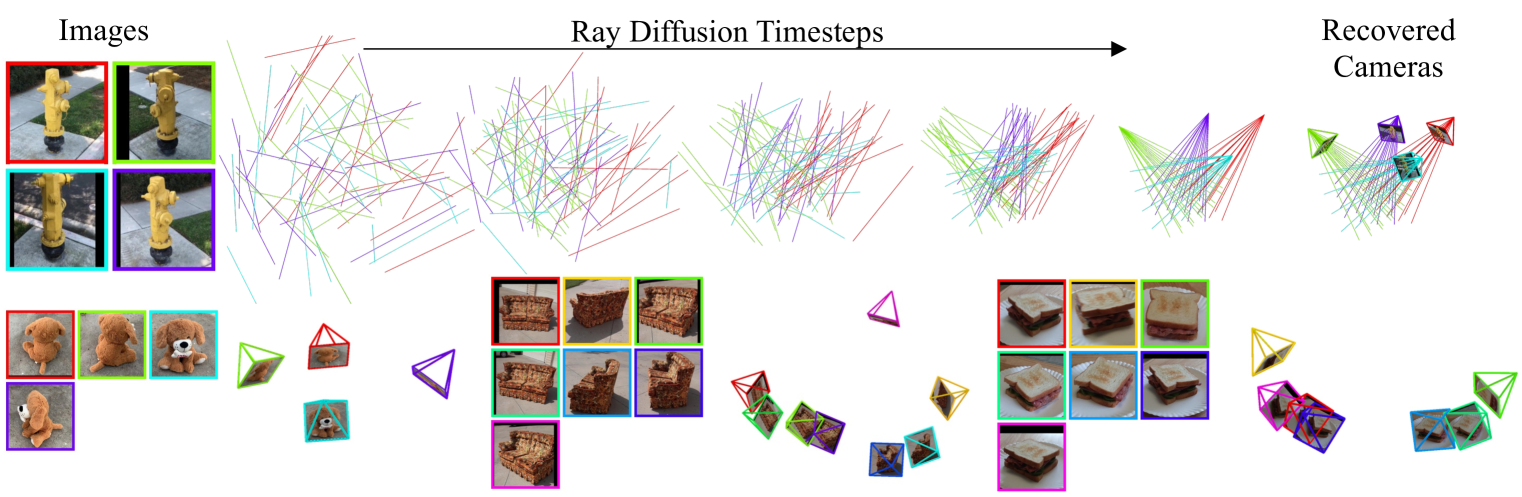
Cameras as Rays: Pose Estimation via Ray Diffusion
Jason Y. Zhang, Amy Lin, Moneish Kumar, Tzu-Hsuan Yang, Deva Ramanan, Shubham Tulsiani
Estimating camera poses is a fundamental task for 3D reconstruction and remains challenging given sparsely sampled views (<10). In contrast to existing approaches that pursue top-down prediction of global parametrizations of camera extrinsics, we propose a distributed representation of camera pose that treats a camera as a bundle of rays. This representation allows for a tight coupling with spatial image features improving pose precision. We observe that this representation is naturally suited for set-level transformers and develop a regression-based approach that maps image patches to corresponding rays. To capture the inherent uncertainties in sparse-view pose inference, we adapt this approach to learn a denoising diffusion model which allows us to sample plausible modes while improving performance. Our proposed methods, both regression- and diffusion-based, demonstrate state-of-the-art performance on camera pose estimation on CO3D while generalizing to unseen object categories and in-the-wild captures.
Read more4/5/2024