Semantic In-Domain Product Identification for Search Queries

0

Sign in to get full access
Overview
- This paper presents a novel approach for identifying products in search queries using semantic understanding.
- The proposed method combines explicit and implicit Named Entity Recognition (NER) to accurately detect product-related entities in user search queries.
- The authors evaluate their approach on several datasets, demonstrating its effectiveness in improving search relevance and autocomplete functionality.
Plain English Explanation
When you search for something online, the search engine needs to understand what you're looking for in order to provide the most relevant results. This can be challenging, especially for product-related queries, where the same item might be described in different ways.
The researchers in this paper developed a new technique to address this problem. Their approach combines two different ways of identifying products in search queries:
- Explicit NER: This looks for clear product names or descriptions that are directly mentioned in the query.
- Implicit NER: This looks for more subtle cues that indicate a product, even if it's not explicitly stated.
By using both of these methods together, the system can more accurately determine when a user is searching for a specific product, even if they don't use the exact product name. This helps the search engine provide better results and make more relevant autocomplete suggestions.
The researchers tested their approach on several datasets and found that it outperformed other methods at accurately identifying products in search queries. This could be especially useful for e-commerce and shopping-related searches, where getting the right products in front of users is critical.
Technical Explanation
The paper proposes a semantic in-domain product identification approach that combines explicit and implicit Named Entity Recognition (NER) to accurately detect product-related entities in user search queries.
The explicit NER component uses a standard NER model to identify clear product names or descriptions that are directly mentioned in the query. The implicit NER component, on the other hand, looks for more subtle cues that may indicate a product, even if it's not explicitly stated.
To train the implicit NER model, the authors leverage domain-specific training data and use attention mechanisms to capture contextual relationships between query terms. This allows the model to learn patterns and associations that are indicative of product-related searches, even when the product itself is not named explicitly.
The authors evaluate their approach on several datasets, including a large-scale e-commerce search query log. They compare their method to various baselines and show that the combination of explicit and implicit NER significantly outperforms other techniques in terms of identifying products in search queries. This, in turn, leads to improvements in search relevance and autocomplete functionality.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach for semantic product identification in search queries. The authors have clearly put a lot of thought into the problem and have come up with a novel solution that combines multiple NER techniques.
One potential limitation of the study is the reliance on domain-specific training data for the implicit NER component. While this allows the model to learn relevant patterns, it may limit the generalizability of the approach to other domains or use cases. It would be interesting to see how the method performs when applied to a broader range of search queries, beyond just e-commerce.
Additionally, the paper does not delve into the potential biases or ethical considerations that may arise from using such a system. As with any AI-powered technology, there is a risk of amplifying existing biases or introducing new ones. The authors could have addressed these concerns more explicitly and discussed potential mitigation strategies.
Overall, the research presented in this paper is a valuable contribution to the field of search engine optimization and user intent understanding. The proposed approach demonstrates the power of combining explicit and implicit signals to improve the accuracy of product identification in search queries.
Conclusion
This paper introduces a novel semantic in-domain product identification approach that leverages explicit and implicit Named Entity Recognition to accurately detect products in user search queries. The authors' experiments show that their method outperforms other techniques and can lead to significant improvements in search relevance and autocomplete functionality.
The proposed approach represents an important step forward in understanding user intent and providing better search experiences, particularly in e-commerce and shopping-related domains. As the use of AI and machine learning continues to grow in search engines and other online platforms, techniques like the one described in this paper will become increasingly valuable for delivering more personalized and relevant results to users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Semantic In-Domain Product Identification for Search Queries
Sanat Sharma, Jayant Kumar, Twisha Naik, Zhaoyu Lu, Arvind Srikantan, Tracy Holloway King
Accurate explicit and implicit product identification in search queries is critical for enhancing user experiences, especially at a company like Adobe which has over 50 products and covers queries across hundreds of tools. In this work, we present a novel approach to training a product classifier from user behavioral data. Our semantic model led to >25% relative improvement in CTR (click through rate) across the deployed surfaces; a >50% decrease in null rate; a 2x increase in the app cards surfaced, which helps drive product visibility.
Read more5/30/2024
0
Multi-word Term Embeddings Improve Lexical Product Retrieval
Viktor Shcherbakov, Fedor Krasnov
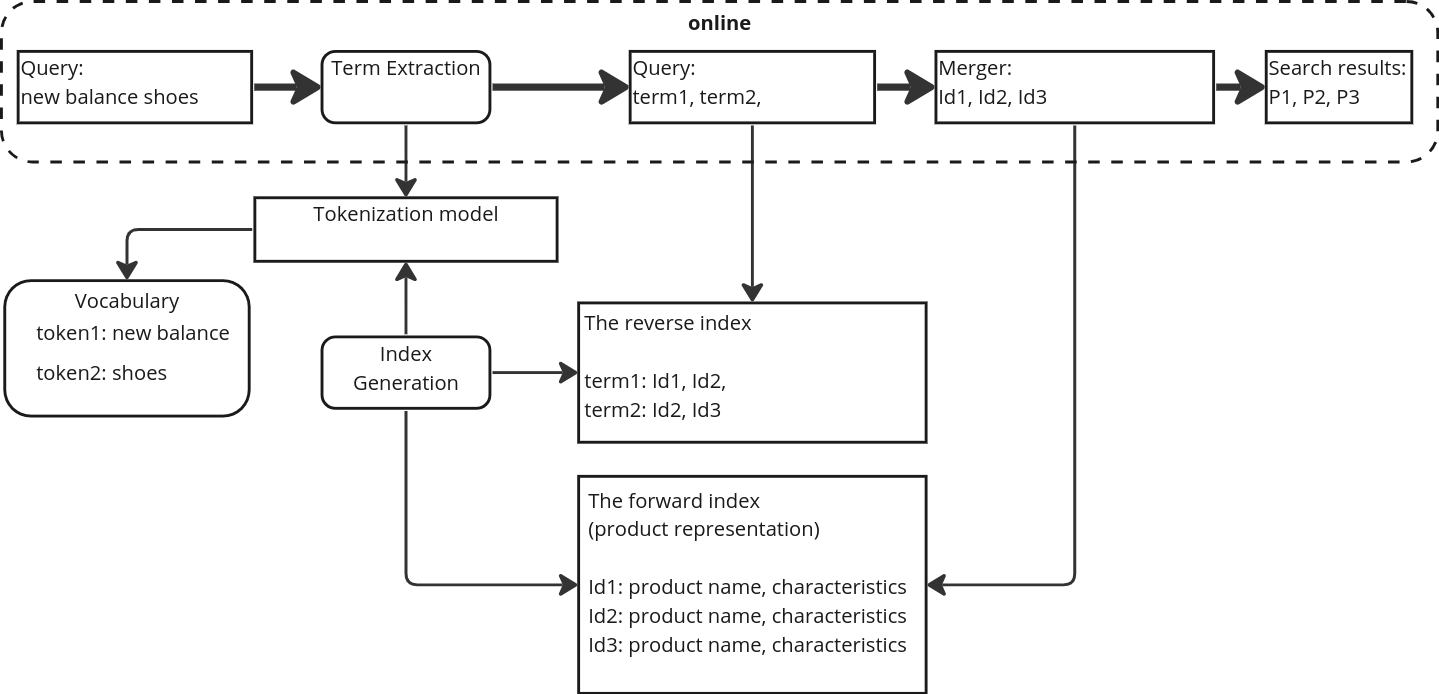
Product search is uniquely different from search for documents, Internet resources or vacancies, therefore it requires the development of specialized search systems. The present work describes the H1 embdedding model, designed for an offline term indexing of product descriptions at e-commerce platforms. The model is compared to other state-of-the-art (SoTA) embedding models within a framework of hybrid product search system that incorporates the advantages of lexical methods for product retrieval and semantic embedding-based methods. We propose an approach to building semantically rich term vocabularies for search indexes. Compared to other production semantic models, H1 paired with the proposed approach stands out due to its ability to process multi-word product terms as one token. As an example, for search queries new balance shoes, gloria jeans kids wear brand entity will be represented as one token - new balance, gloria jeans. This results in an increased precision of the system without affecting the recall. The hybrid search system with proposed model scores mAP@12 = 56.1% and R@1k = 86.6% on the WANDS public dataset, beating other SoTA analogues.
Read more6/4/2024

0
KaPQA: Knowledge-Augmented Product Question-Answering
Swetha Eppalapally, Daksh Dangi, Chaithra Bhat, Ankita Gupta, Ruiyi Zhang, Shubham Agarwal, Karishma Bagga, Seunghyun Yoon, Nedim Lipka, Ryan A. Rossi, Franck Dernoncourt
Question-answering for domain-specific applications has recently attracted much interest due to the latest advancements in large language models (LLMs). However, accurately assessing the performance of these applications remains a challenge, mainly due to the lack of suitable benchmarks that effectively simulate real-world scenarios. To address this challenge, we introduce two product question-answering (QA) datasets focused on Adobe Acrobat and Photoshop products to help evaluate the performance of existing models on domain-specific product QA tasks. Additionally, we propose a novel knowledge-driven RAG-QA framework to enhance the performance of the models in the product QA task. Our experiments demonstrated that inducing domain knowledge through query reformulation allowed for increased retrieval and generative performance when compared to standard RAG-QA methods. This improvement, however, is slight, and thus illustrates the challenge posed by the datasets introduced.
Read more7/24/2024
🖼️
0
Hybrid Semantic Search: Unveiling User Intent Beyond Keywords
Aman Ahluwalia, Bishwajit Sutradhar, Karishma Ghosh, Indrapal Yadav, Arpan Sheetal, Prashant Patil
This paper addresses the limitations of traditional keyword-based search in understanding user intent and introduces a novel hybrid search approach that leverages the strengths of non-semantic search engines, Large Language Models (LLMs), and embedding models. The proposed system integrates keyword matching, semantic vector embeddings, and LLM-generated structured queries to deliver highly relevant and contextually appropriate search results. By combining these complementary methods, the hybrid approach effectively captures both explicit and implicit user intent.The paper further explores techniques to optimize query execution for faster response times and demonstrates the effectiveness of this hybrid search model in producing comprehensive and accurate search outcomes.
Read more9/9/2024