Semantic Gesticulator: Semantics-Aware Co-Speech Gesture Synthesis

0

Sign in to get full access
Overview
• This paper introduces the "Semantic Gesticulator", a system that can generate co-speech gestures that are semantically aligned with the input speech. • The system uses a retrieval-based approach, where it selects relevant gesture clips from a database and then adapts them to match the input speech. • The key innovation is the use of semantic information to guide the gesture selection and adaptation process, leading to more natural and meaningful co-speech gestures.
Plain English Explanation
The "Semantic Gesticulator" is a system that can create hand and body gestures that naturally accompany spoken language. When you talk, your body often moves and gestures in a way that helps convey the meaning of what you're saying. This paper presents a new approach to automatically generating those kinds of gestures.
The system works by having a library of pre-recorded gesture clips. When you give it some speech input, it selects the most relevant gesture clips from the library and then adapts them to match the specific words and ideas being expressed. The novel part is that it uses the actual meaning or "semantics" of the speech to guide this process, rather than just looking at the surface-level words.
For example, if you say "The tree was tall and swaying in the wind," the system might select a gesture of your hand moving up and down to represent the swaying motion, rather than just a generic hand movement. By tapping into the underlying meaning of the speech, the gestures become more natural and aligned with what you're actually saying.
This could be useful for things like animated characters, virtual assistants, or even robots, where you want the non-verbal communication to feel more human-like and coherent with the speech. It's an interesting step towards making computer-generated movement and body language feel more natural and meaningful.
Technical Explanation
The core of the "Semantic Gesticulator" is a retrieval-based approach to co-speech gesture synthesis. The system maintains a database of pre-recorded gesture clips, each annotated with semantic information about the underlying meaning and intent.
When given a new speech input, the system first extracts semantic representations using natural language processing techniques. It then uses these semantic representations to retrieve the most relevant gesture clips from the database. This allows the system to select gestures that are well-aligned with the specific words, concepts, and ideas being expressed in the speech.
Next, the system adapts the retrieved gesture clips to match the timing, rhythm, and prosody of the input speech. This is done through a series of neural network-based transformations that adjust factors like motion trajectories, hand shapes, and dynamics.
The key innovation is the use of semantics to guide both the retrieval and adaptation processes. By tapping into the underlying meaning rather than just surface-level text, the system is able to generate co-speech gestures that are more natural, expressive, and semantically coherent with the speech. This is in contrast to prior work that relied more on statistical patterns or rule-based heuristics.
The authors evaluate the "Semantic Gesticulator" through both quantitative metrics and human studies, demonstrating its ability to produce gestures that are perceived as more natural and meaningful compared to baseline approaches. They also show how the system can be applied to different use cases, like avatar animation and robot interaction.
Critical Analysis
The "Semantic Gesticulator" represents an interesting step forward in the field of co-speech gesture synthesis. By incorporating semantic information, the system is able to generate more natural and expressive gestures that are well-aligned with the underlying meaning of the speech.
That said, the authors acknowledge several limitations and areas for future work. For example, the current system relies on a pre-defined database of gesture clips, which may limit its flexibility and ability to generate truly novel gestures. There is also the question of how well the system would scale to more diverse and unconstrained speech inputs.
Additionally, while the human evaluation results are promising, it would be valuable to see the system tested in more realistic interactive scenarios, where the generated gestures need to coherently accompany an ongoing conversation.
Some other potential areas for improvement could include incorporating multimodal information beyond just speech (e.g., facial expressions, body posture), as well as exploring ways to learn the gesture-speech mapping in a more data-driven way, rather than relying solely on manual annotation.
Overall, the "Semantic Gesticulator" represents an important step forward, but there is still significant room for further research and development to realize the full potential of semantics-aware co-speech gesture synthesis.
Conclusion
The "Semantic Gesticulator" introduces a novel approach to co-speech gesture synthesis that leverages semantic information to generate more natural and meaningful gestures. By tapping into the underlying meaning of the speech, rather than just the surface-level text, the system is able to select and adapt gesture clips in a way that is well-aligned with the intent and content of the spoken language.
This work has important implications for applications like avatar animation, virtual assistants, and human-robot interaction, where the ability to produce coherent and expressive non-verbal communication is crucial for creating more natural and engaging experiences. As the field of multimodal AI continues to advance, the principles and techniques demonstrated in the "Semantic Gesticulator" will likely play an increasingly important role.
While the current system has some limitations, the overall approach represents an exciting step forward in the quest to endow artificial systems with more human-like communication capabilities. As the research continues, we can expect to see even more sophisticated and semantically-aware gesture synthesis systems emerge, further blurring the lines between natural and artificial forms of expression.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Semantic Gesticulator: Semantics-Aware Co-Speech Gesture Synthesis
Zeyi Zhang, Tenglong Ao, Yuyao Zhang, Qingzhe Gao, Chuan Lin, Baoquan Chen, Libin Liu
In this work, we present Semantic Gesticulator, a novel framework designed to synthesize realistic gestures accompanying speech with strong semantic correspondence. Semantically meaningful gestures are crucial for effective non-verbal communication, but such gestures often fall within the long tail of the distribution of natural human motion. The sparsity of these movements makes it challenging for deep learning-based systems, trained on moderately sized datasets, to capture the relationship between the movements and the corresponding speech semantics. To address this challenge, we develop a generative retrieval framework based on a large language model. This framework efficiently retrieves suitable semantic gesture candidates from a motion library in response to the input speech. To construct this motion library, we summarize a comprehensive list of commonly used semantic gestures based on findings in linguistics, and we collect a high-quality motion dataset encompassing both body and hand movements. We also design a novel GPT-based model with strong generalization capabilities to audio, capable of generating high-quality gestures that match the rhythm of speech. Furthermore, we propose a semantic alignment mechanism to efficiently align the retrieved semantic gestures with the GPT's output, ensuring the naturalness of the final animation. Our system demonstrates robustness in generating gestures that are rhythmically coherent and semantically explicit, as evidenced by a comprehensive collection of examples. User studies confirm the quality and human-likeness of our results, and show that our system outperforms state-of-the-art systems in terms of semantic appropriateness by a clear margin.
Read more5/20/2024
✨
0
SIGGesture: Generalized Co-Speech Gesture Synthesis via Semantic Injection with Large-Scale Pre-Training Diffusion Models
Qingrong Cheng, Xu Li, Xinghui Fu
The automated synthesis of high-quality 3D gestures from speech is of significant value in virtual humans and gaming. Previous methods focus on synthesizing gestures that are synchronized with speech rhythm, yet they frequently overlook the inclusion of semantic gestures. These are sparse and follow a long-tailed distribution across the gesture sequence, making them difficult to learn in an end-to-end manner. Moreover, generating gestures, rhythmically aligned with speech, faces a significant issue that cannot be generalized to in-the-wild speeches. To address these issues, we introduce SIGGesture, a novel diffusion-based approach for synthesizing realistic gestures that are of both high quality and semantically pertinent. Specifically, we firstly build a strong diffusion-based foundation model for rhythmical gesture synthesis by pre-training it on a collected large-scale dataset with pseudo labels. Secondly, we leverage the powerful generalization capabilities of Large Language Models (LLMs) to generate proper semantic gestures for the various speech content. Finally, we propose a semantic injection module to infuse semantic information into the synthesized results during diffusion reverse process. Extensive experiments demonstrate that the proposed SIGGesture significantly outperforms existing baselines and shows excellent generalization and controllability.
Read more5/24/2024
🗣️
0
GesGPT: Speech Gesture Synthesis With Text Parsing from GPT
Nan Gao, Zeyu Zhao, Zhi Zeng, Shuwu Zhang, Dongdong Weng, Yihua Bao
Gesture synthesis has gained significant attention as a critical research field, aiming to produce contextually appropriate and natural gestures corresponding to speech or textual input. Although deep learning-based approaches have achieved remarkable progress, they often overlook the rich semantic information present in the text, leading to less expressive and meaningful gestures. In this letter, we propose GesGPT, a novel approach to gesture generation that leverages the semantic analysis capabilities of large language models , such as ChatGPT. By capitalizing on the strengths of LLMs for text analysis, we adopt a controlled approach to generate and integrate professional gestures and base gestures through a text parsing script, resulting in diverse and meaningful gestures. Firstly, our approach involves the development of prompt principles that transform gesture generation into an intention classification problem using ChatGPT. We also conduct further analysis on emphasis words and semantic words to aid in gesture generation. Subsequently, we construct a specialized gesture lexicon with multiple semantic annotations, decoupling the synthesis of gestures into professional gestures and base gestures. Finally, we merge the professional gestures with base gestures. Experimental results demonstrate that GesGPT effectively generates contextually appropriate and expressive gestures.
Read more5/29/2024
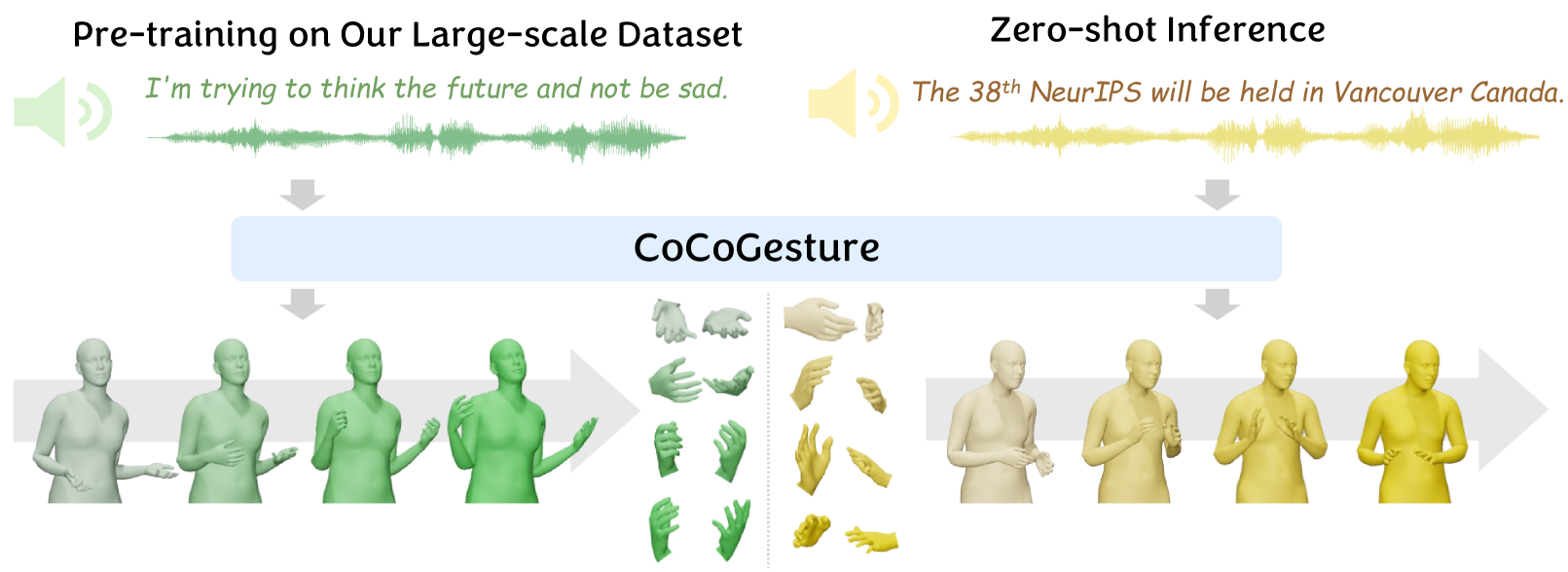
0
CoCoGesture: Toward Coherent Co-speech 3D Gesture Generation in the Wild
Xingqun Qi, Hengyuan Zhang, Yatian Wang, Jiahao Pan, Chen Liu, Peng Li, Xiaowei Chi, Mengfei Li, Qixun Zhang, Wei Xue, Shanghang Zhang, Wenhan Luo, Qifeng Liu, Yike Guo
Deriving co-speech 3D gestures has seen tremendous progress in virtual avatar animation. Yet, the existing methods often produce stiff and unreasonable gestures with unseen human speech inputs due to the limited 3D speech-gesture data. In this paper, we propose CoCoGesture, a novel framework enabling vivid and diverse gesture synthesis from unseen human speech prompts. Our key insight is built upon the custom-designed pretrain-fintune training paradigm. At the pretraining stage, we aim to formulate a large generalizable gesture diffusion model by learning the abundant postures manifold. Therefore, to alleviate the scarcity of 3D data, we first construct a large-scale co-speech 3D gesture dataset containing more than 40M meshed posture instances across 4.3K speakers, dubbed GES-X. Then, we scale up the large unconditional diffusion model to 1B parameters and pre-train it to be our gesture experts. At the finetune stage, we present the audio ControlNet that incorporates the human voice as condition prompts to guide the gesture generation. Here, we construct the audio ControlNet through a trainable copy of our pre-trained diffusion model. Moreover, we design a novel Mixture-of-Gesture-Experts (MoGE) block to adaptively fuse the audio embedding from the human speech and the gesture features from the pre-trained gesture experts with a routing mechanism. Such an effective manner ensures audio embedding is temporal coordinated with motion features while preserving the vivid and diverse gesture generation. Extensive experiments demonstrate that our proposed CoCoGesture outperforms the state-of-the-art methods on the zero-shot speech-to-gesture generation. The dataset will be publicly available at: https://mattie-e.github.io/GES-X/
Read more5/28/2024