SIGGesture: Generalized Co-Speech Gesture Synthesis via Semantic Injection with Large-Scale Pre-Training Diffusion Models

0
✨
Sign in to get full access
Overview
- This paper introduces a novel approach called SIGGesture for synthesizing realistic and semantically relevant co-speech gestures.
- Previous methods have focused on synchronizing gestures with speech rhythm, but often overlooked semantic gestures that are sparse and difficult to learn.
- SIGGesture uses a diffusion-based foundation model for rhythmic gesture synthesis, combined with the generalization capabilities of Large Language Models (LLMs) to generate appropriate semantic gestures.
- The paper demonstrates that SIGGesture significantly outperforms existing baselines and shows excellent generalization and controllability.
Plain English Explanation
The paper presents a new system called SIGGesture that can automatically generate high-quality 3D hand and body gestures to accompany speech. This is useful for creating more natural and expressive virtual humans in applications like video games and animations.
Previous methods have tried to make the gestures match the rhythm and timing of the speech, but they often missed important "semantic" gestures - those that convey meaning or ideas related to the content of the speech. These semantic gestures are tricky to learn because they are relatively rare and don't follow a clear pattern.
To address this, the SIGGesture system uses a two-pronged approach. First, it builds a strong foundation model using a diffusion-based neural network trained on a large dataset to generate gestures that are well-synchronized with the speech. Then, it leverages powerful language models to identify the appropriate semantic gestures for the content of the speech. Finally, it combines these two components to produce gestures that are both rhythmically aligned and semantically relevant.
The researchers show that this SIGGesture system outperforms previous methods and is able to generate high-quality, versatile gestures that can be used in a variety of speech contexts.
Technical Explanation
The core of the SIGGesture system is a diffusion-based foundation model that is pre-trained on a large dataset to generate rhythmic gestures synchronized with speech. Diffusion models are a type of generative neural network that work by gradually adding noise to data and then learning to reverse the process to generate new samples.
To capture semantic gestures, the researchers leverage the powerful language understanding capabilities of Large Language Models (LLMs). These models are trained on vast amounts of text data and can recognize the meaning and context of language. The SIGGesture system uses an LLM to identify the appropriate semantic gestures for the content of the input speech.
Finally, the researchers propose a "semantic injection" module that infuses the semantic gesture information into the diffusion-based gesture synthesis process. This allows the system to generate gestures that are both rhythmically aligned and semantically relevant to the speech.
Extensive experiments demonstrate that the SIGGesture system significantly outperforms existing co-speech gesture generation approaches in terms of both objective metrics and human evaluation. The system also shows strong generalization capabilities, able to produce high-quality gestures for a variety of speech content.
Critical Analysis
The researchers acknowledge several limitations and areas for further research. For example, the semantic gestures are still relatively sparse in the training data, making them challenging to learn. Additionally, the system does not currently consider the emotional or contextual aspects of the speech, which could further improve the realism and relevance of the generated gestures.
One potential issue to consider is the reliance on LLMs, which can sometimes exhibit biases or inconsistencies in their language understanding. This could lead to inappropriate or inaccurate semantic gestures being generated in certain cases.
Additionally, the paper does not provide a detailed analysis of the computational costs or real-time performance of the SIGGesture system, which could be important considerations for practical applications. Further research may be needed to optimize the system for efficient deployment.
Overall, the SIGGesture approach represents a significant advance in the field of co-speech gesture synthesis, addressing important limitations of previous methods. With continued refinement and exploration of additional contextual factors, this line of research could lead to even more naturalistic and expressive virtual agents and avatars.
Conclusion
The SIGGesture system introduced in this paper represents an important step forward in the automated synthesis of high-quality, semantically relevant 3D gestures from speech. By combining a diffusion-based foundation model for rhythmic gesture generation with the language understanding capabilities of Large Language Models, the researchers have created a system that can produce gestures that are both well-synchronized and semantically pertinent.
The demonstrated improvements over existing baselines and the system's strong generalization capabilities suggest that this approach could have significant applications in virtual humans, gaming, and other areas where realistic and expressive co-speech gestures are desirable. As the researchers continue to refine the system and explore additional contextual factors, the potential for even more naturalistic and engaging virtual agents and avatars is promising.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
SIGGesture: Generalized Co-Speech Gesture Synthesis via Semantic Injection with Large-Scale Pre-Training Diffusion Models
Qingrong Cheng, Xu Li, Xinghui Fu
The automated synthesis of high-quality 3D gestures from speech is of significant value in virtual humans and gaming. Previous methods focus on synthesizing gestures that are synchronized with speech rhythm, yet they frequently overlook the inclusion of semantic gestures. These are sparse and follow a long-tailed distribution across the gesture sequence, making them difficult to learn in an end-to-end manner. Moreover, generating gestures, rhythmically aligned with speech, faces a significant issue that cannot be generalized to in-the-wild speeches. To address these issues, we introduce SIGGesture, a novel diffusion-based approach for synthesizing realistic gestures that are of both high quality and semantically pertinent. Specifically, we firstly build a strong diffusion-based foundation model for rhythmical gesture synthesis by pre-training it on a collected large-scale dataset with pseudo labels. Secondly, we leverage the powerful generalization capabilities of Large Language Models (LLMs) to generate proper semantic gestures for the various speech content. Finally, we propose a semantic injection module to infuse semantic information into the synthesized results during diffusion reverse process. Extensive experiments demonstrate that the proposed SIGGesture significantly outperforms existing baselines and shows excellent generalization and controllability.
Read more5/24/2024

0
Semantic Gesticulator: Semantics-Aware Co-Speech Gesture Synthesis
Zeyi Zhang, Tenglong Ao, Yuyao Zhang, Qingzhe Gao, Chuan Lin, Baoquan Chen, Libin Liu
In this work, we present Semantic Gesticulator, a novel framework designed to synthesize realistic gestures accompanying speech with strong semantic correspondence. Semantically meaningful gestures are crucial for effective non-verbal communication, but such gestures often fall within the long tail of the distribution of natural human motion. The sparsity of these movements makes it challenging for deep learning-based systems, trained on moderately sized datasets, to capture the relationship between the movements and the corresponding speech semantics. To address this challenge, we develop a generative retrieval framework based on a large language model. This framework efficiently retrieves suitable semantic gesture candidates from a motion library in response to the input speech. To construct this motion library, we summarize a comprehensive list of commonly used semantic gestures based on findings in linguistics, and we collect a high-quality motion dataset encompassing both body and hand movements. We also design a novel GPT-based model with strong generalization capabilities to audio, capable of generating high-quality gestures that match the rhythm of speech. Furthermore, we propose a semantic alignment mechanism to efficiently align the retrieved semantic gestures with the GPT's output, ensuring the naturalness of the final animation. Our system demonstrates robustness in generating gestures that are rhythmically coherent and semantically explicit, as evidenced by a comprehensive collection of examples. User studies confirm the quality and human-likeness of our results, and show that our system outperforms state-of-the-art systems in terms of semantic appropriateness by a clear margin.
Read more5/20/2024
0
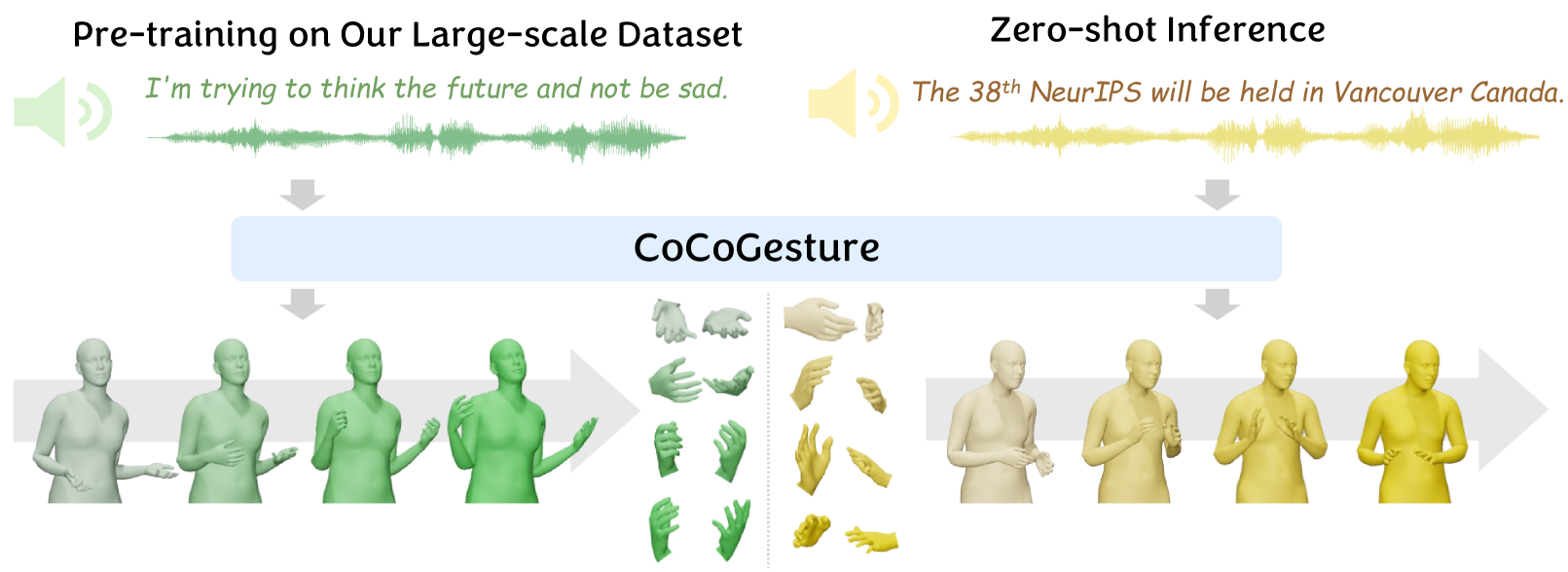
CoCoGesture: Toward Coherent Co-speech 3D Gesture Generation in the Wild
Xingqun Qi, Hengyuan Zhang, Yatian Wang, Jiahao Pan, Chen Liu, Peng Li, Xiaowei Chi, Mengfei Li, Qixun Zhang, Wei Xue, Shanghang Zhang, Wenhan Luo, Qifeng Liu, Yike Guo
Deriving co-speech 3D gestures has seen tremendous progress in virtual avatar animation. Yet, the existing methods often produce stiff and unreasonable gestures with unseen human speech inputs due to the limited 3D speech-gesture data. In this paper, we propose CoCoGesture, a novel framework enabling vivid and diverse gesture synthesis from unseen human speech prompts. Our key insight is built upon the custom-designed pretrain-fintune training paradigm. At the pretraining stage, we aim to formulate a large generalizable gesture diffusion model by learning the abundant postures manifold. Therefore, to alleviate the scarcity of 3D data, we first construct a large-scale co-speech 3D gesture dataset containing more than 40M meshed posture instances across 4.3K speakers, dubbed GES-X. Then, we scale up the large unconditional diffusion model to 1B parameters and pre-train it to be our gesture experts. At the finetune stage, we present the audio ControlNet that incorporates the human voice as condition prompts to guide the gesture generation. Here, we construct the audio ControlNet through a trainable copy of our pre-trained diffusion model. Moreover, we design a novel Mixture-of-Gesture-Experts (MoGE) block to adaptively fuse the audio embedding from the human speech and the gesture features from the pre-trained gesture experts with a routing mechanism. Such an effective manner ensures audio embedding is temporal coordinated with motion features while preserving the vivid and diverse gesture generation. Extensive experiments demonstrate that our proposed CoCoGesture outperforms the state-of-the-art methods on the zero-shot speech-to-gesture generation. The dataset will be publicly available at: https://mattie-e.github.io/GES-X/
Read more5/28/2024
📈
0
Audio is all in one: speech-driven gesture synthetics using WavLM pre-trained model
Fan Zhang, Naye Ji, Fuxing Gao, Siyuan Zhao, Zhaohan Wang, Shunman Li
The generation of co-speech gestures for digital humans is an emerging area in the field of virtual human creation. Prior research has made progress by using acoustic and semantic information as input and adopting classify method to identify the person's ID and emotion for driving co-speech gesture generation. However, this endeavour still faces significant challenges. These challenges go beyond the intricate interplay between co-speech gestures, speech acoustic, and semantics; they also encompass the complexities associated with personality, emotion, and other obscure but important factors. This paper introduces diffmotion-v2, a speech-conditional diffusion-based and non-autoregressive transformer-based generative model with WavLM pre-trained model. It can produce individual and stylized full-body co-speech gestures only using raw speech audio, eliminating the need for complex multimodal processing and manually annotated. Firstly, considering that speech audio not only contains acoustic and semantic features but also conveys personality traits, emotions, and more subtle information related to accompanying gestures, we pioneer the adaptation of WavLM, a large-scale pre-trained model, to extract low-level and high-level audio information. Secondly, we introduce an adaptive layer norm architecture in the transformer-based layer to learn the relationship between speech information and accompanying gestures. Extensive subjective evaluation experiments are conducted on the Trinity, ZEGGS, and BEAT datasets to confirm the WavLM and the model's ability to synthesize natural co-speech gestures with various styles.
Read more4/16/2024