Revisiting a Pain in the Neck: Semantic Phrase Processing Benchmark for Language Models

0
⚙️
Sign in to get full access
Overview
- Introduces LexBench, a comprehensive evaluation suite to test language models (LMs) on 10 semantic phrase processing tasks
- Examines the general semantic phrase (lexical collocation) and three fine-grained semantic phrases: idiomatic expression, noun compound, and verbal construction
- Evaluates the performance of 15 LMs across model architectures and parameter scales in classification, extraction, and interpretation tasks
- Validates the scaling law and finds that larger models perform better than smaller ones in most tasks
- Investigates few-shot LMs and finds they lag behind vanilla fine-tuned models in semantic relation categorization
- Finds that strong models' performance is comparable to human level in semantic phrase processing
Plain English Explanation
The researchers developed a new benchmark called LexBench to test how well language models (LMs) can understand different types of semantic phrases, which are groups of words that have a specific meaning together. Unlike previous studies, LexBench looks at both general semantic phrases (like common word combinations) and more specific ones (like idiomatic expressions, noun compounds, and verbal constructions).
The researchers used LexBench to evaluate 15 different LMs, looking at how they performed on classification, extraction, and interpretation tasks related to these semantic phrases. They found that, as expected, larger LMs generally did better than smaller ones. However, they also discovered that few-shot LMs (LMs trained on very little data) still lagged behind vanilla fine-tuned models when it came to categorizing semantic relationships.
Interestingly, the researchers found that the performance of the strongest LMs was comparable to human-level understanding of semantic phrases. This suggests that LMs are getting quite good at comprehending these types of language constructs.
Overall, the LexBench benchmark and the researchers' findings can help guide future work on improving language models' abilities to understand the nuanced meanings of different types of semantic phrases.
Technical Explanation
The paper introduces LexBench, a new evaluation framework for assessing language models' (LMs') abilities to process semantic phrases. Unlike prior work, LexBench covers both general semantic phrases (i.e., lexical collocations) and three specific types: idiomatic expressions, noun compounds, and verbal constructions.
Using LexBench, the researchers evaluated 15 LMs across different architectures and parameter scales on classification, extraction, and interpretation tasks related to these semantic phrases. The key findings are:
- Scaling law validation: Larger LMs generally outperform smaller ones, confirming the scaling law.
- Few-shot learning investigation: Few-shot LMs still lag behind vanilla fine-tuned models in semantic relation categorization tasks.
- Human-level performance: Strong LMs achieve performance comparable to humans in semantic phrase processing.
The researchers make their LexBench source code and data publicly available to support future research on improving LMs' semantic phrase comprehension capabilities.
Critical Analysis
The paper provides a comprehensive evaluation of LMs' abilities to process different types of semantic phrases, which is an important aspect of language understanding. The LexBench benchmark fills a gap in the literature by considering a broader range of semantic phrase constructs beyond just lexical collocations.
However, the paper does not delve into potential limitations or caveats of the LexBench framework itself. For example, the selected tasks and datasets may not fully capture the complexity and nuances of semantic phrase processing in real-world language use. Additionally, the human evaluation is limited in scope and could be expanded to gain deeper insights.
Further research could also investigate the underlying mechanisms by which LMs process semantic phrases, beyond just evaluating their performance. Understanding the models' reasoning and strategies could lead to more targeted improvements in this area of language understanding.
Conclusion
The LexBench benchmark provides a valuable tool for evaluating language models' capabilities in semantic phrase processing, a crucial aspect of language understanding. The paper's findings validate the scaling law, highlight the challenges of few-shot learning, and demonstrate that state-of-the-art LMs can achieve human-level performance in this domain.
These insights can guide future research aimed at improving the general semantic understanding of language models, which has important implications for various natural language processing applications. By making LexBench publicly available, the researchers have created an opportunity for the broader community to build upon this work and advance the field of language modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
Revisiting a Pain in the Neck: Semantic Phrase Processing Benchmark for Language Models
Yang Liu, Melissa Xiaohui Qin, Hongming Li, Chao Huang
We introduce LexBench, a comprehensive evaluation suite enabled to test language models (LMs) on ten semantic phrase processing tasks. Unlike prior studies, it is the first work to propose a framework from the comparative perspective to model the general semantic phrase (i.e., lexical collocation) and three fine-grained semantic phrases, including idiomatic expression, noun compound, and verbal construction. Thanks to ourbenchmark, we assess the performance of 15 LMs across model architectures and parameter scales in classification, extraction, and interpretation tasks. Through the experiments, we first validate the scaling law and find that, as expected, large models excel better than the smaller ones in most tasks. Second, we investigate further through the scaling semantic relation categorization and find that few-shot LMs still lag behind vanilla fine-tuned models in the task. Third, through human evaluation, we find that the performance of strong models is comparable to the human level regarding semantic phrase processing. Our benchmarking findings can serve future research aiming to improve the generic capability of LMs on semantic phrase comprehension. Our source code and data are available at https://github.com/jacklanda/LexBench
Read more5/7/2024

0
Beyond Benchmarking: A New Paradigm for Evaluation and Assessment of Large Language Models
Jin Liu, Qingquan Li, Wenlong Du
In current benchmarks for evaluating large language models (LLMs), there are issues such as evaluation content restriction, untimely updates, and lack of optimization guidance. In this paper, we propose a new paradigm for the measurement of LLMs: Benchmarking-Evaluation-Assessment. Our paradigm shifts the location of LLM evaluation from the examination room to the hospital. Through conducting a physical examination on LLMs, it utilizes specific task-solving as the evaluation content, performs deep attribution of existing problems within LLMs, and provides recommendation for optimization.
Read more7/11/2024

0
PhonologyBench: Evaluating Phonological Skills of Large Language Models
Ashima Suvarna, Harshita Khandelwal, Nanyun Peng
Phonology, the study of speech's structure and pronunciation rules, is a critical yet often overlooked component in Large Language Model (LLM) research. LLMs are widely used in various downstream applications that leverage phonology such as educational tools and poetry generation. Moreover, LLMs can potentially learn imperfect associations between orthographic and phonological forms from the training data. Thus, it is imperative to benchmark the phonological skills of LLMs. To this end, we present PhonologyBench, a novel benchmark consisting of three diagnostic tasks designed to explicitly test the phonological skills of LLMs in English: grapheme-to-phoneme conversion, syllable counting, and rhyme word generation. Despite having no access to speech data, LLMs showcased notable performance on the PhonologyBench tasks. However, we observe a significant gap of 17% and 45% on Rhyme Word Generation and Syllable counting, respectively, when compared to humans. Our findings underscore the importance of studying LLM performance on phonological tasks that inadvertently impact real-world applications. Furthermore, we encourage researchers to choose LLMs that perform well on the phonological task that is closely related to the downstream application since we find that no single model consistently outperforms the others on all the tasks.
Read more4/8/2024
0
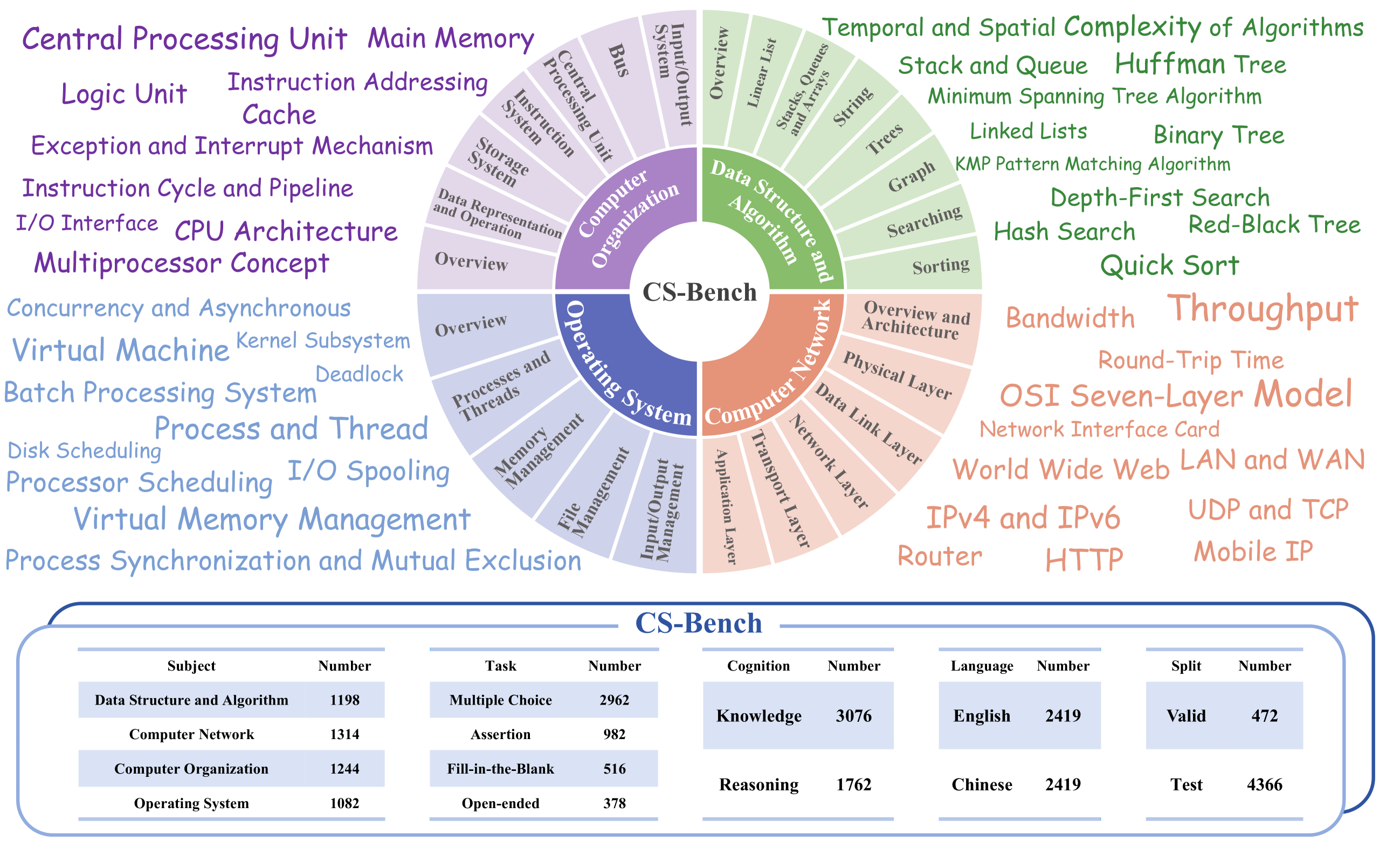
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
Read more6/14/2024