A Mathematical Theory for Learning Semantic Languages by Abstract Learners
2404.07009
0
0
Abstract
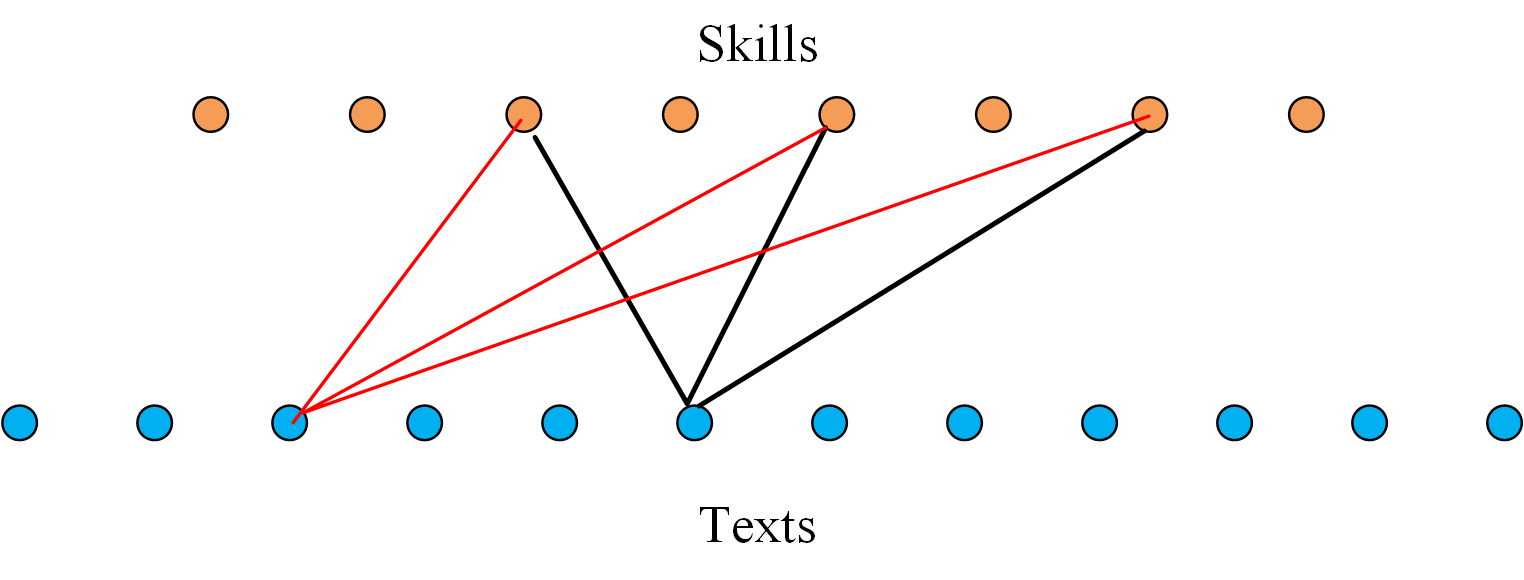
Recent advances in Large Language Models (LLMs) have demonstrated the emergence of capabilities (learned skills) when the number of system parameters and the size of training data surpass certain thresholds. The exact mechanisms behind such phenomena are not fully understood and remain a topic of active research. Inspired by the skill-text bipartite graph model proposed by Arora and Goyal for modeling semantic languages, we develop a mathematical theory to explain the emergence of learned skills, taking the learning (or training) process into account. Our approach models the learning process for skills in the skill-text bipartite graph as an iterative decoding process in Low-Density Parity Check (LDPC) codes and Irregular Repetition Slotted ALOHA (IRSA). Using density evolution analysis, we demonstrate the emergence of learned skills when the ratio of the number of training texts to the number of skills exceeds a certain threshold. Our analysis also yields a scaling law for testing errors relative to this ratio. Upon completion of the training, the association of learned skills can also be acquired to form a skill association graph. We use site percolation analysis to derive the conditions for the existence of a giant component in the skill association graph. Our analysis can also be extended to the setting with a hierarchy of skills, where a fine-tuned model is built upon a foundation model. It is also applicable to the setting with multiple classes of skills and texts. As an important application, we propose a method for semantic compression and discuss its connections to semantic communication.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a mathematical theory for how abstract learners can acquire semantic languages.
- It explores the ability of learners to infer the meaning of words and language through exposure to data, without relying on pre-defined semantic representations.
- The paper introduces a formal framework for modeling this process and analyzes the conditions under which learners can successfully learn semantic languages.
Plain English Explanation
This research paper presents a mathematical theory for how abstract learners, without any pre-existing knowledge, can learn the meaning of words and the semantic structure of a language simply by being exposed to data. The key idea is that learners can infer the meaning of words and the overall structure of a language through statistical patterns in the data, without relying on any pre-defined semantic representations.
The paper introduces a formal framework for modeling this process of learning semantic languages. It analyzes the conditions under which these abstract learners can successfully learn the semantic structure of a language, including factors like the complexity of the language and the amount of data available to the learner.
The findings suggest that under certain circumstances, learners can indeed acquire sophisticated semantic languages purely through exposure to data, without any built-in understanding of meaning. This has important implications for understanding the evolution of language and the ability of artificial systems, like language models, to develop semantic understanding in a similar way.
Technical Explanation
The paper proposes a mathematical framework for modeling the ability of abstract learners to acquire semantic languages through exposure to data. It introduces the concept of a "semantic language", which is defined as a set of words and their associated meanings, along with rules for combining those words into meaningful sentences.
The key innovation is the idea that learners can infer the semantic structure of a language without relying on any pre-defined representations of meaning. Instead, the learners observe statistical patterns in the data and use that information to build up an understanding of the underlying semantics.
The paper analyzes the conditions under which this learning process can succeed, considering factors like the complexity of the language, the size of the dataset available to the learner, and the learning algorithms employed. Through mathematical analysis and simulations, the authors demonstrate that under certain circumstances, learners can indeed acquire sophisticated semantic languages purely through exposure to data.
This work has important implications for understanding the evolution of language and the potential for artificial systems like language models to develop semantic understanding in a similar way, without relying on pre-defined knowledge about the meaning of words and language.
Critical Analysis
The paper presents a well-formulated and technically rigorous approach to modeling the acquisition of semantic languages by abstract learners. The authors have clearly put a lot of thought into the mathematical framework and have done a thorough analysis of the key factors that influence the learning process.
That said, there are a few potential limitations and areas for further research that are worth considering. First, the paper focuses on relatively simple semantic languages, and it's unclear how well the framework would scale to more complex, real-world languages. Additionally, the learning algorithms used in the simulations, while well-justified, may not fully capture the nuances of how humans and artificial systems actually learn language.
Another potential concern is the degree to which the findings can be generalized. The paper analyzes specific mathematical models and makes certain assumptions about the nature of the data and the learning process. It would be valuable to see further research exploring the robustness of the conclusions and the applicability of the framework to a wider range of language learning scenarios.
Overall, this paper represents an important contribution to the understanding of semantic language acquisition and has significant implications for both cognitive science and the development of more advanced language-based artificial intelligence systems. However, as with any research, there are opportunities for further exploration and refinement of the ideas presented.
Conclusion
This paper introduces a novel mathematical framework for modeling how abstract learners can acquire the semantic structure of a language through exposure to data, without relying on pre-defined representations of meaning. The authors demonstrate that under certain conditions, learners can successfully infer the semantics of a language solely based on statistical patterns in the input data.
The findings have important implications for our understanding of language evolution and the potential for artificial systems, such as advanced language models, to develop semantic understanding in a similar way. While the paper presents a rigorous technical approach, there are also opportunities for further research to explore the limitations of the framework and expand its applicability to more complex real-world language scenarios.
Overall, this work represents a significant contribution to the field of language acquisition and has the potential to inform both cognitive science and the development of more sophisticated language-based AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
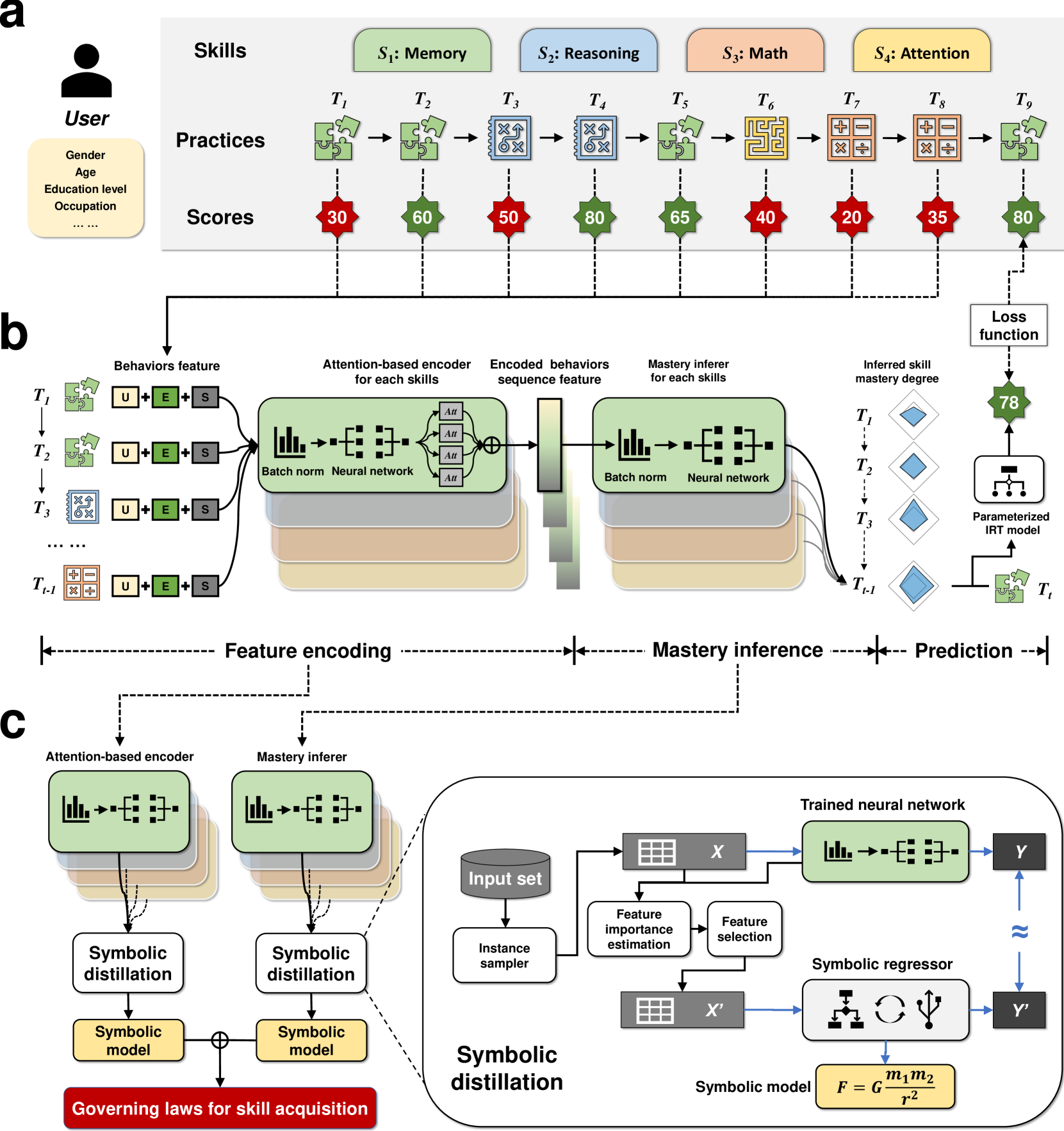
Automated discovery of symbolic laws governing skill acquisition from naturally occurring data
Sannyuya Liu, Qing Li, Xiaoxuan Shen, Jianwen Sun, Zongkai Yang
0
0
Skill acquisition is a key area of research in cognitive psychology as it encompasses multiple psychological processes. The laws discovered under experimental paradigms are controversial and lack generalizability. This paper aims to unearth the laws of skill learning from large-scale training log data. A two-stage algorithm was developed to tackle the issues of unobservable cognitive states and algorithmic explosion in searching. Initially a deep learning model is employed to determine the learner's cognitive state and assess the feature importance. Subsequently, symbolic regression algorithms are utilized to parse the neural network model into algebraic equations. The experimental results of simulated data demonstrate that the proposed algorithm can accurately restore various preset laws within a certain range of noise, in continues feedback setting. Application of proposed method to Lumosity training data demonstrates superior performance compared to traditional and latest models in terms of fitness. The results indicate the discovery of two new forms of skill acquisition laws, while some previous findings have been reaffirmed.
4/9/2024
📈
A Mathematical Model for Curriculum Learning for Parities
Elisabetta Cornacchia, Elchanan Mossel
0
0
Curriculum learning (CL) - training using samples that are generated and presented in a meaningful order - was introduced in the machine learning context around a decade ago. While CL has been extensively used and analysed empirically, there has been very little mathematical justification for its advantages. We introduce a CL model for learning the class of k-parities on d bits of a binary string with a neural network trained by stochastic gradient descent (SGD). We show that a wise choice of training examples involving two or more product distributions, allows to reduce significantly the computational cost of learning this class of functions, compared to learning under the uniform distribution. Furthermore, we show that for another class of functions - namely the `Hamming mixtures' - CL strategies involving a bounded number of product distributions are not beneficial.
4/24/2024
📈
An exactly solvable model for emergence and scaling laws
Yoonsoo Nam, Nayara Fonseca, Seok Hyeong Lee, Ard Louis
0
0
Deep learning models can exhibit what appears to be a sudden ability to solve a new problem as training time ($T$), training data ($D$), or model size ($N$) increases, a phenomenon known as emergence. In this paper, we present a framework where each new ability (a skill) is represented as a basis function. We solve a simple multi-linear model in this skill-basis, finding analytic expressions for the emergence of new skills, as well as for scaling laws of the loss with training time, data size, model size, and optimal compute ($C$). We compare our detailed calculations to direct simulations of a two-layer neural network trained on multitask sparse parity, where the tasks in the dataset are distributed according to a power-law. Our simple model captures, using a single fit parameter, the sigmoidal emergence of multiple new skills as training time, data size or model size increases in the neural network.
4/29/2024
🤖
Contextual Categorization Enhancement through LLMs Latent-Space
Zineddine Bettouche, Anas Safi, Andreas Fischer
0
0
Managing the semantic quality of the categorization in large textual datasets, such as Wikipedia, presents significant challenges in terms of complexity and cost. In this paper, we propose leveraging transformer models to distill semantic information from texts in the Wikipedia dataset and its associated categories into a latent space. We then explore different approaches based on these encodings to assess and enhance the semantic identity of the categories. Our graphical approach is powered by Convex Hull, while we utilize Hierarchical Navigable Small Worlds (HNSWs) for the hierarchical approach. As a solution to the information loss caused by the dimensionality reduction, we modulate the following mathematical solution: an exponential decay function driven by the Euclidean distances between the high-dimensional encodings of the textual categories. This function represents a filter built around a contextual category and retrieves items with a certain Reconsideration Probability (RP). Retrieving high-RP items serves as a tool for database administrators to improve data groupings by providing recommendations and identifying outliers within a contextual framework.
4/26/2024