Adversarial Attacks and Defense for Conversation Entailment Task
2405.00289
0
0
🔄
Abstract
As the deployment of NLP systems in critical applications grows, ensuring the robustness of large language models (LLMs) against adversarial attacks becomes increasingly important. Large language models excel in various NLP tasks but remain vulnerable to low-cost adversarial attacks. Focusing on the domain of conversation entailment, where multi-turn dialogues serve as premises to verify hypotheses, we fine-tune a transformer model to accurately discern the truthfulness of these hypotheses. Adversaries manipulate hypotheses through synonym swapping, aiming to deceive the model into making incorrect predictions. To counteract these attacks, we implemented innovative fine-tuning techniques and introduced an embedding perturbation loss method to significantly bolster the model's robustness. Our findings not only emphasize the importance of defending against adversarial attacks in NLP but also highlight the real-world implications, suggesting that enhancing model robustness is critical for reliable NLP applications.
Create account to get full access
Overview
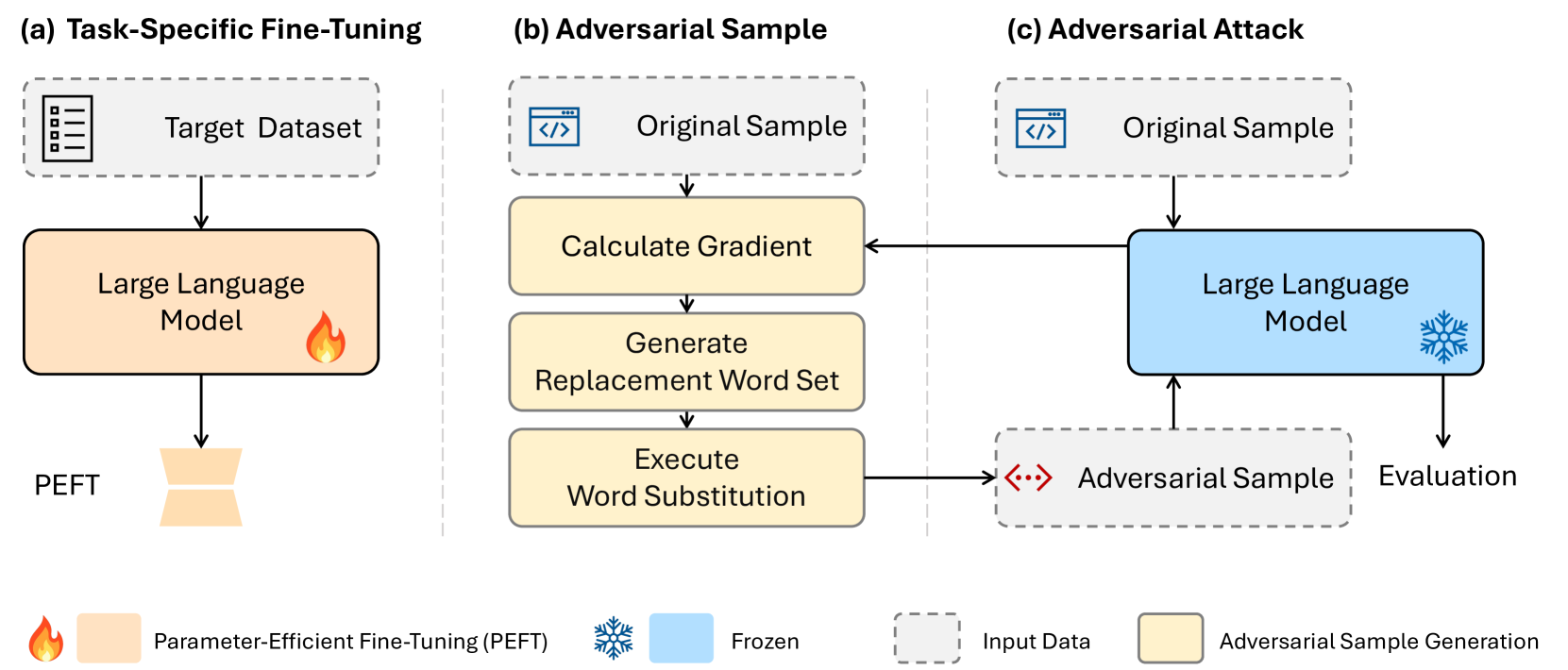
- Large language models (LLMs) are powerful, but they are vulnerable to adversarial attacks that can fool the model at low cost.
- Defending against these attacks is an important problem.
- This work treats adversarial attack results as a new domain for the model and aims to improve the model's robustness on this domain.
- The specific task is conversation entailment, where the model predicts whether a given hypothesis about a multi-turn dialogue is true or false.
- The adversary attacks the hypothesis to make the model predict incorrectly.
- The researchers apply synonym-swapping as the attack method and implement fine-tuning strategies and a new "embedding perturbation loss" to improve the model's robustness.
Plain English Explanation
Large language models (LLMs) are computer programs that can understand and generate human-like text. They have become incredibly powerful at various language-related tasks, like answering questions or summarizing documents. However, these models have a weakness - they can be tricked quite easily.
Imagine you have a smart assistant that can help you with all sorts of tasks. But if someone whispered the wrong instructions in its ear, it might do something completely different than what you asked. That's kind of like what can happen with LLMs.
In this research, the team focused on a particular language task called "conversation entailment." The idea is that the model is given a multi-part conversation, and then has to decide whether a given statement or "hypothesis" about that conversation is true or false.
The researchers wanted to make this model more robust, or resistant to being tricked. So they simulated attacks where the hypothesis is slightly modified in a sneaky way, to try to fool the model into making the wrong prediction. They used a technique called "synonym-swapping" - replacing words with similar ones, but in a way that changes the meaning.
To defend against these attacks, the team tried out different strategies for "fine-tuning" the model - essentially, retraining it on the adversarial examples to help it learn to recognize and overcome them. They also proposed a new technique called "embedding perturbation loss" that seems to further boost the model's robustness.
The overall goal is to make these powerful language models more reliable and trustworthy, so they can be safely used in real-world applications without as much risk of being manipulated or deceived. This is an important area of research as LLMs become more widely adopted.
Technical Explanation
The researchers framed the problem of defending large language models (LLMs) against adversarial attacks as improving the model's robustness on this new "domain" of adversarial examples. They focused on the task of conversation entailment, where the model is given a multi-turn dialogue as the premise and must predict whether a given hypothesis about the dialogue is true or false.
The adversary's goal is to attack the hypothesis in a way that fools the model into making the wrong prediction. The researchers used synonym-swapping as the attack method, replacing words in the hypothesis with synonyms to subtly change the meaning.
To improve the model's robustness, the team implemented several fine-tuning strategies, including adversarial training on the adversarial examples. They also proposed a new technique called "embedding perturbation loss" that encourages the model to learn representations that are more resilient to small changes in the input.
Through experiments, the researchers demonstrated the effectiveness of their defense approaches in improving the model's performance on the adversarial examples, making it more resistant to these stealthy attacks compared to the baseline model.
The paper highlights the importance of this work in the context of real-world adversarial attacks on NLP systems, where models need to be robust to subtle manipulations of the input that could have significant consequences.
Critical Analysis
The paper presents a thoughtful approach to improving the robustness of large language models against adversarial attacks in the context of conversation entailment. The use of synonym-swapping as the attack method is well-justified, as it represents a realistic and stealthy way to fool the model.
The researchers' framing of the problem as improving the model's performance on a new "domain" of adversarial examples is a clever and effective way to approach the challenge. The proposed fine-tuning strategies and the novel "embedding perturbation loss" seem promising, though the authors acknowledge the need for further investigation into the underlying mechanisms and the generalizability of these techniques.
One potential area for further exploration is the impact of the attack method on the model's performance on the original, non-adversarial examples. The paper does not provide a comprehensive analysis of this trade-off, which could be an important consideration in real-world deployments.
Additionally, the researchers could have delved deeper into the limitations of their approach, such as the dependence on access to the model's internals (e.g., embeddings) or the potential for more sophisticated adversarial attacks that go beyond simple synonym-swapping. Exploring these aspects could further strengthen the critical analysis and provide a more well-rounded understanding of the method's strengths and weaknesses.
Conclusion
This research addresses an important problem in the field of natural language processing (NLP): improving the robustness of large language models against adversarial attacks. By treating adversarial examples as a new domain for the model, the researchers developed effective fine-tuning strategies and a novel "embedding perturbation loss" technique to enhance the model's performance on this challenging task.
The work has significant implications for the real-world deployment of NLP systems, where the ability to withstand stealthy and low-cost attacks is crucial. As large language models become more ubiquitous, ensuring their reliability and trustworthiness will be a key priority for researchers and developers alike.
While the paper demonstrates promising results, further research is needed to fully understand the limitations and generalizability of the proposed approaches. Nonetheless, this work represents an important step forward in the ongoing efforts to make NLP models more robust and secure, paving the way for more reliable and trustworthy language-based applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Adversarial Attacks on Large Language Models in Medicine
Yifan Yang, Qiao Jin, Furong Huang, Zhiyong Lu
0
0
The integration of Large Language Models (LLMs) into healthcare applications offers promising advancements in medical diagnostics, treatment recommendations, and patient care. However, the susceptibility of LLMs to adversarial attacks poses a significant threat, potentially leading to harmful outcomes in delicate medical contexts. This study investigates the vulnerability of LLMs to two types of adversarial attacks in three medical tasks. Utilizing real-world patient data, we demonstrate that both open-source and proprietary LLMs are susceptible to manipulation across multiple tasks. This research further reveals that domain-specific tasks demand more adversarial data in model fine-tuning than general domain tasks for effective attack execution, especially for more capable models. We discover that while integrating adversarial data does not markedly degrade overall model performance on medical benchmarks, it does lead to noticeable shifts in fine-tuned model weights, suggesting a potential pathway for detecting and countering model attacks. This research highlights the urgent need for robust security measures and the development of defensive mechanisms to safeguard LLMs in medical applications, to ensure their safe and effective deployment in healthcare settings.
6/19/2024
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
0
0
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
5/7/2024

MultiAgent Collaboration Attack: Investigating Adversarial Attacks in Large Language Model Collaborations via Debate
Alfonso Amayuelas, Xianjun Yang, Antonis Antoniades, Wenyue Hua, Liangming Pan, William Wang
0
0
Large Language Models (LLMs) have shown exceptional results on current benchmarks when working individually. The advancement in their capabilities, along with a reduction in parameter size and inference times, has facilitated the use of these models as agents, enabling interactions among multiple models to execute complex tasks. Such collaborations offer several advantages, including the use of specialized models (e.g. coding), improved confidence through multiple computations, and enhanced divergent thinking, leading to more diverse outputs. Thus, the collaborative use of language models is expected to grow significantly in the coming years. In this work, we evaluate the behavior of a network of models collaborating through debate under the influence of an adversary. We introduce pertinent metrics to assess the adversary's effectiveness, focusing on system accuracy and model agreement. Our findings highlight the importance of a model's persuasive ability in influencing others. Additionally, we explore inference-time methods to generate more compelling arguments and evaluate the potential of prompt-based mitigation as a defensive strategy.
6/27/2024
🔮
Semantic Stealth: Adversarial Text Attacks on NLP Using Several Methods
Roopkatha Dey, Aivy Debnath, Sayak Kumar Dutta, Kaustav Ghosh, Arijit Mitra, Arghya Roy Chowdhury, Jaydip Sen
0
0
In various real-world applications such as machine translation, sentiment analysis, and question answering, a pivotal role is played by NLP models, facilitating efficient communication and decision-making processes in domains ranging from healthcare to finance. However, a significant challenge is posed to the robustness of these natural language processing models by text adversarial attacks. These attacks involve the deliberate manipulation of input text to mislead the predictions of the model while maintaining human interpretability. Despite the remarkable performance achieved by state-of-the-art models like BERT in various natural language processing tasks, they are found to remain vulnerable to adversarial perturbations in the input text. In addressing the vulnerability of text classifiers to adversarial attacks, three distinct attack mechanisms are explored in this paper using the victim model BERT: BERT-on-BERT attack, PWWS attack, and Fraud Bargain's Attack (FBA). Leveraging the IMDB, AG News, and SST2 datasets, a thorough comparative analysis is conducted to assess the effectiveness of these attacks on the BERT classifier model. It is revealed by the analysis that PWWS emerges as the most potent adversary, consistently outperforming other methods across multiple evaluation scenarios, thereby emphasizing its efficacy in generating adversarial examples for text classification. Through comprehensive experimentation, the performance of these attacks is assessed and the findings indicate that the PWWS attack outperforms others, demonstrating lower runtime, higher accuracy, and favorable semantic similarity scores. The key insight of this paper lies in the assessment of the relative performances of three prevalent state-of-the-art attack mechanisms.
4/9/2024