Semantically-Prompted Language Models Improve Visual Descriptions
2306.06077
0
0
💬
Abstract
Language-vision models like CLIP have made significant strides in vision tasks, such as zero-shot image classification (ZSIC). However, generating specific and expressive visual descriptions remains challenging; descriptions produced by current methods are often ambiguous and lacking in granularity. To tackle these issues, we propose V-GLOSS: Visual Glosses, a novel method built upon two key ideas. The first is Semantic Prompting, which conditions a language model on structured semantic knowledge. The second is a new contrastive algorithm that elicits fine-grained distinctions between similar concepts. With both ideas, we demonstrate that V-GLOSS improves visual descriptions and achieves strong results in the zero-shot setting on general and fine-grained image-classification datasets, including ImageNet, STL-10, FGVC Aircraft, and Flowers 102. Moreover, these descriptive capabilities contribute to enhancing image-generation performance. Finally, we introduce a quality-tested silver dataset with descriptions generated with V-GLOSS for all ImageNet classes.
Create account to get full access
Overview
- Language-vision models like CLIP have made significant progress in vision tasks like zero-shot image classification.
- However, generating specific and expressive visual descriptions remains challenging, with current methods producing ambiguous and lacking descriptions.
- To address these issues, the researchers propose a new method called V-GLOSS, which builds on two key ideas: Semantic Prompting and a new contrastive algorithm.
- V-GLOSS is shown to improve visual descriptions and achieve strong results in zero-shot settings on various image classification datasets.
- The method also contributes to enhancing image generation performance, and the researchers introduce a quality-tested dataset of ImageNet class descriptions generated with V-GLOSS.
Plain English Explanation
Imagine you have a friend who's great at recognizing different objects in images, but when you ask them to describe what they see, their descriptions are vague and not very detailed. That's the challenge the researchers are trying to address with their new method, V-GLOSS.
V-GLOSS builds on two key ideas. The first is Semantic Prompting, which means conditioning a language model (like the one that powers chatbots) on structured semantic knowledge. This helps the model understand the relationships between different concepts and produce more precise and informative descriptions.
The second idea is a new contrasting algorithm, which helps the model identify fine-grained differences between similar concepts. This allows it to generate more specific and expressive descriptions, rather than just broad, generic ones.
By combining these two ideas, the researchers show that V-GLOSS can generate much better visual descriptions than existing methods. It can also help with tasks like zero-shot image classification, where the model can classify images into categories it hasn't seen before.
Additionally, V-GLOSS's improved description capabilities can also enhance the performance of image generation systems, which are used to create new images from scratch. Finally, the researchers have created a high-quality dataset of ImageNet class descriptions, which can be used to further develop and test visual description models.
Technical Explanation
The core of V-GLOSS is its use of Semantic Prompting and a new contrastive algorithm. Semantic Prompting conditions the language model on structured semantic knowledge, like the relationships between different concepts. This helps the model generate more precise and informative descriptions, rather than just broad, generic ones.
The contrastive algorithm focuses on eliciting fine-grained distinctions between similar concepts. This allows the model to identify and describe subtle differences, which is crucial for generating expressive visual descriptions.
The researchers evaluate V-GLOSS on several zero-shot image classification datasets, including ImageNet, STL-10, FGVC Aircraft, and Flowers 102. They demonstrate that V-GLOSS outperforms existing methods in both zero-shot classification and the quality of the generated descriptions.
Additionally, the researchers show that V-GLOSS's descriptive capabilities can enhance image generation performance. They also introduce a high-quality dataset of ImageNet class descriptions, which can be used to further develop and evaluate visual description models.
Critical Analysis
The researchers acknowledge that while V-GLOSS represents a significant step forward in visual description, there is still room for improvement. The descriptions generated by the model, while more expressive than previous methods, may still lack some of the nuance and contextual understanding that humans can bring to visual interpretation.
Additionally, the researchers note that the contrastive algorithm used in V-GLOSS is computationally expensive and may limit the scalability of the approach. Further research may be needed to develop more efficient techniques for eliciting fine-grained distinctions between similar concepts.
It's also worth considering the potential biases and limitations of the training data used to develop V-GLOSS. The ImageNet dataset, while comprehensive, may not be fully representative of the diversity of visual experiences and concepts in the real world. This could lead to biases or blindspots in the model's understanding and description capabilities.
Overall, V-GLOSS represents an important advancement in the field of language-vision integration, but continued research and development will be needed to fully realize the potential of these models to generate rich, contextual, and nuanced visual descriptions.
Conclusion
The V-GLOSS method proposed in this paper represents a significant step forward in the ability of language-vision models to generate specific and expressive visual descriptions. By incorporating Semantic Prompting and a novel contrastive algorithm, the researchers have demonstrated that it is possible to elicit more fine-grained distinctions and produce more informative descriptions than previous approaches.
The strong performance of V-GLOSS on zero-shot image classification tasks, as well as its ability to enhance image generation capabilities, suggest that this work has important implications for a range of computer vision and multimodal AI applications. Additionally, the introduction of a high-quality dataset of ImageNet class descriptions will help drive further advancements in this field.
While there are still challenges to overcome, the core ideas behind V-GLOSS point the way towards a future where language-vision models can serve as more powerful and versatile tools for understanding, describing, and interacting with the visual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Vision-Language Consistency Guided Multi-modal Prompt Learning for Blind AI Generated Image Quality Assessment
Jun Fu, Wei Zhou, Qiuping Jiang, Hantao Liu, Guangtao Zhai
0
0
Recently, textual prompt tuning has shown inspirational performance in adapting Contrastive Language-Image Pre-training (CLIP) models to natural image quality assessment. However, such uni-modal prompt learning method only tunes the language branch of CLIP models. This is not enough for adapting CLIP models to AI generated image quality assessment (AGIQA) since AGIs visually differ from natural images. In addition, the consistency between AGIs and user input text prompts, which correlates with the perceptual quality of AGIs, is not investigated to guide AGIQA. In this letter, we propose vision-language consistency guided multi-modal prompt learning for blind AGIQA, dubbed CLIP-AGIQA. Specifically, we introduce learnable textual and visual prompts in language and vision branches of CLIP models, respectively. Moreover, we design a text-to-image alignment quality prediction task, whose learned vision-language consistency knowledge is used to guide the optimization of the above multi-modal prompts. Experimental results on two public AGIQA datasets demonstrate that the proposed method outperforms state-of-the-art quality assessment models. The source code is available at https://github.com/JunFu1995/CLIP-AGIQA.
6/26/2024

The Neglected Tails in Vision-Language Models
Shubham Parashar, Zhiqiu Lin, Tian Liu, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, Shu Kong
0
0
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
5/24/2024
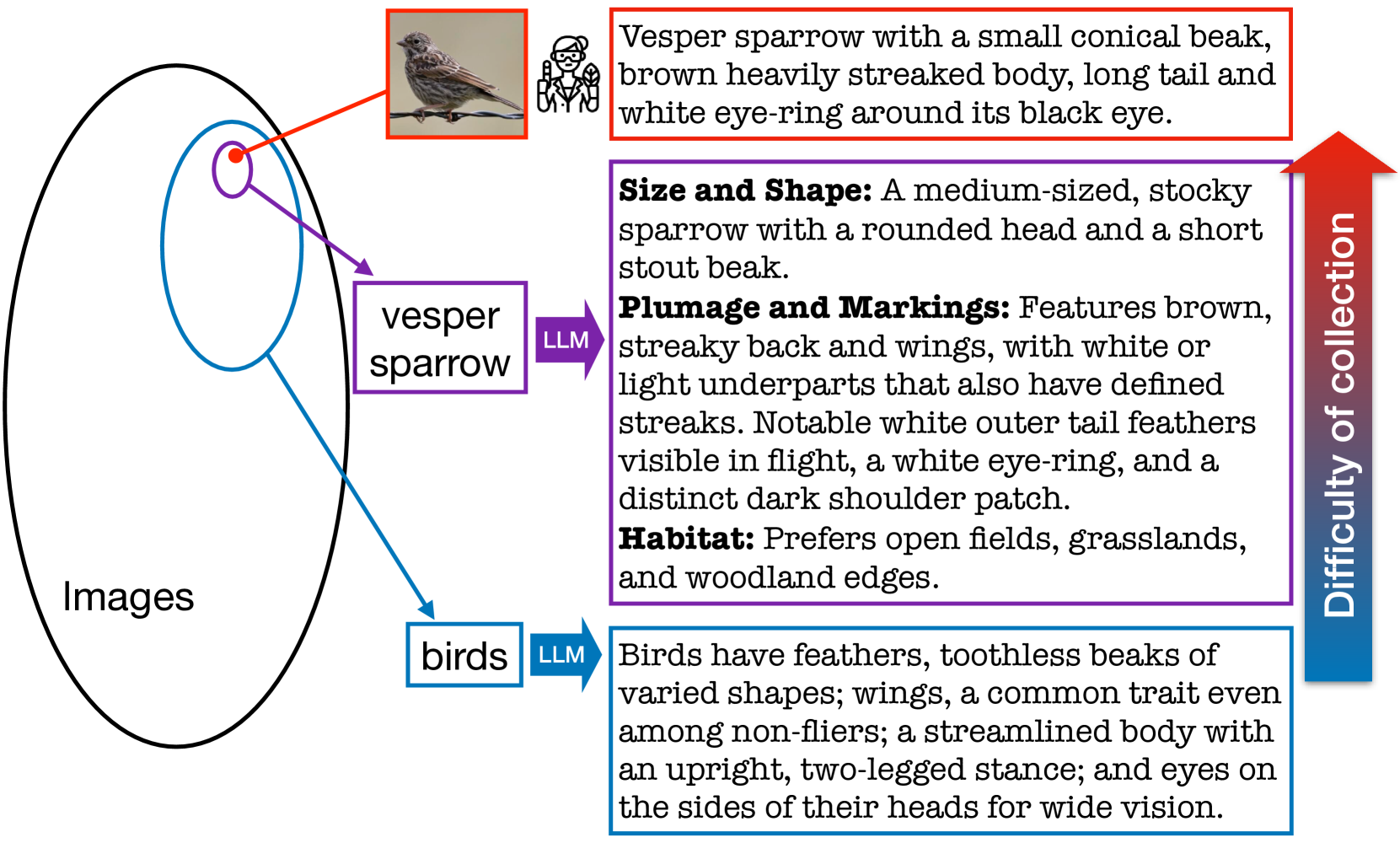
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Oindrila Saha, Grant Van Horn, Subhransu Maji
0
0
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this bag-level image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We release the benchmark, consisting of 14 datasets at https://github.com/cvl-umass/AdaptCLIPZS , which will contribute to future research in zero-shot recognition.
4/5/2024

Unsupervised Image Prior via Prompt Learning and CLIP Semantic Guidance for Low-Light Image Enhancement
Igor Morawski, Kai He, Shusil Dangi, Winston H. Hsu
0
0
Currently, low-light conditions present a significant challenge for machine cognition. In this paper, rather than optimizing models by assuming that human and machine cognition are correlated, we use zero-reference low-light enhancement to improve the performance of downstream task models. We propose to improve the zero-reference low-light enhancement method by leveraging the rich visual-linguistic CLIP prior without any need for paired or unpaired normal-light data, which is laborious and difficult to collect. We propose a simple but effective strategy to learn prompts that help guide the enhancement method and experimentally show that the prompts learned without any need for normal-light data improve image contrast, reduce over-enhancement, and reduce noise over-amplification. Next, we propose to reuse the CLIP model for semantic guidance via zero-shot open vocabulary classification to optimize low-light enhancement for task-based performance rather than human visual perception. We conduct extensive experimental results showing that the proposed method leads to consistent improvements across various datasets regarding task-based performance and compare our method against state-of-the-art methods, showing favorable results across various low-light datasets.
5/21/2024