Semantics-Preserved Distortion for Personal Privacy Protection in Information Management

0
📶
Sign in to get full access
Overview
- Machine learning, particularly deep learning, has significantly impacted information management in recent years.
- While previous approaches have tried to restrict models from learning and memorizing sensitive information from raw texts, this paper suggests a more linguistically-grounded approach to distort texts while maintaining semantic integrity.
- The paper introduces a novel metric called Neighboring Distribution Divergence to assess the preservation of semantic meaning during distortion, and presents two distinct frameworks for semantic-preserving distortion: a generative approach and a substitutive approach.
- Evaluations across various NLP tasks, including named entity recognition, constituency parsing, and machine reading comprehension, affirm the plausibility and efficacy of the distortion technique in personal privacy protection.
- The paper also tests the method against attribute attacks in three privacy-focused NLP assignments and explores privacy protection in a medical information management scenario.
Plain English Explanation
In recent years, machine learning models, especially deep learning, have had a significant impact on how we manage information. While previous methods have tried to prevent these models from learning and remembering sensitive information from raw text data, this paper proposes a new approach that distorts the text in a way that still preserves the overall meaning.
The key innovation in this paper is the use of a new metric called Neighboring Distribution Divergence, which the researchers use to measure how well the distorted text maintains its original meaning. Based on this metric, the paper presents two different ways to distort the text while keeping the meaning intact: a generative approach and a substitutive approach.
To test the effectiveness of these distortion methods, the researchers evaluated them on a variety of natural language processing (NLP) tasks, such as identifying named entities, parsing sentence structure, and answering reading comprehension questions. The results show that their distortion techniques can effectively protect personal privacy without significantly impacting the performance of these NLP models.
The paper also specifically looks at how the distortion methods hold up against certain types of attacks aimed at extracting sensitive information. Additionally, the researchers explore how their approach could be used to protect medical information, demonstrating its practical applications.
Technical Explanation
The paper introduces two distinct frameworks for semantic-preserving distortion:
-
Generative Approach: This approach uses a generative model to create new text that preserves the semantic meaning of the original text. The model is trained to generate distorted text that maintains the overall meaning while obfuscating sensitive information.
-
Substitutive Approach: This approach replaces certain words or phrases in the original text with semantically similar but less sensitive alternatives. The substitutions are made in a way that minimizes the impact on the overall meaning of the text.
To evaluate the effectiveness of these distortion techniques, the researchers conducted experiments across various NLP tasks, including named entity recognition, constituency parsing, and machine reading comprehension. The results showed that the distorted text maintained semantic integrity while effectively protecting personal privacy.
Additionally, the paper tested the distortion methods against attribute attacks in three privacy-focused NLP assignments. The findings suggest that the data-based improvement approach used in this paper is simpler and more effective than structural improvement approaches.
Furthermore, the researchers explored the application of their privacy protection method in a medical information management scenario. The results demonstrate that the distortion technique can effectively limit the memorization of sensitive medical data, highlighting its practical usefulness.
Critical Analysis
The paper presents a novel and linguistically-grounded approach to text distortion for privacy protection, which is a significant contribution to the field of information management. The use of Neighboring Distribution Divergence as a metric to assess semantic preservation is a thoughtful and well-designed aspect of the research.
However, the paper does not fully address the potential for the distortion methods to introduce unintended biases or artifacts into the text. While the experiments show the techniques maintain overall performance on NLP tasks, there may be more subtle changes in linguistic characteristics or statistical patterns that could impact downstream applications.
Additionally, the paper does not explore the scalability or computational efficiency of the proposed frameworks, which could be important considerations for real-world deployment. The generative and substitutive approaches may have different trade-offs in terms of computation, storage, and performance that could influence their practical applicability.
Further research could also investigate the robustness of the distortion methods against more sophisticated attacks or adversarial examples specifically designed to circumvent the privacy protection mechanisms. Exploring the transferability of the distortion techniques to new domains or tasks would also be valuable.
Conclusion
This paper presents a novel, linguistically-grounded approach to text distortion for personal privacy protection in the context of machine learning and information management. By introducing a novel metric to assess semantic preservation and proposing two distinct distortion frameworks, the researchers have developed a promising technique that can effectively protect sensitive information while maintaining the overall meaning and utility of the text data.
The evaluations across various NLP tasks and privacy-focused assignments demonstrate the plausibility and efficacy of the proposed method, and the exploration of a medical information management scenario highlights its practical applicability. As machine learning continues to have a significant impact on information management, this research contributes an important step towards balancing the benefits of data-driven insights with the imperative of personal privacy protection.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Semantics-Preserved Distortion for Personal Privacy Protection in Information Management
Jiajia Li, Lu Yang, Letian Peng, Shitou Zhang, Ping Wang, Zuchao Li, Hai Zhao
In recent years, machine learning - particularly deep learning - has significantly impacted the field of information management. While several strategies have been proposed to restrict models from learning and memorizing sensitive information from raw texts, this paper suggests a more linguistically-grounded approach to distort texts while maintaining semantic integrity. To this end, we leverage Neighboring Distribution Divergence, a novel metric to assess the preservation of semantic meaning during distortion. Building on this metric, we present two distinct frameworks for semantic-preserving distortion: a generative approach and a substitutive approach. Our evaluations across various tasks, including named entity recognition, constituency parsing, and machine reading comprehension, affirm the plausibility and efficacy of our distortion technique in personal privacy protection. We also test our method against attribute attacks in three privacy-focused assignments within the NLP domain, and the findings underscore the simplicity and efficacy of our data-based improvement approach over structural improvement approaches. Moreover, we explore privacy protection in a specific medical information management scenario, showing our method effectively limits sensitive data memorization, underscoring its practicality.
Read more7/10/2024

0
Characterizing Stereotypical Bias from Privacy-preserving Pre-Training
Stefan Arnold, Rene Grobner, Annika Schreiner
Differential Privacy (DP) can be applied to raw text by exploiting the spatial arrangement of words in an embedding space. We investigate the implications of such text privatization on Language Models (LMs) and their tendency towards stereotypical associations. Since previous studies documented that linguistic proficiency correlates with stereotypical bias, one could assume that techniques for text privatization, which are known to degrade language modeling capabilities, would cancel out undesirable biases. By testing BERT models trained on texts containing biased statements primed with varying degrees of privacy, our study reveals that while stereotypical bias generally diminishes when privacy is tightened, text privatization does not uniformly equate to diminishing bias across all social domains. This highlights the need for careful diagnosis of bias in LMs that undergo text privatization.
Read more7/2/2024
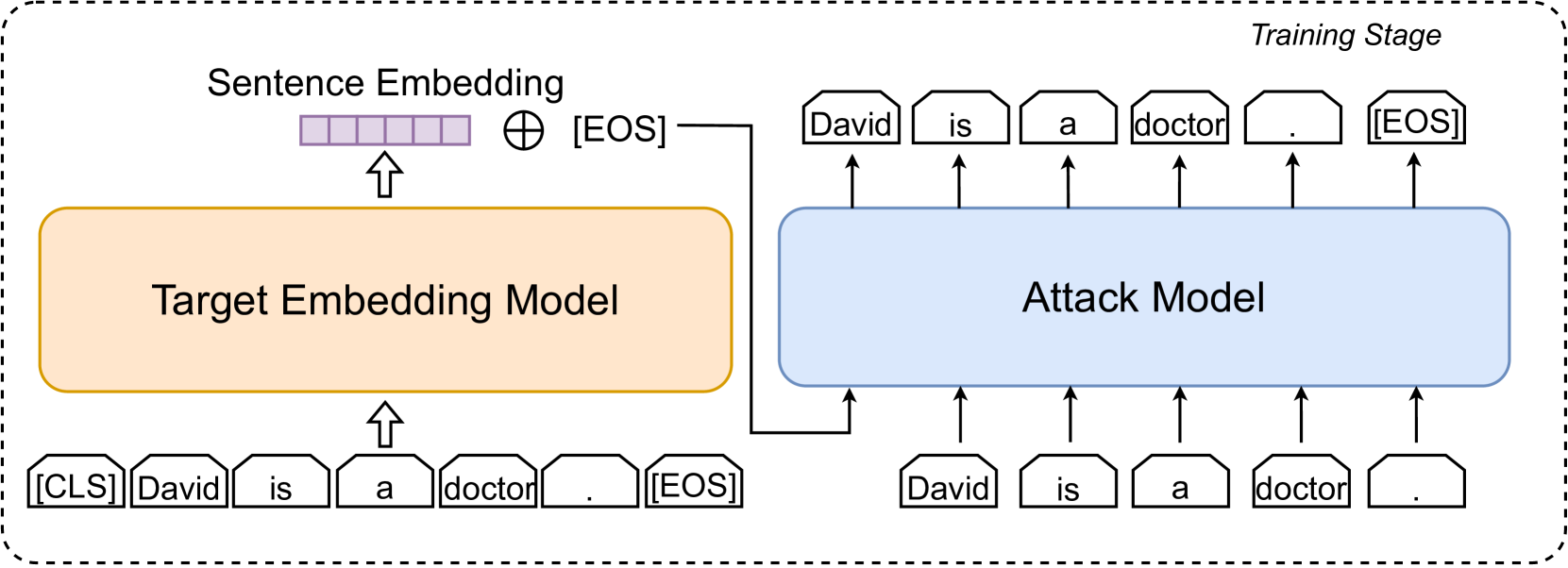
0
Understanding Privacy Risks of Embeddings Induced by Large Language Models
Zhihao Zhu, Ninglu Shao, Defu Lian, Chenwang Wu, Zheng Liu, Yi Yang, Enhong Chen
Large language models (LLMs) show early signs of artificial general intelligence but struggle with hallucinations. One promising solution to mitigate these hallucinations is to store external knowledge as embeddings, aiding LLMs in retrieval-augmented generation. However, such a solution risks compromising privacy, as recent studies experimentally showed that the original text can be partially reconstructed from text embeddings by pre-trained language models. The significant advantage of LLMs over traditional pre-trained models may exacerbate these concerns. To this end, we investigate the effectiveness of reconstructing original knowledge and predicting entity attributes from these embeddings when LLMs are employed. Empirical findings indicate that LLMs significantly improve the accuracy of two evaluated tasks over those from pre-trained models, regardless of whether the texts are in-distribution or out-of-distribution. This underscores a heightened potential for LLMs to jeopardize user privacy, highlighting the negative consequences of their widespread use. We further discuss preliminary strategies to mitigate this risk.
Read more4/26/2024
🔎
0
IDT: Dual-Task Adversarial Attacks for Privacy Protection
Pedro Faustini, Shakila Mahjabin Tonni, Annabelle McIver, Qiongkai Xu, Mark Dras
Natural language processing (NLP) models may leak private information in different ways, including membership inference, reconstruction or attribute inference attacks. Sensitive information may not be explicit in the text, but hidden in underlying writing characteristics. Methods to protect privacy can involve using representations inside models that are demonstrated not to detect sensitive attributes or -- for instance, in cases where users might not trust a model, the sort of scenario of interest here -- changing the raw text before models can have access to it. The goal is to rewrite text to prevent someone from inferring a sensitive attribute (e.g. the gender of the author, or their location by the writing style) whilst keeping the text useful for its original intention (e.g. the sentiment of a product review). The few works tackling this have focused on generative techniques. However, these often create extensively different texts from the original ones or face problems such as mode collapse. This paper explores a novel adaptation of adversarial attack techniques to manipulate a text to deceive a classifier w.r.t one task (privacy) whilst keeping the predictions of another classifier trained for another task (utility) unchanged. We propose IDT, a method that analyses predictions made by auxiliary and interpretable models to identify which tokens are important to change for the privacy task, and which ones should be kept for the utility task. We evaluate different datasets for NLP suitable for different tasks. Automatic and human evaluations show that IDT retains the utility of text, while also outperforming existing methods when deceiving a classifier w.r.t privacy task.
Read more7/1/2024