Synthetic Query Generation for Privacy-Preserving Deep Retrieval Systems using Differentially Private Language Models
2305.05973
0
0
🛸
Abstract
We address the challenge of ensuring differential privacy (DP) guarantees in training deep retrieval systems. Training these systems often involves the use of contrastive-style losses, which are typically non-per-example decomposable, making them difficult to directly DP-train with since common techniques require per-example gradients. To address this issue, we propose an approach that prioritizes ensuring query privacy prior to training a deep retrieval system. Our method employs DP language models (LMs) to generate private synthetic queries representative of the original data. These synthetic queries can be used in downstream retrieval system training without compromising privacy. Our approach demonstrates a significant enhancement in retrieval quality compared to direct DP-training, all while maintaining query-level privacy guarantees. This work highlights the potential of harnessing LMs to overcome limitations in standard DP-training methods.
Create account to get full access
Overview
- This paper addresses the challenge of ensuring differential privacy (DP) guarantees when training deep retrieval systems.
- Deep retrieval systems often use contrastive-style losses, which are difficult to train while maintaining DP.
- The authors propose an approach that prioritizes query-level privacy by using differentially private language models (LMs) to generate synthetic queries for downstream retrieval system training.
- This method demonstrates improved retrieval quality compared to direct DP-training while preserving query-level privacy.
Plain English Explanation
The paper tackles the issue of protecting user privacy when training deep learning models for search and retrieval systems. These models often use a technique called "contrastive learning," which can make it challenging to ensure the privacy of individual data points. To solve this problem, the researchers developed a method that first generates synthetic search queries using differentially private language models. These private synthetic queries can then be used to train the retrieval system without compromising the privacy of the original data.
The key insight is that by separating the privacy-preserving step from the system training, the researchers are able to maintain strong privacy guarantees while still achieving high-quality retrieval performance. This approach overcomes the limitations of direct DP-training methods, which can struggle with the non-decomposable nature of contrastive losses.
The authors demonstrate that their method outperforms direct DP-training in terms of retrieval quality, all while ensuring the privacy of the original search queries. This work highlights how language models can be harnessed to address challenges in conventional differential privacy techniques.
Technical Explanation
The paper presents a novel approach for ensuring differential privacy (DP) guarantees when training deep retrieval systems. These systems often employ contrastive-style losses, which are typically non-per-example decomposable, making them difficult to directly DP-train using common techniques that require per-example gradients.
To address this issue, the authors propose a two-stage approach. First, they use differentially private language models to generate synthetic queries that are representative of the original data while preserving query-level privacy. These synthetic queries are then used to train the downstream retrieval system.
The key innovation is that by separating the privacy-preserving step from the system training, the researchers are able to overcome the limitations of direct DP-training methods that struggle with non-decomposable loss functions. The authors demonstrate that their approach leads to significant improvements in retrieval quality compared to direct DP-training, all while maintaining strong query-level privacy guarantees.
The authors also explore the use of prompt-tuned language models to further enhance the quality of the generated synthetic queries, showcasing the potential of large language models in overcoming limitations in standard DP-training methods.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach for ensuring differential privacy in deep retrieval systems. The authors' decision to prioritize query-level privacy and leverage language models to generate synthetic data is a clever solution to the challenges posed by contrastive-style losses.
One potential limitation of the approach is that it relies on the quality of the generated synthetic queries. While the authors demonstrate promising results, the performance of the retrieval system may be subject to the fidelity of the synthetic data. Further research could explore ways to optimize the query generation process or investigate the impact of different DP-preserving language model architectures.
Additionally, the paper does not address potential biases or fairness implications that may arise from the use of language models in the privacy-preserving stage. As these models can reflect societal biases, it would be valuable to assess the downstream impact on the fairness of the retrieval system.
Overall, this work highlights the importance of considering privacy in the design of deep retrieval systems and showcases the potential of language models in overcoming limitations of traditional differential privacy techniques. The authors' approach provides a solid foundation for further research in this area.
Conclusion
This paper presents a novel approach for ensuring differential privacy in the training of deep retrieval systems. By leveraging differentially private language models to generate synthetic queries, the authors are able to overcome the challenges posed by non-decomposable contrastive-style losses, which are commonly used in these systems.
The key innovation is the separation of the privacy-preserving step from the downstream retrieval system training. This allows the researchers to maintain strong query-level privacy guarantees while achieving significant improvements in retrieval quality compared to direct DP-training methods.
The authors' work highlights the potential of harnessing language models to address limitations in standard differential privacy techniques. As deep learning continues to be adopted in sensitive domains, this research provides a valuable contribution toward developing privacy-preserving solutions for complex machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
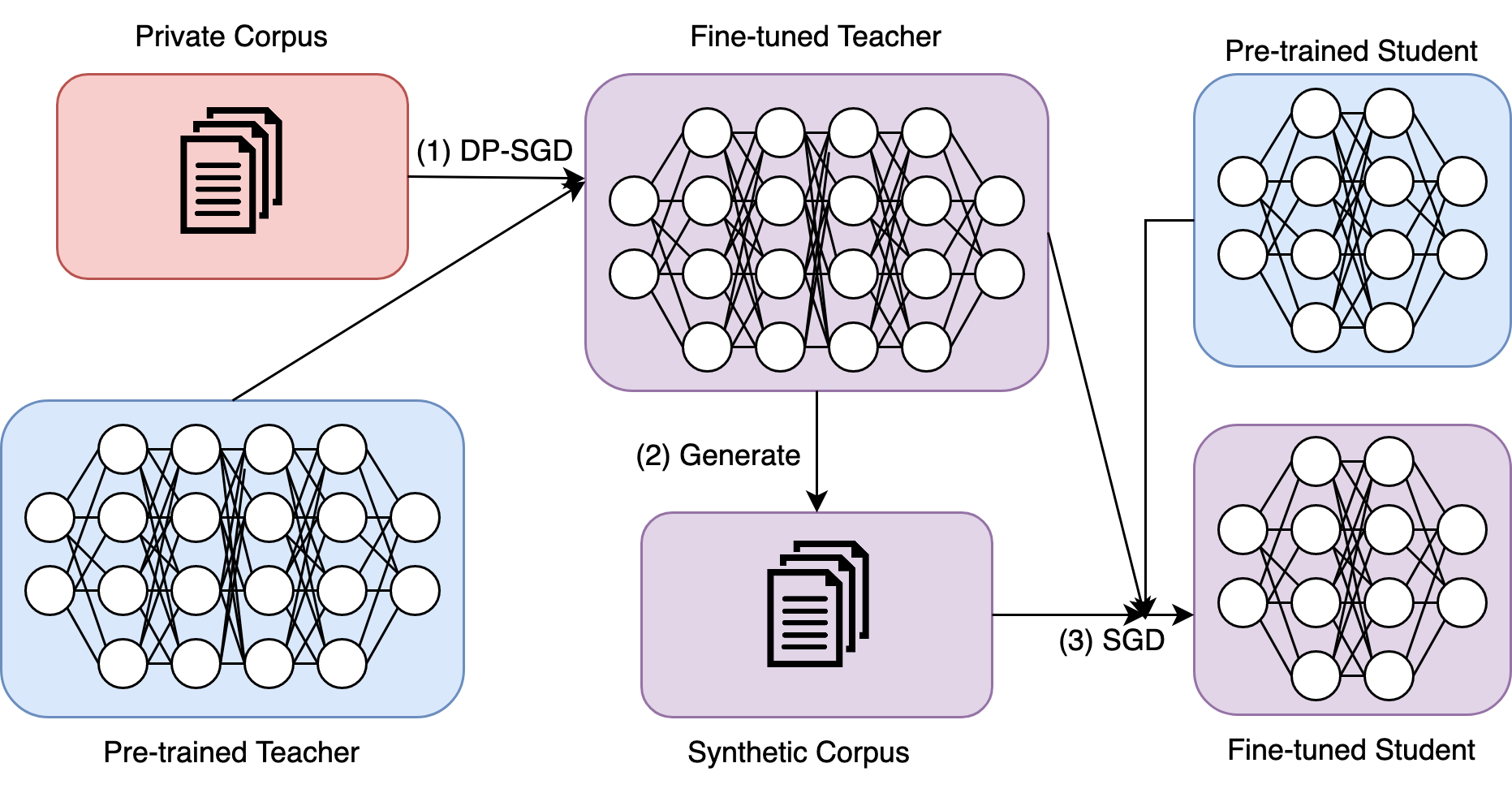
Differentially Private Knowledge Distillation via Synthetic Text Generation
James Flemings, Murali Annavaram
0
0
Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy puts pressure on practitioners to train LLMs with Differential Privacy (DP) on private data. Concurrently, the exponential growth in parameter size of LLMs necessitates model compression before deployment of LLMs on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, simultaneously applying both schemes can compound the utility degradation. To this end, we propose DistilDP: a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private teacher LLM. The knowledge of a teacher LLM is transferred onto the student in two ways: one way from the synthetic data itself -- the hard labels, and the other way by the output distribution of the teacher evaluated on the synthetic data -- the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by aligning the hidden representations between both. Our experimental results demonstrate that DistilDP can substantially improve the utility over existing baselines, at least $9.0$ PPL on the Big Patent dataset, with strong privacy parameters, $epsilon=2$. These promising results progress privacy-preserving compression of autoregressive LLMs. Our code can be accessed here: https://github.com/james-flemings/dp_compress.
6/6/2024

Mind the Privacy Unit! User-Level Differential Privacy for Language Model Fine-Tuning
Lynn Chua, Badih Ghazi, Yangsibo Huang, Pritish Kamath, Ravi Kumar, Daogao Liu, Pasin Manurangsi, Amer Sinha, Chiyuan Zhang
0
0
Large language models (LLMs) have emerged as powerful tools for tackling complex tasks across diverse domains, but they also raise privacy concerns when fine-tuned on sensitive data due to potential memorization. While differential privacy (DP) offers a promising solution by ensuring models are 'almost indistinguishable' with or without any particular privacy unit, current evaluations on LLMs mostly treat each example (text record) as the privacy unit. This leads to uneven user privacy guarantees when contributions per user vary. We therefore study user-level DP motivated by applications where it necessary to ensure uniform privacy protection across users. We present a systematic evaluation of user-level DP for LLM fine-tuning on natural language generation tasks. Focusing on two mechanisms for achieving user-level DP guarantees, Group Privacy and User-wise DP-SGD, we investigate design choices like data selection strategies and parameter tuning for the best privacy-utility tradeoff.
7/4/2024
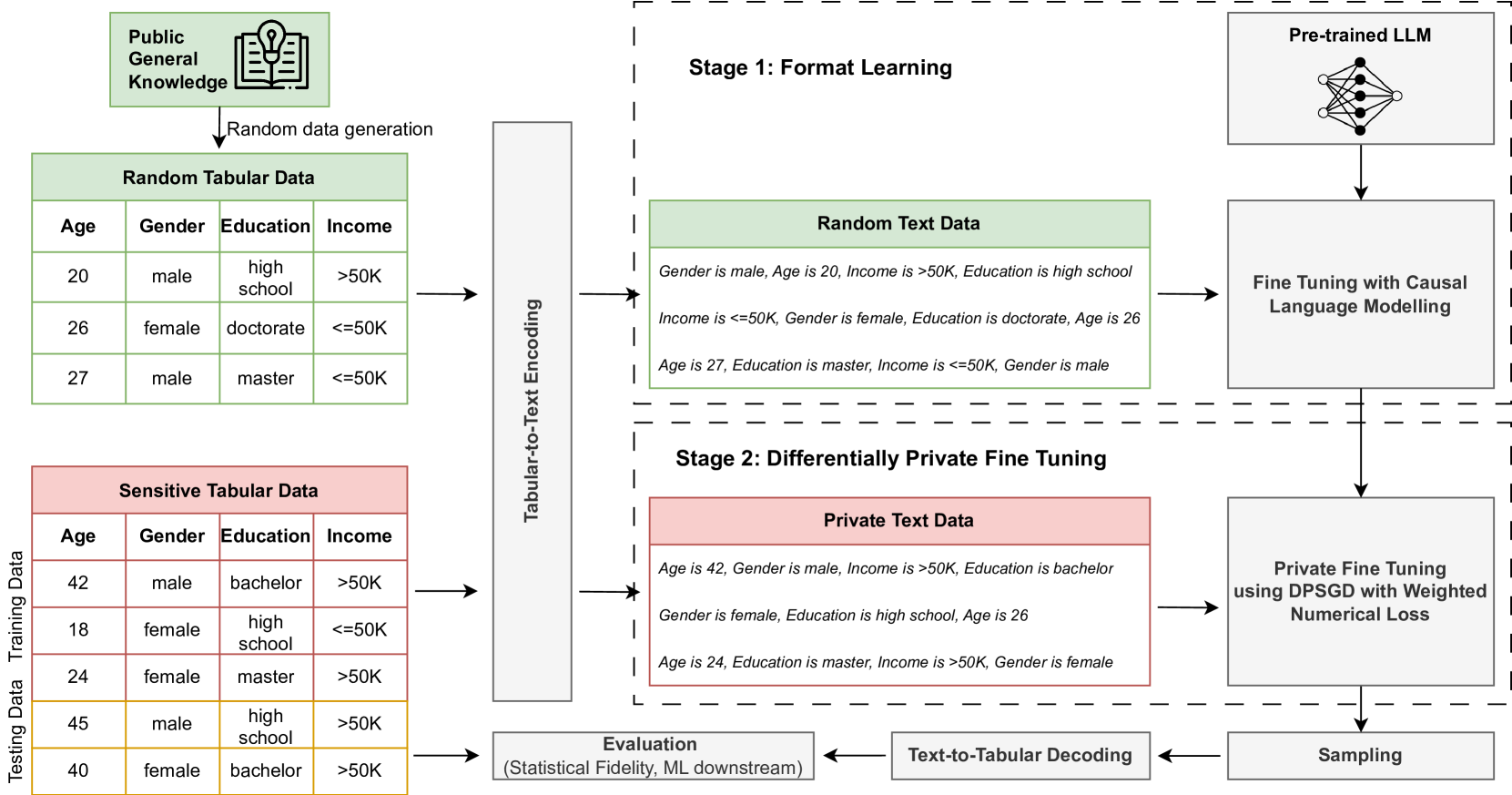
Differentially Private Tabular Data Synthesis using Large Language Models
Toan V. Tran, Li Xiong
0
0
Synthetic tabular data generation with differential privacy is a crucial problem to enable data sharing with formal privacy. Despite a rich history of methodological research and development, developing differentially private tabular data generators that can provide realistic synthetic datasets remains challenging. This paper introduces DP-LLMTGen -- a novel framework for differentially private tabular data synthesis that leverages pretrained large language models (LLMs). DP-LLMTGen models sensitive datasets using a two-stage fine-tuning procedure with a novel loss function specifically designed for tabular data. Subsequently, it generates synthetic data through sampling the fine-tuned LLMs. Our empirical evaluation demonstrates that DP-LLMTGen outperforms a variety of existing mechanisms across multiple datasets and privacy settings. Additionally, we conduct an ablation study and several experimental analyses to deepen our understanding of LLMs in addressing this important problem. Finally, we highlight the controllable generation ability of DP-LLMTGen through a fairness-constrained generation setting.
6/4/2024
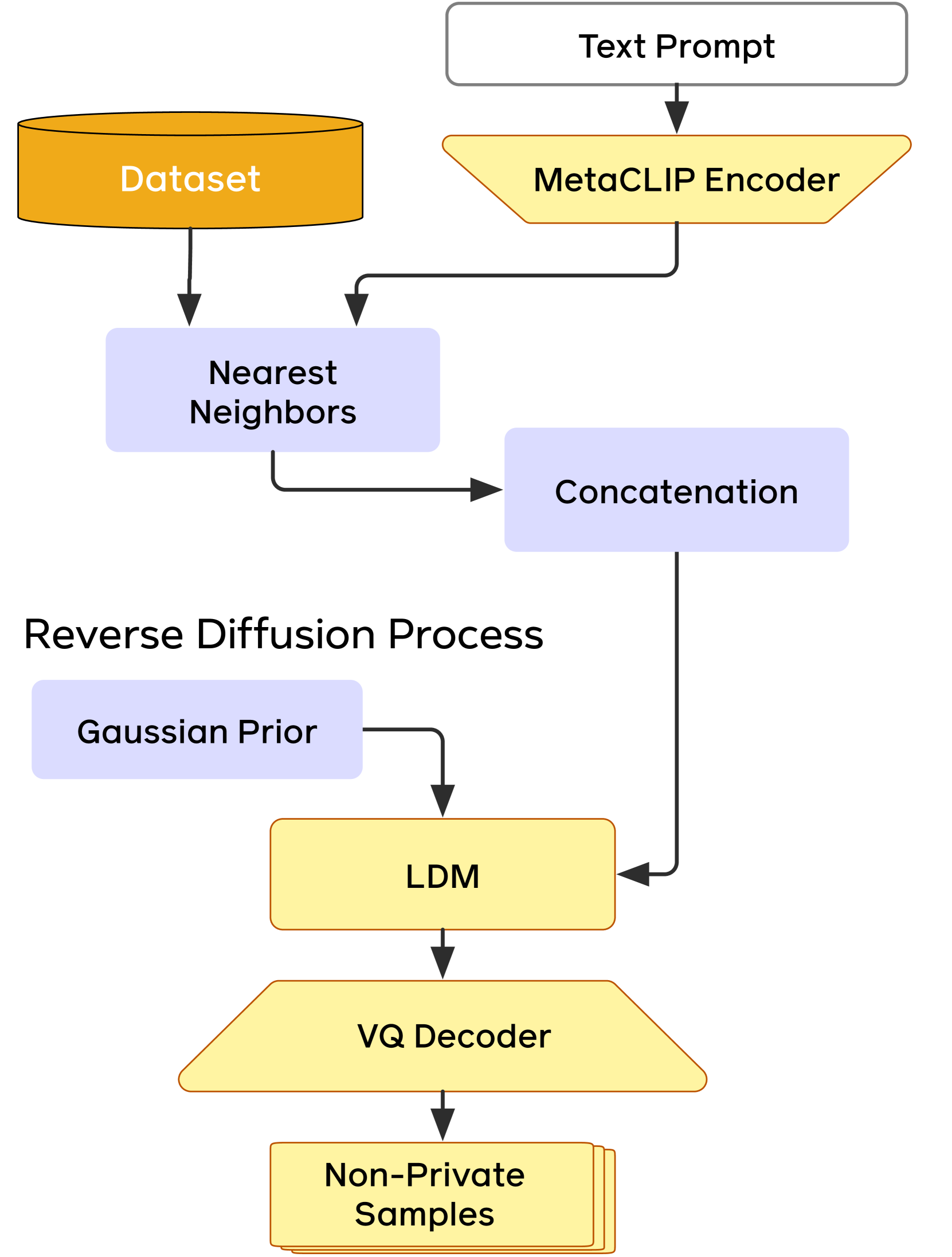
DP-RDM: Adapting Diffusion Models to Private Domains Without Fine-Tuning
Jonathan Lebensold, Maziar Sanjabi, Pietro Astolfi, Adriana Romero-Soriano, Kamalika Chaudhuri, Mike Rabbat, Chuan Guo
0
0
Text-to-image diffusion models have been shown to suffer from sample-level memorization, possibly reproducing near-perfect replica of images that they are trained on, which may be undesirable. To remedy this issue, we develop the first differentially private (DP) retrieval-augmented generation algorithm that is capable of generating high-quality image samples while providing provable privacy guarantees. Specifically, we assume access to a text-to-image diffusion model trained on a small amount of public data, and design a DP retrieval mechanism to augment the text prompt with samples retrieved from a private retrieval dataset. Our emph{differentially private retrieval-augmented diffusion model} (DP-RDM) requires no fine-tuning on the retrieval dataset to adapt to another domain, and can use state-of-the-art generative models to generate high-quality image samples while satisfying rigorous DP guarantees. For instance, when evaluated on MS-COCO, our DP-RDM can generate samples with a privacy budget of $epsilon=10$, while providing a $3.5$ point improvement in FID compared to public-only retrieval for up to $10,000$ queries.
5/14/2024