SemFlow: Binding Semantic Segmentation and Image Synthesis via Rectified Flow
2405.20282
0
0

Abstract
Semantic segmentation and semantic image synthesis are two representative tasks in visual perception and generation. While existing methods consider them as two distinct tasks, we propose a unified diffusion-based framework (SemFlow) and model them as a pair of reverse problems. Specifically, motivated by rectified flow theory, we train an ordinary differential equation (ODE) model to transport between the distributions of real images and semantic masks. As the training object is symmetric, samples belonging to the two distributions, images and semantic masks, can be effortlessly transferred reversibly. For semantic segmentation, our approach solves the contradiction between the randomness of diffusion outputs and the uniqueness of segmentation results. For image synthesis, we propose a finite perturbation approach to enhance the diversity of generated results without changing the semantic categories. Experiments show that our SemFlow achieves competitive results on semantic segmentation and semantic image synthesis tasks. We hope this simple framework will motivate people to rethink the unification of low-level and high-level vision. Project page: https://github.com/wang-chaoyang/SemFlow.
Create account to get full access
Overview
- The paper introduces SemFlow, a novel approach that binds semantic segmentation and image synthesis using a rectified flow framework.
- SemFlow aims to leverage the strengths of both semantic segmentation and image synthesis to generate high-quality images that are semantically consistent with the input.
- The method involves training a neural network to learn a "semantic flow" that maps pixels from a source image to a target image, while preserving semantic information.
Plain English Explanation
SemFlow is a new technique that combines two important computer vision tasks: semantic segmentation and image synthesis. Semantic segmentation is the process of identifying and labeling different objects or regions in an image, while image synthesis is the ability to generate new images from scratch or based on some input.
The key idea behind SemFlow is to use a "semantic flow" to map pixels from a source image to a target image, while preserving the semantic information. This means that the generated image will not only look realistic, but also be semantically consistent with the input. For example, if the input image contains a car, the generated image should also have a car in the same location and with the same properties.
By binding semantic segmentation and image synthesis, SemFlow aims to create high-quality images that are both visually appealing and semantically meaningful. This could have applications in areas like image editing, scene generation, and even video synthesis, where preserving the semantic context is important.
The authors of SemFlow have developed a novel neural network architecture and training process to achieve this goal, building on previous work on rectified flows and diffusion models for image synthesis.
Technical Explanation
The SemFlow approach combines a semantic segmentation model and an image synthesis model, with a "semantic flow" module that maps pixels from the source image to the target image while preserving semantic information. The network is trained end-to-end using a combination of segmentation, reconstruction, and flow consistency losses.
The authors leverage the strengths of OpFlowTalker, a state-of-the-art method for generating realistic talking faces, to capture the dynamic nature of the semantic flow. They also build upon Switched Flow, a technique for improving the training of rectified flows by addressing singularities in the flow field.
Through extensive experiments, the authors demonstrate that SemFlow can generate high-quality images that are semantically consistent with the input, outperforming state-of-the-art image-to-image translation and semantic segmentation models. The model is shown to be robust to various types of input, including dynamic scenes and partially occluded objects.
Critical Analysis
The paper presents a well-designed and comprehensive evaluation of the SemFlow approach, considering a range of baselines and testing the model's performance on various datasets and tasks. The authors also acknowledge the limitations of their work, such as the potential for artifacts in the generated images and the need for further improvements in the flow modeling to handle more complex transformations.
One area that could be explored further is the interpretability and explainability of the semantic flow. While the authors demonstrate the model's ability to preserve semantic information, it would be interesting to investigate how the flow field captures and represents the semantic relationships between different elements in the image.
Additionally, the paper does not discuss the computational efficiency and inference time of the SemFlow model, which could be an important consideration for real-world applications. Comparing the performance of SemFlow to other efficient image-to-image translation or semantic segmentation models would provide a more comprehensive understanding of its practical implications.
Conclusion
The SemFlow approach represents an exciting advancement in the field of computer vision, as it successfully binds semantic segmentation and image synthesis to generate high-quality, semantically consistent images. By leveraging a rectified flow framework, the method can capture the dynamic nature of the semantic relationships between image elements, paving the way for more sophisticated and versatile image manipulation and generation tools.
The technical innovations and the extensive evaluation presented in this paper demonstrate the potential of SemFlow to have a significant impact on a wide range of applications, from image editing and scene generation to video synthesis and augmented reality. As the authors continue to refine and expand the capabilities of this approach, it will be interesting to see how it evolves and contributes to the ongoing advancements in the field of computer vision and image understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
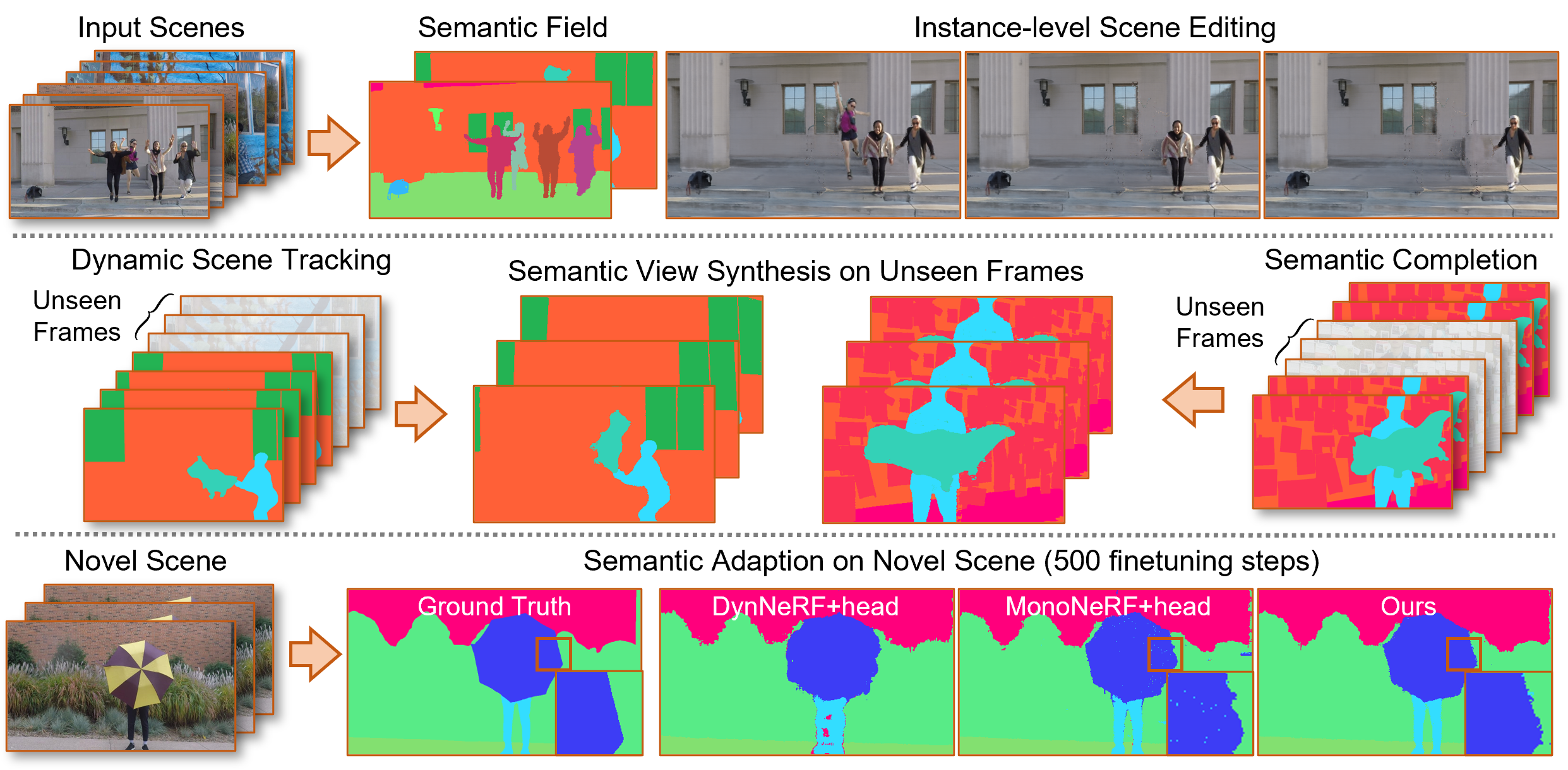
Semantic Flow: Learning Semantic Field of Dynamic Scenes from Monocular Videos
Fengrui Tian, Yueqi Duan, Angtian Wang, Jianfei Guo, Shaoyi Du
0
0
In this work, we pioneer Semantic Flow, a neural semantic representation of dynamic scenes from monocular videos. In contrast to previous NeRF methods that reconstruct dynamic scenes from the colors and volume densities of individual points, Semantic Flow learns semantics from continuous flows that contain rich 3D motion information. As there is 2D-to-3D ambiguity problem in the viewing direction when extracting 3D flow features from 2D video frames, we consider the volume densities as opacity priors that describe the contributions of flow features to the semantics on the frames. More specifically, we first learn a flow network to predict flows in the dynamic scene, and propose a flow feature aggregation module to extract flow features from video frames. Then, we propose a flow attention module to extract motion information from flow features, which is followed by a semantic network to output semantic logits of flows. We integrate the logits with volume densities in the viewing direction to supervise the flow features with semantic labels on video frames. Experimental results show that our model is able to learn from multiple dynamic scenes and supports a series of new tasks such as instance-level scene editing, semantic completions, dynamic scene tracking and semantic adaption on novel scenes. Codes are available at https://github.com/tianfr/Semantic-Flow/.
4/9/2024

Text-to-Image Rectified Flow as Plug-and-Play Priors
Xiaofeng Yang, Cheng Chen, Xulei Yang, Fayao Liu, Guosheng Lin
0
0
Large-scale diffusion models have achieved remarkable performance in generative tasks. Beyond their initial training applications, these models have proven their ability to function as versatile plug-and-play priors. For instance, 2D diffusion models can serve as loss functions to optimize 3D implicit models. Rectified flow, a novel class of generative models, enforces a linear progression from the source to the target distribution and has demonstrated superior performance across various domains. Compared to diffusion-based methods, rectified flow approaches surpass in terms of generation quality and efficiency, requiring fewer inference steps. In this work, we present theoretical and experimental evidence demonstrating that rectified flow based methods offer similar functionalities to diffusion models - they can also serve as effective priors. Besides the generative capabilities of diffusion priors, motivated by the unique time-symmetry properties of rectified flow models, a variant of our method can additionally perform image inversion. Experimentally, our rectified flow-based priors outperform their diffusion counterparts - the SDS and VSD losses - in text-to-3D generation. Our method also displays competitive performance in image inversion and editing.
6/6/2024
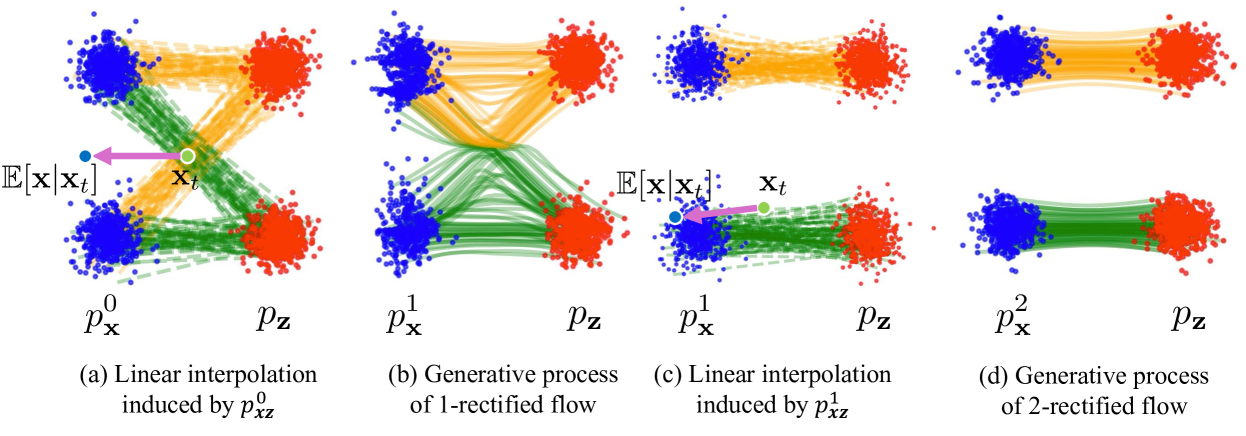
Improving the Training of Rectified Flows
Sangyun Lee, Zinan Lin, Giulia Fanti
0
0
Diffusion models have shown great promise for image and video generation, but sampling from state-of-the-art models requires expensive numerical integration of a generative ODE. One approach for tackling this problem is rectified flows, which iteratively learn smooth ODE paths that are less susceptible to truncation error. However, rectified flows still require a relatively large number of function evaluations (NFEs). In this work, we propose improved techniques for training rectified flows, allowing them to compete with knowledge distillation methods even in the low NFE setting. Our main insight is that under realistic settings, a single iteration of the Reflow algorithm for training rectified flows is sufficient to learn nearly straight trajectories; hence, the current practice of using multiple Reflow iterations is unnecessary. We thus propose techniques to improve one-round training of rectified flows, including a U-shaped timestep distribution and LPIPS-Huber premetric. With these techniques, we improve the FID of the previous 2-rectified flow by up to 72% in the 1 NFE setting on CIFAR-10. On ImageNet 64$times$64, our improved rectified flow outperforms the state-of-the-art distillation methods such as consistency distillation and progressive distillation in both one-step and two-step settings and rivals the performance of improved consistency training (iCT) in FID. Code is available at https://github.com/sangyun884/rfpp.
5/31/2024
🏋️
Exploring Limits of Diffusion-Synthetic Training with Weakly Supervised Semantic Segmentation
Ryota Yoshihashi, Yuya Otsuka, Kenji Doi, Tomohiro Tanaka, Hirokatsu Kataoka
0
0
The advance of generative models for images has inspired various training techniques for image recognition utilizing synthetic images. In semantic segmentation, one promising approach is extracting pseudo-masks from attention maps in text-to-image diffusion models, which enables real-image-and-annotation-free training. However, the pioneering training method using the diffusion-synthetic images and pseudo-masks, i.e., DiffuMask has limitations in terms of mask quality, scalability, and ranges of applicable domains. To overcome these limitations, this work introduces three techniques for diffusion-synthetic semantic segmentation training. First, reliability-aware robust training, originally used in weakly supervised learning, helps segmentation with insufficient synthetic mask quality. %Second, large-scale pretraining of whole segmentation models, not only backbones, on synthetic ImageNet-1k-class images with pixel-labels benefits downstream segmentation tasks. Second, we introduce prompt augmentation, data augmentation to the prompt text set to scale up and diversify training images with a limited text resources. Finally, LoRA-based adaptation of Stable Diffusion enables the transfer to a distant domain, e.g., auto-driving images. Experiments in PASCAL VOC, ImageNet-S, and Cityscapes show that our method effectively closes gap between real and synthetic training in semantic segmentation.
4/16/2024