A Semi-supervised Fake News Detection using Sentiment Encoding and LSTM with Self-Attention

0

Sign in to get full access
Overview
- Proposes a semi-supervised fake news detection model that combines sentiment encoding and an LSTM with self-attention
- Aims to improve fake news detection accuracy in scenarios with limited labeled data
- Leverages both textual and sentiment features to distinguish real from fake news articles
Plain English Explanation
The paper presents a novel approach to detecting fake news articles using machine learning. The key idea is to combine sentiment analysis and long short-term memory (LSTM) with self-attention.
Sentiment analysis is used to extract emotional cues from the text, which can provide important signals about whether an article is truthful or fabricated. The LSTM model is well-suited for processing text data, as it can capture the sequential dependencies in language. The self-attention mechanism allows the model to focus on the most relevant parts of the input when making predictions.
By integrating these techniques, the researchers develop a semi-supervised fake news detection system. This means the model can learn from both labeled (known real or fake) and unlabeled data, making it more robust when labeled training data is scarce.
The key innovation is leveraging both the content of the article (through the LSTM) and the sentiment expressed (through sentiment analysis) to accurately distinguish real from fake news, even in challenging cases where limited labeled data is available.
Technical Explanation
The paper proposes a semi-supervised fake news detection framework that combines sentiment encoding and a long short-term memory (LSTM) network with self-attention.
The model takes news article text as input and outputs a prediction of whether the article is real or fake. The architecture consists of three main components:
-
Sentiment Encoder: This module extracts sentiment features from the input text using a pre-trained sentiment analysis model. The sentiment scores are then concatenated with the text features.
-
LSTM with Self-Attention: The combined text and sentiment features are passed through an LSTM network, which can effectively capture the sequential relationships in the text. The self-attention mechanism allows the LSTM to focus on the most relevant parts of the input when making the final prediction.
-
Semi-Supervised Learning: To address the challenge of limited labeled data, the framework employs a semi-supervised learning approach. It leverages both labeled (known real or fake) and unlabeled data to train the model, improving its ability to generalize to new, unseen examples.
The researchers evaluate their framework on multiple fake news datasets and compare it to several baseline methods. The results demonstrate that the combination of sentiment encoding and the LSTM with self-attention outperforms other state-of-the-art fake news detection approaches, especially in scenarios with limited labeled training data.
Critical Analysis
The paper presents a thoughtful and well-designed approach to the important problem of fake news detection. The key strengths of the research include:
- Leveraging Sentiment: Incorporating sentiment analysis to extract emotional cues from the text is a clever way to augment the textual features and improve the model's ability to distinguish real from fake news.
- Attention Mechanism: The use of self-attention allows the LSTM to focus on the most salient parts of the input, which can be crucial for accurately classifying complex news articles.
- Semi-Supervised Learning: Addressing the challenge of limited labeled data through semi-supervised learning is a practical and impactful innovation, making the model more widely applicable.
However, the paper could be strengthened by:
- Exploring Multilingual Capabilities: The evaluation is limited to English-language datasets, so it's unclear how well the model would generalize to other languages.
- Analyzing Model Interpretability: Providing more insights into which specific sentiment and textual features the model is using to make its predictions could enhance the interpretability and trustworthiness of the system.
- Considering Real-World Deployment: The researchers could discuss potential challenges and considerations for deploying such a system in a real-world news ecosystem, where adversaries may actively try to evade detection.
Overall, the proposed semi-supervised fake news detection framework represents a valuable contribution to the field, offering a robust and practical solution for identifying misinformation, especially in data-scarce scenarios.
Conclusion
This paper presents a novel semi-supervised fake news detection model that combines sentiment encoding and an LSTM with self-attention. The key innovation is leveraging both textual and sentiment features to accurately classify real and fake news articles, even when labeled training data is limited.
The results demonstrate the effectiveness of this approach compared to other state-of-the-art methods, highlighting the importance of incorporating sentiment analysis and attention mechanisms for this task. While further research is needed to explore the model's multilingual capabilities and interpretability, this work represents an important step forward in the ongoing effort to combat the spread of misinformation online.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Semi-supervised Fake News Detection using Sentiment Encoding and LSTM with Self-Attention
Pouya Shaeri, Ali Katanforoush
Micro-blogs and cyber-space social networks are the main communication mediums to receive and share news nowadays. As a side effect, however, the networks can disseminate fake news that harms individuals and the society. Several methods have been developed to detect fake news, but the majority require large sets of manually labeled data to attain the application-level accuracy. Due to the strict privacy policies, the required data are often inaccessible or limited to some specific topics. On the other side, quite diverse and abundant unlabeled data on social media suggests that with a few labeled data, the problem of detecting fake news could be tackled via semi-supervised learning. Here, we propose a semi-supervised self-learning method in which a sentiment analysis is acquired by some state-of-the-art pretrained models. Our learning model is trained in a semi-supervised fashion and incorporates LSTM with self-attention layers. We benchmark our model on a dataset with 20,000 news content along with their feedback, which shows better performance in precision, recall, and measures compared to competitive methods in fake news detection.
Read more7/30/2024
🔎
0
Adapting Fake News Detection to the Era of Large Language Models
Jinyan Su, Claire Cardie, Preslav Nakov
In the age of large language models (LLMs) and the widespread adoption of AI-driven content creation, the landscape of information dissemination has witnessed a paradigm shift. With the proliferation of both human-written and machine-generated real and fake news, robustly and effectively discerning the veracity of news articles has become an intricate challenge. While substantial research has been dedicated to fake news detection, this either assumes that all news articles are human-written or abruptly assumes that all machine-generated news are fake. Thus, a significant gap exists in understanding the interplay between machine-(paraphrased) real news, machine-generated fake news, human-written fake news, and human-written real news. In this paper, we study this gap by conducting a comprehensive evaluation of fake news detectors trained in various scenarios. Our primary objectives revolve around the following pivotal question: How to adapt fake news detectors to the era of LLMs? Our experiments reveal an interesting pattern that detectors trained exclusively on human-written articles can indeed perform well at detecting machine-generated fake news, but not vice versa. Moreover, due to the bias of detectors against machine-generated texts cite{su2023fake}, they should be trained on datasets with a lower machine-generated news ratio than the test set. Building on our findings, we provide a practical strategy for the development of robust fake news detectors.
Read more4/16/2024

0
Exposing and Explaining Fake News On-the-Fly
Francisco de Arriba-P'erez, Silvia Garc'ia-M'endez, F'atima Leal, Benedita Malheiro, Juan Carlos Burguillo
Social media platforms enable the rapid dissemination and consumption of information. However, users instantly consume such content regardless of the reliability of the shared data. Consequently, the latter crowdsourcing model is exposed to manipulation. This work contributes with an explainable and online classification method to recognize fake news in real-time. The proposed method combines both unsupervised and supervised Machine Learning approaches with online created lexica. The profiling is built using creator-, content- and context-based features using Natural Language Processing techniques. The explainable classification mechanism displays in a dashboard the features selected for classification and the prediction confidence. The performance of the proposed solution has been validated with real data sets from Twitter and the results attain 80 % accuracy and macro F-measure. This proposal is the first to jointly provide data stream processing, profiling, classification and explainability. Ultimately, the proposed early detection, isolation and explanation of fake news contribute to increase the quality and trustworthiness of social media contents.
Read more9/6/2024
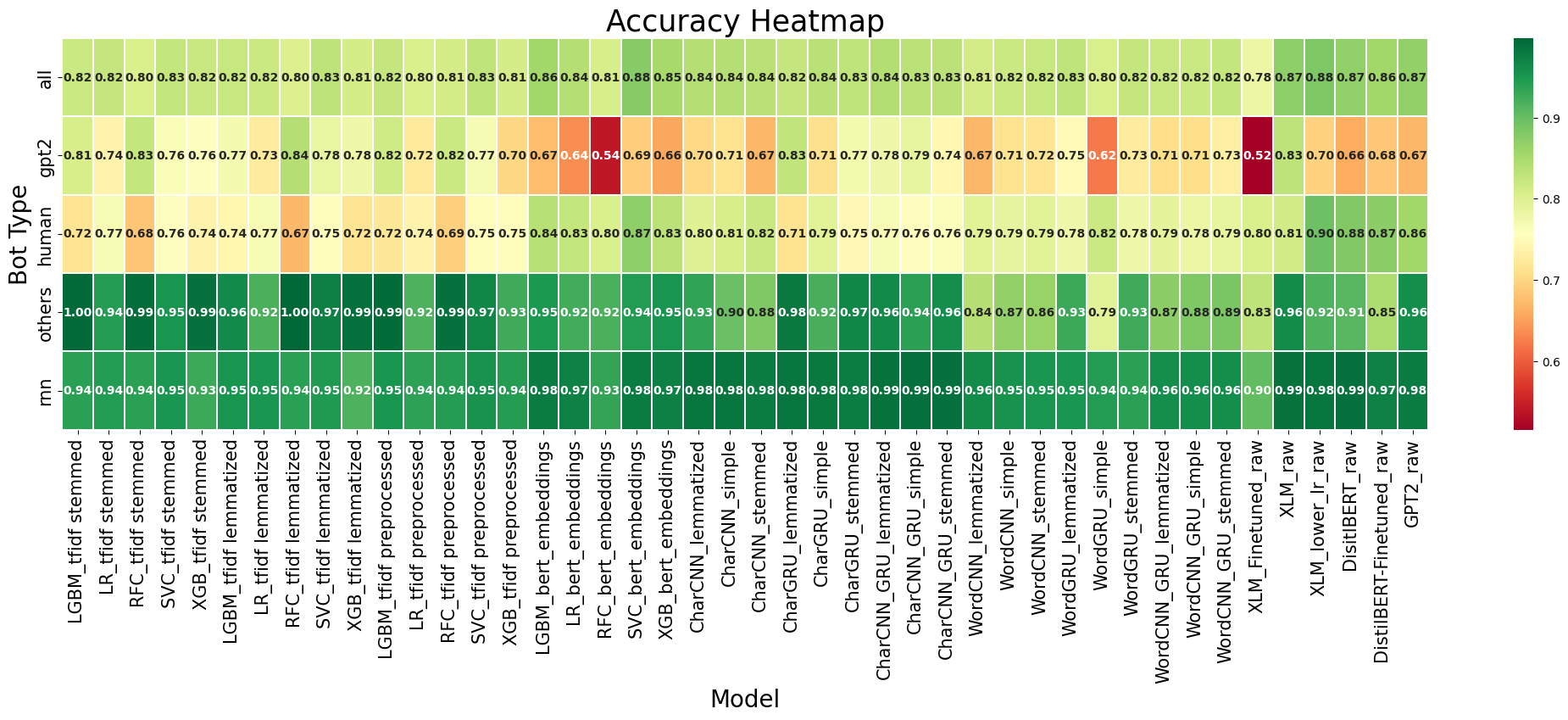
0
Deepfake tweets automatic detection
Adam Frej, Adrian Kaminski, Piotr Marciniak, Szymon Szmajdzinski, Soveatin Kuntur, Anna Wroblewska
This study addresses the critical challenge of detecting DeepFake tweets by leveraging advanced natural language processing (NLP) techniques to distinguish between genuine and AI-generated texts. Given the increasing prevalence of misinformation, our research utilizes the TweepFake dataset to train and evaluate various machine learning models. The objective is to identify effective strategies for recognizing DeepFake content, thereby enhancing the integrity of digital communications. By developing reliable methods for detecting AI-generated misinformation, this work contributes to a more trustworthy online information environment.
Read more6/26/2024