Semi-Supervised Pipe Video Temporal Defect Interval Localization

0

Sign in to get full access
Overview
- Provides a semi-supervised approach for locating temporal defect intervals in pipe videos.
- Leverages both labeled and unlabeled data to improve defect detection performance.
- Proposes a novel semi-supervised framework combining self-supervised learning and pseudo-labeling.
Plain English Explanation
The paper presents a semi-supervised approach for detecting and localizing temporal defects in pipe videos. The key challenge is that obtaining labeled data for pipe defects can be time-consuming and expensive, so the researchers developed a way to utilize both labeled and unlabeled data to improve the model's performance.
The proposed framework combines self-supervised learning and pseudo-labeling techniques. Self-supervised learning allows the model to learn useful features from the unlabeled pipe videos without any manual annotations. The pseudo-labeling component then uses these learned features to automatically generate labels for the unlabeled data, which can then be used to further train the model.
By leveraging both labeled and unlabeled data in this way, the researchers were able to create a more robust and accurate defect detection system, without the need for extensive manual labeling of the pipe video data.
Technical Explanation
The paper proposes a semi-supervised framework for temporal defect interval localization in pipe videos. The key components of the framework are:
-
Self-Supervised Learning: The model first undergoes self-supervised pre-training on the unlabeled pipe video data. This allows the model to learn useful feature representations without any manual annotations.
-
Pseudo-Labeling: The self-supervised features are then used to generate pseudo-labels for the unlabeled data, which are then combined with the limited labeled data to fine-tune the model.
-
Temporal Defect Localization: The final model is able to accurately localize temporal defect intervals within the pipe videos, even when only a small amount of labeled data is available.
The researchers demonstrate the effectiveness of their approach through experiments on a real-world pipe video dataset, showing significant improvements in defect detection performance compared to fully-supervised baselines.
Critical Analysis
The paper presents a novel and promising approach for leveraging both labeled and unlabeled data to improve temporal defect localization in pipe videos. The combination of self-supervised learning and pseudo-labeling is a clever way to overcome the challenge of limited labeled data, which is a common issue in many real-world computer vision applications.
However, the paper does not discuss potential limitations or caveats of the proposed framework. For example, the effectiveness of the pseudo-labeling process may be sensitive to the quality of the self-supervised features, and the approach may not generalize well to scenarios with more complex defect patterns or diverse pipe environments.
Additionally, the paper could have provided more detailed analysis of the trade-offs between the amount of labeled data, the quality of the pseudo-labels, and the final model performance. This would help readers better understand the practical considerations and limitations of the proposed approach.
Conclusion
The semi-supervised pipe video temporal defect interval localization framework presented in this paper offers a promising solution to the challenge of limited labeled data in real-world computer vision applications. By combining self-supervised learning and pseudo-labeling, the model is able to effectively leverage both labeled and unlabeled data to achieve accurate defect detection without the need for extensive manual annotation.
The proposed approach has the potential to significantly streamline the process of pipe infrastructure monitoring and maintenance, and the techniques could be applicable to a wide range of other domains where labeled data is scarce. Overall, this work represents an important contribution to the field of semi-supervised computer vision and highlights the value of leveraging unlabeled data to improve model performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Semi-Supervised Pipe Video Temporal Defect Interval Localization
Zhu Huang, Gang Pan, Chao Kang, YaoZhi Lv
In sewer pipe Closed-Circuit Television (CCTV) inspection, accurate temporal defect localization is essential for effective defect classification, detection, segmentation and quantification. Industry standards typically do not require time-interval annotations, even though they are more informative than time-point annotations for defect localization, resulting in additional annotation costs when fully supervised methods are used. Additionally, differences in scene types and camera motion patterns between pipe inspections and Temporal Action Localization (TAL) hinder the effective transfer of point-supervised TAL methods. Therefore, this study introduces a Semi-supervised multi-Prototype-based method incorporating visual Odometry for enhanced attention guidance (PipeSPO). PipeSPO fully leverages unlabeled data through unsupervised pretext tasks and utilizes time-point annotated data with a weakly supervised multi-prototype-based method, relying on visual odometry features to capture camera pose information. Experiments on real-world datasets demonstrate that PipeSPO achieves 41.89% average precision across Intersection over Union (IoU) thresholds of 0.1-0.7, improving by 8.14% over current state-of-the-art methods.
Read more7/23/2024
⚙️
0
Self-Supervised Learning for Identifying Defects in Sewer Footage
Daniel Otero, Rafael Mateus
Sewerage infrastructure is among the most expensive modern investments requiring time-intensive manual inspections by qualified personnel. Our study addresses the need for automated solutions without relying on large amounts of labeled data. We propose a novel application of Self-Supervised Learning (SSL) for sewer inspection that offers a scalable and cost-effective solution for defect detection. We achieve competitive results with a model that is at least 5 times smaller than other approaches found in the literature and obtain competitive performance with 10% of the available data when training with a larger architecture. Our findings highlight the potential of SSL to revolutionize sewer maintenance in resource-limited settings.
Read more9/5/2024
🌀
0
POTLoc: Pseudo-Label Oriented Transformer for Point-Supervised Temporal Action Localization
Elahe Vahdani, Yingli Tian
This paper tackles the challenge of point-supervised temporal action detection, wherein only a single frame is annotated for each action instance in the training set. Most of the current methods, hindered by the sparse nature of annotated points, struggle to effectively represent the continuous structure of actions or the inherent temporal and semantic dependencies within action instances. Consequently, these methods frequently learn merely the most distinctive segments of actions, leading to the creation of incomplete action proposals. This paper proposes POTLoc, a Pseudo-label Oriented Transformer for weakly-supervised Action Localization utilizing only point-level annotation. POTLoc is designed to identify and track continuous action structures via a self-training strategy. The base model begins by generating action proposals solely with point-level supervision. These proposals undergo refinement and regression to enhance the precision of the estimated action boundaries, which subsequently results in the production of `pseudo-labels' to serve as supplementary supervisory signals. The architecture of the model integrates a transformer with a temporal feature pyramid to capture video snippet dependencies and model actions of varying duration. The pseudo-labels, providing information about the coarse locations and boundaries of actions, assist in guiding the transformer for enhanced learning of action dynamics. POTLoc outperforms the state-of-the-art point-supervised methods on THUMOS'14 and ActivityNet-v1.2 datasets.
Read more6/7/2024
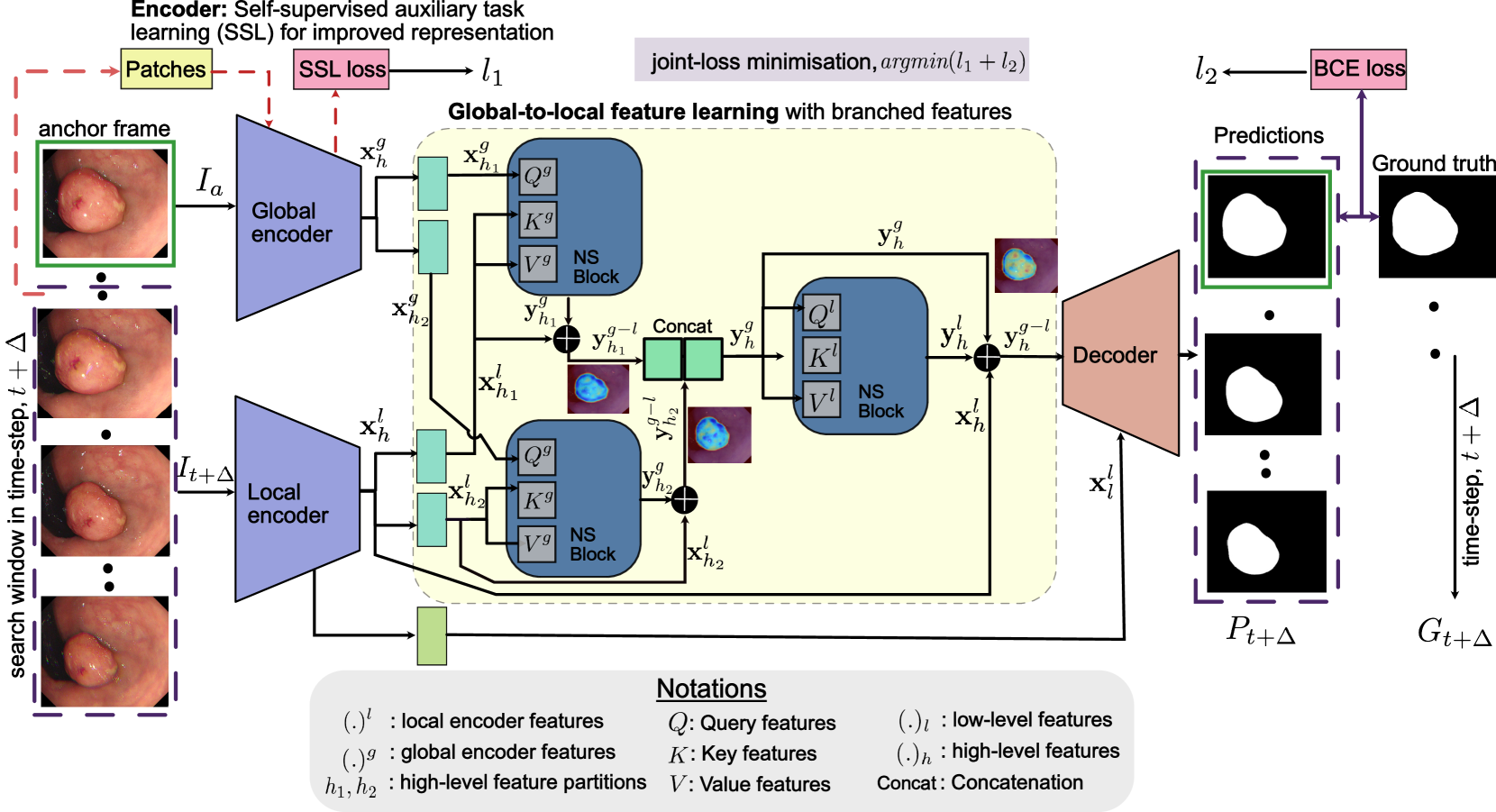
0
SSTFB: Leveraging self-supervised pretext learning and temporal self-attention with feature branching for real-time video polyp segmentation
Ziang Xu, Jens Rittscher, Sharib Ali
Polyps are early cancer indicators, so assessing occurrences of polyps and their removal is critical. They are observed through a colonoscopy screening procedure that generates a stream of video frames. Segmenting polyps in their natural video screening procedure has several challenges, such as the co-existence of imaging artefacts, motion blur, and floating debris. Most existing polyp segmentation algorithms are developed on curated still image datasets that do not represent real-world colonoscopy. Their performance often degrades on video data. We propose a video polyp segmentation method that performs self-supervised learning as an auxiliary task and a spatial-temporal self-attention mechanism for improved representation learning. Our end-to-end configuration and joint optimisation of losses enable the network to learn more discriminative contextual features in videos. Our experimental results demonstrate an improvement with respect to several state-of-the-art (SOTA) methods. Our ablation study also confirms that the choice of the proposed joint end-to-end training improves network accuracy by over 3% and nearly 10% on both the Dice similarity coefficient and intersection-over-union compared to the recently proposed method PNS+ and Polyp-PVT, respectively. Results on previously unseen video data indicate that the proposed method generalises.
Read more6/17/2024