Sequence Compression Speeds Up Credit Assignment in Reinforcement Learning
2405.03878
0
0
Abstract
Temporal credit assignment in reinforcement learning is challenging due to delayed and stochastic outcomes. Monte Carlo targets can bridge long delays between action and consequence but lead to high-variance targets due to stochasticity. Temporal difference (TD) learning uses bootstrapping to overcome variance but introduces a bias that can only be corrected through many iterations. TD($lambda$) provides a mechanism to navigate this bias-variance tradeoff smoothly. Appropriately selecting $lambda$ can significantly improve performance. Here, we propose Chunked-TD, which uses predicted probabilities of transitions from a model for computing $lambda$-return targets. Unlike other model-based solutions to credit assignment, Chunked-TD is less vulnerable to model inaccuracies. Our approach is motivated by the principle of history compression and 'chunks' trajectories for conventional TD learning. Chunking with learned world models compresses near-deterministic regions of the environment-policy interaction to speed up credit assignment while still bootstrapping when necessary. We propose algorithms that can be implemented online and show that they solve some problems much faster than conventional TD($lambda$).
Create account to get full access
Overview
- This paper introduces a novel reinforcement learning (RL) algorithm called Sequence Compression that speeds up credit assignment in RL tasks.
- The key idea is to compress sequences of observations, actions, and rewards into higher-level representations, which can then be used to more efficiently update the agent's policy.
- The authors demonstrate that Sequence Compression outperforms standard RL algorithms on a variety of benchmark tasks, including solving continual offline reinforcement learning, label delay online continual learning, and reinforcement learning with edit-based non-autoregressive neural models.
Plain English Explanation
Reinforcement learning is a powerful technique for training AI agents to perform complex tasks by rewarding them for taking the right actions. However, one of the key challenges in reinforcement learning is assigning credit - figuring out which past actions led to the current reward. This is known as the "credit assignment problem."
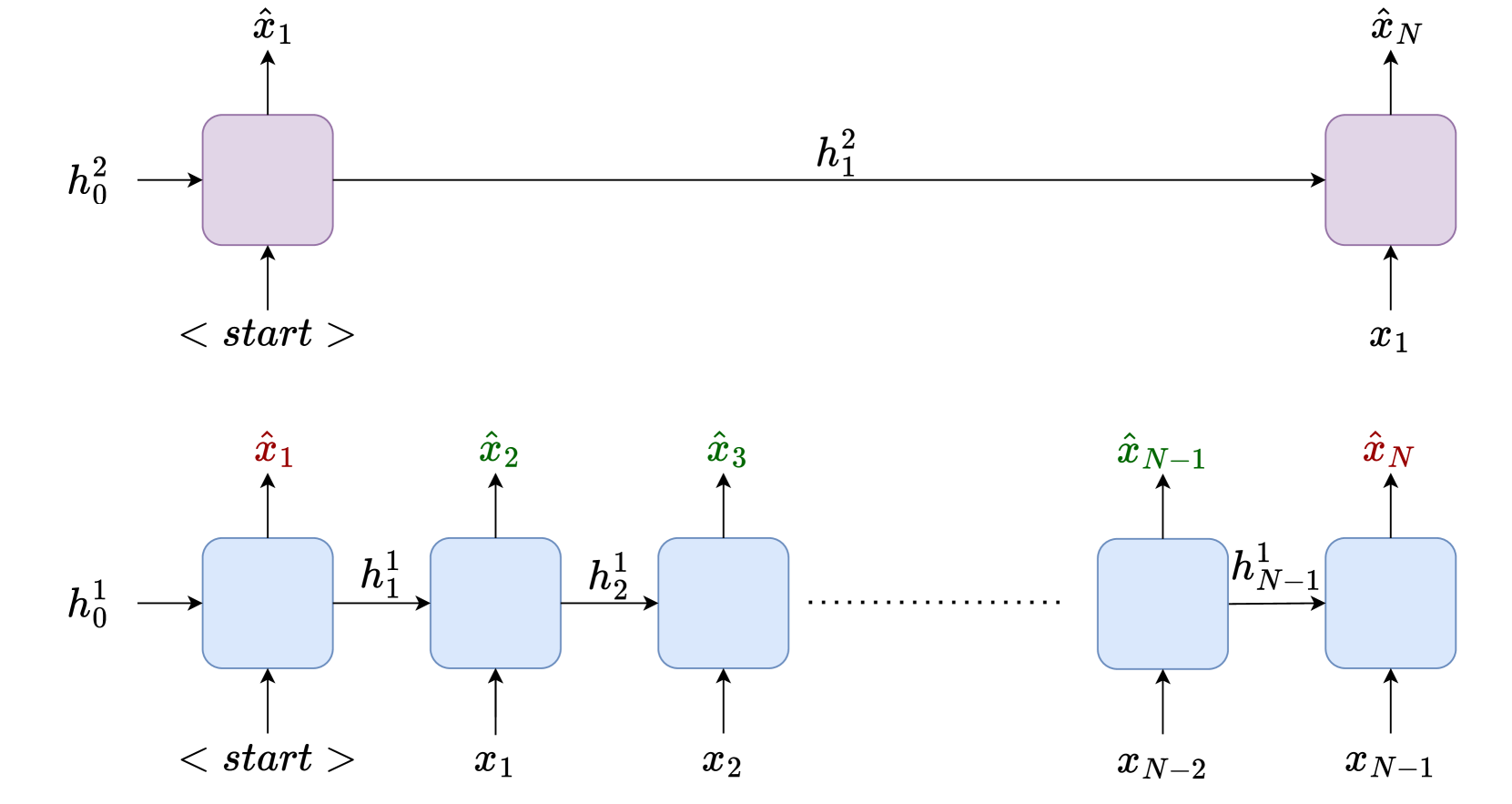
The authors of this paper have developed a new algorithm called Sequence Compression that helps solve this problem. The key idea is to group together sequences of observations, actions, and rewards into higher-level representations, or "chunks." This allows the agent to more efficiently update its policy based on these chunked sequences, rather than having to consider each individual action in isolation.
Imagine you're training a robot to navigate a maze. As the robot moves through the maze, it experiences a sequence of observations (the walls and obstacles it sees), actions (the steps it takes), and rewards (when it reaches the end). Sequence Compression allows the robot to group together these sequences into higher-level "chunks," such as "turn left, move forward, turn right" - rather than just considering each individual step. This makes it easier for the robot to learn which sequences of actions lead to the greatest rewards, and to update its policy accordingly.
The authors show that Sequence Compression outperforms standard reinforcement learning algorithms on a variety of benchmark tasks, including solving continual offline reinforcement learning, label delay online continual learning, and reinforcement learning with edit-based non-autoregressive neural models. This suggests that the Sequence Compression approach could be a valuable tool for improving the performance and efficiency of reinforcement learning systems in a wide range of applications.
Technical Explanation
The key technical innovation in this paper is the Sequence Compression algorithm, which operates as follows:
- The agent observes a sequence of states, actions, and rewards, and encodes this sequence into a higher-level representation using a neural network.
- The agent then uses this compressed sequence representation to update its policy, rather than considering each individual state-action pair in isolation.
- The authors show that this Sequence Compression approach leads to faster convergence and better performance on a variety of RL benchmarks, compared to standard RL algorithms.
The authors evaluate their approach on several challenging RL tasks, including tract training dynamics aware contrastive learning framework and longitudinal targeted minimum loss based estimation temporal models. They demonstrate that Sequence Compression consistently outperforms baseline RL algorithms, and provide ablation studies to understand the key factors driving its improved performance.
Critical Analysis
One potential limitation of the Sequence Compression approach is that it may be sensitive to the choice of neural network architecture and hyperparameters used for the sequence encoding. The authors do not provide a detailed exploration of how different architectural choices or hyperparameter settings might affect the algorithm's performance.
Additionally, the paper does not delve deeply into the theoretical underpinnings of why Sequence Compression leads to faster credit assignment and improved performance. While the empirical results are compelling, a more rigorous analysis of the underlying mechanisms could help build a stronger theoretical foundation for the approach.
Furthermore, the paper primarily focuses on standard RL benchmarks, and does not explore how Sequence Compression might perform in more complex, real-world scenarios. Extending the evaluation to additional domains, such as longitudinal targeted minimum loss based estimation temporal models, could help validate the broader applicability of the approach.
Conclusion
Overall, the Sequence Compression algorithm presented in this paper represents a promising approach for addressing the credit assignment problem in reinforcement learning. By compressing sequences of observations, actions, and rewards into higher-level representations, the algorithm is able to more efficiently update the agent's policy, leading to faster convergence and improved performance on a variety of RL benchmarks.
While the paper leaves some open questions and potential avenues for further research, the core idea of Sequence Compression is a valuable contribution to the field of reinforcement learning. As AI systems continue to tackle increasingly complex tasks, techniques like this that can improve the efficiency and effectiveness of credit assignment will be crucial for driving progress in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Temporal Difference Learning with Compressed Updates: Error-Feedback meets Reinforcement Learning
Aritra Mitra, George J. Pappas, Hamed Hassani
0
0
In large-scale distributed machine learning, recent works have studied the effects of compressing gradients in stochastic optimization to alleviate the communication bottleneck. These works have collectively revealed that stochastic gradient descent (SGD) is robust to structured perturbations such as quantization, sparsification, and delays. Perhaps surprisingly, despite the surge of interest in multi-agent reinforcement learning, almost nothing is known about the analogous question: Are common reinforcement learning (RL) algorithms also robust to similar perturbations? We investigate this question by studying a variant of the classical temporal difference (TD) learning algorithm with a perturbed update direction, where a general compression operator is used to model the perturbation. Our work makes three important technical contributions. First, we prove that compressed TD algorithms, coupled with an error-feedback mechanism used widely in optimization, exhibit the same non-asymptotic theoretical guarantees as their SGD counterparts. Second, we show that our analysis framework extends seamlessly to nonlinear stochastic approximation schemes that subsume Q-learning. Third, we prove that for multi-agent TD learning, one can achieve linear convergence speedups with respect to the number of agents while communicating just $tilde{O}(1)$ bits per iteration. Notably, these are the first finite-time results in RL that account for general compression operators and error-feedback in tandem with linear function approximation and Markovian sampling. Our proofs hinge on the construction of novel Lyapunov functions that capture the dynamics of a memory variable introduced by error-feedback.
6/5/2024
Multi-State TD Target for Model-Free Reinforcement Learning
Wuhao Wang, Zhiyong Chen, Lepeng Zhang
0
0
Temporal difference (TD) learning is a fundamental technique in reinforcement learning that updates value estimates for states or state-action pairs using a TD target. This target represents an improved estimate of the true value by incorporating both immediate rewards and the estimated value of subsequent states. Traditionally, TD learning relies on the value of a single subsequent state. We propose an enhanced multi-state TD (MSTD) target that utilizes the estimated values of multiple subsequent states. Building on this new MSTD concept, we develop complete actor-critic algorithms that include management of replay buffers in two modes, and integrate with deep deterministic policy optimization (DDPG) and soft actor-critic (SAC). Experimental results demonstrate that algorithms employing the MSTD target significantly improve learning performance compared to traditional methods.
6/4/2024

Demystifying the Recency Heuristic in Temporal-Difference Learning
Brett Daley, Marlos C. Machado, Martha White
0
0
The recency heuristic in reinforcement learning is the assumption that stimuli that occurred closer in time to an acquired reward should be more heavily reinforced. The recency heuristic is one of the key assumptions made by TD($lambda$), which reinforces recent experiences according to an exponentially decaying weighting. In fact, all other widely used return estimators for TD learning, such as $n$-step returns, satisfy a weaker (i.e., non-monotonic) recency heuristic. Why is the recency heuristic effective for temporal credit assignment? What happens when credit is assigned in a way that violates this heuristic? In this paper, we analyze the specific mathematical implications of adopting the recency heuristic in TD learning. We prove that any return estimator satisfying this heuristic: 1) is guaranteed to converge to the correct value function, 2) has a relatively fast contraction rate, and 3) has a long window of effective credit assignment, yet bounded worst-case variance. We also give a counterexample where on-policy, tabular TD methods violating the recency heuristic diverge. Our results offer some of the first theoretical evidence that credit assignment based on the recency heuristic facilitates learning.
6/19/2024
🤿
An Analysis of Quantile Temporal-Difference Learning
Mark Rowland, R'emi Munos, Mohammad Gheshlaghi Azar, Yunhao Tang, Georg Ostrovski, Anna Harutyunyan, Karl Tuyls, Marc G. Bellemare, Will Dabney
0
0
We analyse quantile temporal-difference learning (QTD), a distributional reinforcement learning algorithm that has proven to be a key component in several successful large-scale applications of reinforcement learning. Despite these empirical successes, a theoretical understanding of QTD has proven elusive until now. Unlike classical TD learning, which can be analysed with standard stochastic approximation tools, QTD updates do not approximate contraction mappings, are highly non-linear, and may have multiple fixed points. The core result of this paper is a proof of convergence to the fixed points of a related family of dynamic programming procedures with probability 1, putting QTD on firm theoretical footing. The proof establishes connections between QTD and non-linear differential inclusions through stochastic approximation theory and non-smooth analysis.
5/21/2024