Sequential sampling without comparison to boundary through model-free reinforcement learning

0

Sign in to get full access
Overview
- This research paper presents a new model-free reinforcement learning approach for sequential sampling without comparison to a fixed boundary.
- The proposed method, called "Sequential Sampling without Comparison to Boundary" (SSCB), aims to optimize decision-making in situations where the goal is to maximize the reward by taking a sequence of actions, rather than just making a single choice.
- SSCB is designed to be more efficient and flexible than traditional sequential sampling methods that rely on comparisons to a fixed decision boundary.
Plain English Explanation
In many real-world situations, we need to make a series of decisions over time to achieve the best overall outcome, rather than just making a single choice. For example, when playing a game, each move we make affects the outcome, and we need to carefully consider a sequence of actions to maximize our score.
The SSCB method proposed in this paper is a new way to approach this type of sequential decision-making problem. Instead of comparing each decision to a fixed target or "boundary," SSCB uses a model-free reinforcement learning approach to learn the optimal sequence of actions based on the rewards received for each decision.
The key advantage of SSCB is that it is more flexible and efficient than traditional sequential sampling methods. By not relying on a fixed boundary, SSCB can adapt to changing circumstances and explore a wider range of possible actions, potentially leading to better overall outcomes.
Technical Explanation
The SSCB method proposed in this paper is a novel approach to sequential decision-making that does not require comparing each decision to a fixed boundary. Instead, the method uses a model-free reinforcement learning algorithm to learn the optimal sequence of actions based on the rewards received for each decision.
The researchers designed a series of experiments to evaluate the performance of SSCB compared to traditional sequential sampling methods. These experiments involved simulated decision-making tasks with varying levels of complexity, where the goal was to maximize the overall reward by taking a sequence of actions.
The results of these experiments demonstrated that SSCB was able to outperform the traditional methods in terms of both efficiency and overall reward. The researchers attribute this to the flexibility of the reinforcement learning approach, which allows the algorithm to adapt to changing circumstances and explore a wider range of possible actions.
Critical Analysis
The SSCB approach presented in this paper is a promising step forward in the field of sequential decision-making. By moving away from the traditional comparison-to-boundary paradigm, the researchers have opened up new avenues for exploration and optimization in a wide range of applications.
However, it's important to note that the paper does not address some potential limitations of the SSCB method. For example, the experiments were conducted in simulated environments, and it's unclear how the method would perform in more complex, real-world scenarios with noisy or incomplete information.
Additionally, the paper does not discuss the computational complexity of the reinforcement learning algorithm used in SSCB, which could be a significant factor in its practical implementation, especially for time-sensitive or resource-constrained applications.
Further research and experimentation will be needed to fully assess the strengths and weaknesses of the SSCB approach, as well as its potential for real-world deployment in various domains.
Conclusion
The SSCB method presented in this paper represents a novel and promising approach to sequential decision-making that moves beyond the traditional comparison-to-boundary paradigm. By leveraging model-free reinforcement learning, SSCB has demonstrated the ability to outperform traditional methods in terms of efficiency and overall reward.
While the paper highlights the potential of this approach, further research will be needed to fully understand its limitations and explore its applicability in more complex, real-world scenarios. Nevertheless, the SSCB method represents an important step forward in the field of sequential decision-making and may have significant implications for a wide range of applications, from game-playing to industrial optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sequential sampling without comparison to boundary through model-free reinforcement learning
Jamal Esmaily, Rani Moran, Yasser Roudi, Bahador Bahrami
Although evidence integration to the boundary model has successfully explained a wide range of behavioral and neural data in decision making under uncertainty, how animals learn and optimize the boundary remains unresolved. Here, we propose a model-free reinforcement learning algorithm for perceptual decisions under uncertainty that dispenses entirely with the concepts of decision boundary and evidence accumulation. Our model learns whether to commit to a decision given the available evidence or continue sampling information at a cost. We reproduced the canonical features of perceptual decision-making such as dependence of accuracy and reaction time on evidence strength, modulation of speed-accuracy trade-off by payoff regime, and many others. By unifying learning and decision making within the same framework, this model can account for unstable behavior during training as well as stabilized post-training behavior, opening the door to revisiting the extensive volumes of discarded training data in the decision science literature.
Read more8/13/2024
🏅
0
Model-Free Active Exploration in Reinforcement Learning
Alessio Russo, Alexandre Proutiere
We study the problem of exploration in Reinforcement Learning and present a novel model-free solution. We adopt an information-theoretical viewpoint and start from the instance-specific lower bound of the number of samples that have to be collected to identify a nearly-optimal policy. Deriving this lower bound along with the optimal exploration strategy entails solving an intricate optimization problem and requires a model of the system. In turn, most existing sample optimal exploration algorithms rely on estimating the model. We derive an approximation of the instance-specific lower bound that only involves quantities that can be inferred using model-free approaches. Leveraging this approximation, we devise an ensemble-based model-free exploration strategy applicable to both tabular and continuous Markov decision processes. Numerical results demonstrate that our strategy is able to identify efficient policies faster than state-of-the-art exploration approaches
Read more7/2/2024
🔍
0
Bayesian Exploration Networks
Mattie Fellows, Brandon Kaplowitz, Christian Schroeder de Witt, Shimon Whiteson
Bayesian reinforcement learning (RL) offers a principled and elegant approach for sequential decision making under uncertainty. Most notably, Bayesian agents do not face an exploration/exploitation dilemma, a major pathology of frequentist methods. However theoretical understanding of model-free approaches is lacking. In this paper, we introduce a novel Bayesian model-free formulation and the first analysis showing that model-free approaches can yield Bayes-optimal policies. We show all existing model-free approaches make approximations that yield policies that can be arbitrarily Bayes-suboptimal. As a first step towards model-free Bayes optimality, we introduce the Bayesian exploration network (BEN) which uses normalising flows to model both the aleatoric uncertainty (via density estimation) and epistemic uncertainty (via variational inference) in the Bellman operator. In the limit of complete optimisation, BEN learns true Bayes-optimal policies, but like in variational expectation-maximisation, partial optimisation renders our approach tractable. Empirical results demonstrate that BEN can learn true Bayes-optimal policies in tasks where existing model-free approaches fail.
Read more6/4/2024
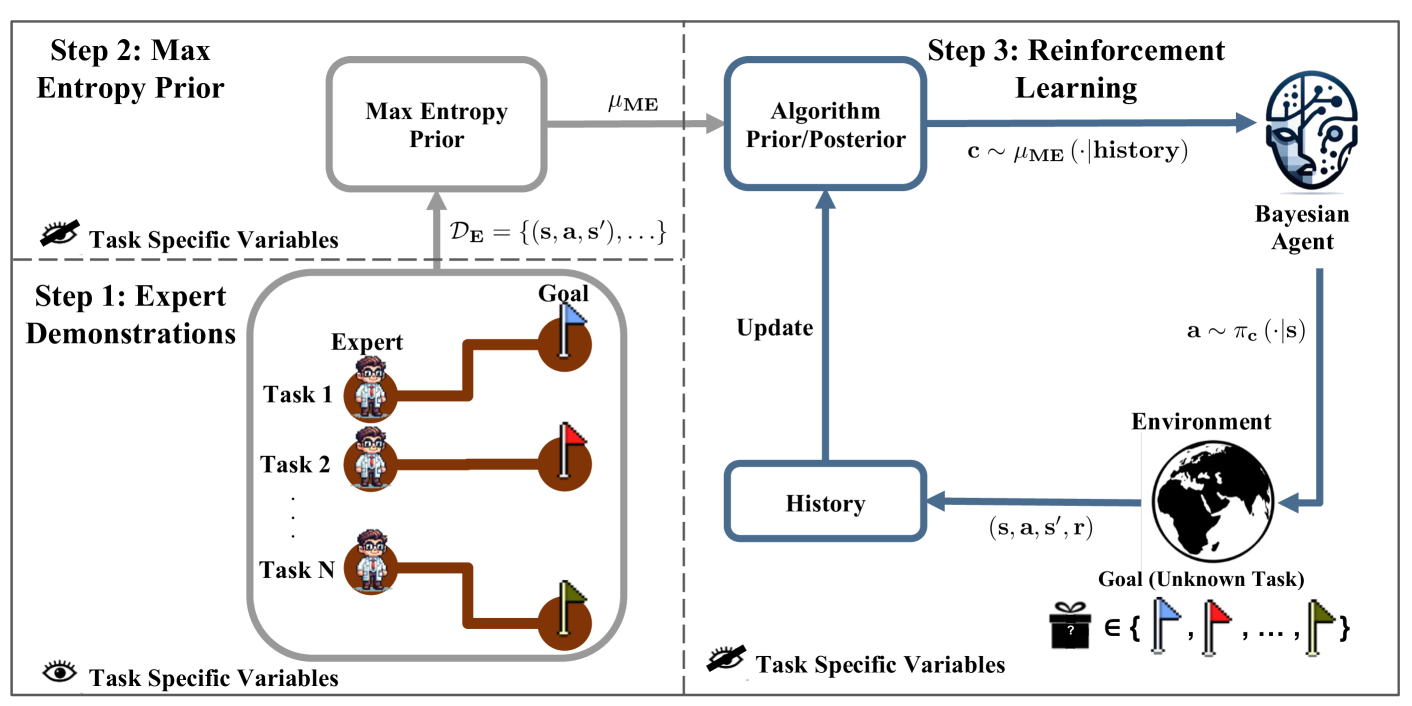
0
Sequential Decision Making with Expert Demonstrations under Unobserved Heterogeneity
Vahid Balazadeh, Keertana Chidambaram, Viet Nguyen, Rahul G. Krishnan, Vasilis Syrgkanis
We study the problem of online sequential decision-making given auxiliary demonstrations from experts who made their decisions based on unobserved contextual information. These demonstrations can be viewed as solving related but slightly different tasks than what the learner faces. This setting arises in many application domains, such as self-driving cars, healthcare, and finance, where expert demonstrations are made using contextual information, which is not recorded in the data available to the learning agent. We model the problem as a zero-shot meta-reinforcement learning setting with an unknown task distribution and a Bayesian regret minimization objective, where the unobserved tasks are encoded as parameters with an unknown prior. We propose the Experts-as-Priors algorithm (ExPerior), a non-parametric empirical Bayes approach that utilizes the principle of maximum entropy to establish an informative prior over the learner's decision-making problem. This prior enables the application of any Bayesian approach for online decision-making, such as posterior sampling. We demonstrate that our strategy surpasses existing behaviour cloning and online algorithms for multi-armed bandits and reinforcement learning, showcasing the utility of our approach in leveraging expert demonstrations across different decision-making setups.
Read more4/12/2024