SER Evals: In-domain and Out-of-domain Benchmarking for Speech Emotion Recognition

0

Sign in to get full access
Overview
- The paper "SER Evals: In-domain and Out-of-domain Benchmarking for Speech Emotion Recognition" presents a comprehensive evaluation of speech emotion recognition (SER) models on both in-domain and out-of-domain datasets.
- The researchers assess the performance of various state-of-the-art SER models across different emotional categories and investigate the factors that contribute to their generalization capabilities.
- The findings from this study provide valuable insights into the current state of SER technology and offer guidance for future research and development in this field.
Plain English Explanation
Speech emotion recognition (SER) is the ability of machines to identify the emotional state of a person based on their speech. This is an important capability for applications like intelligent personal assistants, customer service chatbots, and mental health monitoring systems.
The researchers in this paper wanted to understand how well current SER models perform when tested on data that is similar to the data they were trained on (in-domain) versus data that is quite different (out-of-domain). They evaluated several state-of-the-art SER models on a variety of datasets and looked at factors like how accurately the models could identify different emotional categories like happiness, sadness, anger, and fear.
The key findings from this study are:
- SER models generally perform better on in-domain data compared to out-of-domain data, indicating they struggle to generalize to new environments.
- Certain emotional categories, like anger and happiness, are easier for the models to recognize than others, like sadness and fear.
- The researchers provide guidelines and recommendations for future SER model development to improve cross-domain performance and robustness.
Overall, this paper offers a comprehensive assessment of the current capabilities and limitations of SER technology, which is valuable information for researchers and developers working to advance this field.
Technical Explanation
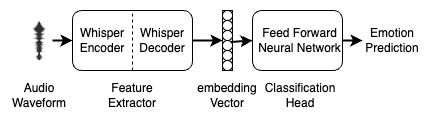
The paper evaluates the performance of several state-of-the-art SER models, including transformer-based architectures like BERT and ConvNet-based models, on both in-domain and out-of-domain datasets. The in-domain evaluation assesses how the models perform on data from the same distribution they were trained on, while the out-of-domain evaluation tests how well they generalize to new, unseen data.
The researchers used a diverse set of SER datasets covering a range of emotional categories, recording environments, and speaker demographics. They analyzed the models' classification accuracy for individual emotion classes as well as overall performance metrics like weighted F1-score.
The key findings from the experiments are:
- SER models achieve significantly higher performance on in-domain data compared to out-of-domain data, with up to a 15% drop in F1-score.
- Certain emotions like anger and happiness are easier for the models to recognize, while sadness and fear are more challenging.
- Model architecture plays a role, with transformer-based models generally outperforming ConvNet-based models in the out-of-domain setting.
- The researchers provide guidelines for dataset curation and model development to improve SER generalization capabilities.
Critical Analysis
The paper provides a thorough and systematic evaluation of SER models, which is valuable for understanding the current state-of-the-art and identifying areas for future research. However, some limitations and potential issues are worth noting:
- The study only considers a limited set of model architectures and does not explore advanced techniques like domain adaptation or meta-learning that could improve cross-domain performance.
- The emotional categories used in the datasets may not fully capture the nuanced and contextual nature of human emotions, which could impact the models' ability to generalize.
- The evaluation metrics, while standard, may not tell the whole story about model performance in real-world applications where factors like user experience and ethical considerations are also important.
Additionally, it would be interesting to see further analysis on the factors that contribute to the models' varying performance across emotion classes, such as the acoustic and linguistic cues associated with different emotions.
Conclusion
This paper presents a comprehensive benchmarking of SER models on both in-domain and out-of-domain data, providing valuable insights into the current capabilities and limitations of the technology. The findings highlight the need for more robust and generalizable SER systems that can perform well across diverse contexts and emotional expressions.
The researchers' guidelines for dataset curation and model development offer a roadmap for future work in this area, which is crucial as speech emotion recognition becomes increasingly important for a wide range of applications, from intelligent assistants to mental health monitoring. By addressing the challenges identified in this study, researchers and developers can work towards building more reliable and trustworthy SER systems that can better serve the needs of end-users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SER Evals: In-domain and Out-of-domain Benchmarking for Speech Emotion Recognition
Mohamed Osman, Daniel Z. Kaplan, Tamer Nadeem
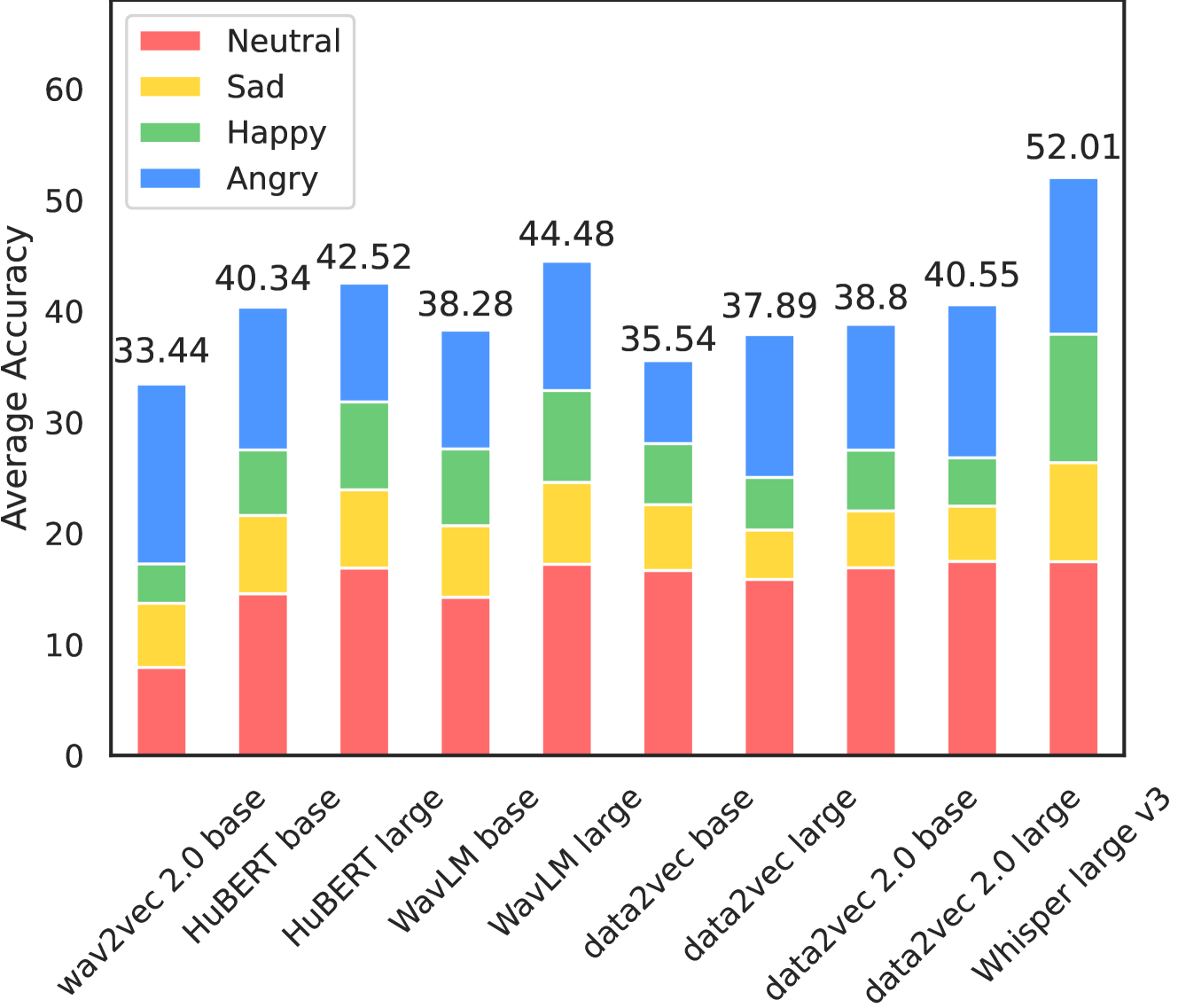
Speech emotion recognition (SER) has made significant strides with the advent of powerful self-supervised learning (SSL) models. However, the generalization of these models to diverse languages and emotional expressions remains a challenge. We propose a large-scale benchmark to evaluate the robustness and adaptability of state-of-the-art SER models in both in-domain and out-of-domain settings. Our benchmark includes a diverse set of multilingual datasets, focusing on less commonly used corpora to assess generalization to new data. We employ logit adjustment to account for varying class distributions and establish a single dataset cluster for systematic evaluation. Surprisingly, we find that the Whisper model, primarily designed for automatic speech recognition, outperforms dedicated SSL models in cross-lingual SER. Our results highlight the need for more robust and generalizable SER models, and our benchmark serves as a valuable resource to drive future research in this direction.
Read more8/16/2024
0
What Does it Take to Generalize SER Model Across Datasets? A Comprehensive Benchmark
Adham Ibrahim, Shady Shehata, Ajinkya Kulkarni, Mukhtar Mohamed, Muhammad Abdul-Mageed
Speech emotion recognition (SER) is essential for enhancing human-computer interaction in speech-based applications. Despite improvements in specific emotional datasets, there is still a research gap in SER's capability to generalize across real-world situations. In this paper, we investigate approaches to generalize the SER system across different emotion datasets. In particular, we incorporate 11 emotional speech datasets and illustrate a comprehensive benchmark on the SER task. We also address the challenge of imbalanced data distribution using over-sampling methods when combining SER datasets for training. Furthermore, we explore various evaluation protocols for adeptness in the generalization of SER. Building on this, we explore the potential of Whisper for SER, emphasizing the importance of thorough evaluation. Our approach is designed to advance SER technology by integrating speaker-independent methods.
Read more6/17/2024

0
SELM: Enhancing Speech Emotion Recognition for Out-of-Domain Scenarios
Hazim Bukhari, Soham Deshmukh, Hira Dhamyal, Bhiksha Raj, Rita Singh
Speech Emotion Recognition (SER) has been traditionally formulated as a classification task. However, emotions are generally a spectrum whose distribution varies from situation to situation leading to poor Out-of-Domain (OOD) performance. We take inspiration from statistical formulation of Automatic Speech Recognition (ASR) and formulate the SER task as generating the most likely sequence of text tokens to infer emotion. The formulation breaks SER into predicting acoustic model features weighted by language model prediction. As an instance of this approach, we present SELM, an audio-conditioned language model for SER that predicts different emotion views. We train SELM on curated speech emotion corpus and test it on three OOD datasets (RAVDESS, CREMAD, IEMOCAP) not used in training. SELM achieves significant improvements over the state-of-the-art baselines, with 17% and 7% relative accuracy gains for RAVDESS and CREMA-D, respectively. Moreover, SELM can further boost its performance by Few-Shot Learning using a few annotated examples. The results highlight the effectiveness of our SER formulation, especially to improve performance in OOD scenarios.
Read more7/23/2024
0
EmoBox: Multilingual Multi-corpus Speech Emotion Recognition Toolkit and Benchmark
Ziyang Ma, Mingjie Chen, Hezhao Zhang, Zhisheng Zheng, Wenxi Chen, Xiquan Li, Jiaxin Ye, Xie Chen, Thomas Hain
Speech emotion recognition (SER) is an important part of human-computer interaction, receiving extensive attention from both industry and academia. However, the current research field of SER has long suffered from the following problems: 1) There are few reasonable and universal splits of the datasets, making comparing different models and methods difficult. 2) No commonly used benchmark covers numerous corpus and languages for researchers to refer to, making reproduction a burden. In this paper, we propose EmoBox, an out-of-the-box multilingual multi-corpus speech emotion recognition toolkit, along with a benchmark for both intra-corpus and cross-corpus settings. For intra-corpus settings, we carefully designed the data partitioning for different datasets. For cross-corpus settings, we employ a foundation SER model, emotion2vec, to mitigate annotation errors and obtain a test set that is fully balanced in speakers and emotions distributions. Based on EmoBox, we present the intra-corpus SER results of 10 pre-trained speech models on 32 emotion datasets with 14 languages, and the cross-corpus SER results on 4 datasets with the fully balanced test sets. To the best of our knowledge, this is the largest SER benchmark, across language scopes and quantity scales. We hope that our toolkit and benchmark can facilitate the research of SER in the community.
Read more6/12/2024