What Does it Take to Generalize SER Model Across Datasets? A Comprehensive Benchmark
2406.09933
0
0
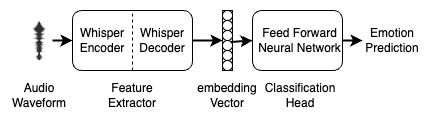
Abstract
Speech emotion recognition (SER) is essential for enhancing human-computer interaction in speech-based applications. Despite improvements in specific emotional datasets, there is still a research gap in SER's capability to generalize across real-world situations. In this paper, we investigate approaches to generalize the SER system across different emotion datasets. In particular, we incorporate 11 emotional speech datasets and illustrate a comprehensive benchmark on the SER task. We also address the challenge of imbalanced data distribution using over-sampling methods when combining SER datasets for training. Furthermore, we explore various evaluation protocols for adeptness in the generalization of SER. Building on this, we explore the potential of Whisper for SER, emphasizing the importance of thorough evaluation. Our approach is designed to advance SER technology by integrating speaker-independent methods.
Create account to get full access
Overview
- This paper presents a comprehensive benchmark to evaluate how well speech emotion recognition (SER) models can generalize across different datasets.
- The authors investigate various factors that may affect model generalization, such as dataset characteristics, model architectures, and training strategies.
- They conduct extensive experiments on multiple SER datasets and provide insights on what it takes for SER models to achieve robust cross-dataset performance.
Plain English Explanation
The paper examines the challenge of getting speech emotion recognition (SER) models to work well across different datasets. SER models are AI systems that can detect the emotional state of a person based on their voice. However, these models often struggle to perform well when applied to datasets they weren't trained on, a problem known as poor "generalization."
To address this, the authors conduct a thorough investigation, testing various SER models on multiple datasets. They look at factors like the characteristics of the datasets, the model architectures, and training strategies to understand what makes an SER model able to generalize well. The goal is to provide insights that can help developers build more robust and versatile SER systems.
Technical Explanation
The paper presents a comprehensive benchmark to evaluate the generalization capabilities of speech emotion recognition (SER) models across different datasets. The authors investigate several factors that may impact cross-dataset performance, including dataset characteristics, model architectures, and training strategies.
The experimental setup involves testing various SER models on multiple benchmark datasets. The authors evaluate the models' performance using standard metrics like accuracy and F1-score, and analyze the results to uncover patterns and identify the key drivers of cross-dataset generalization.
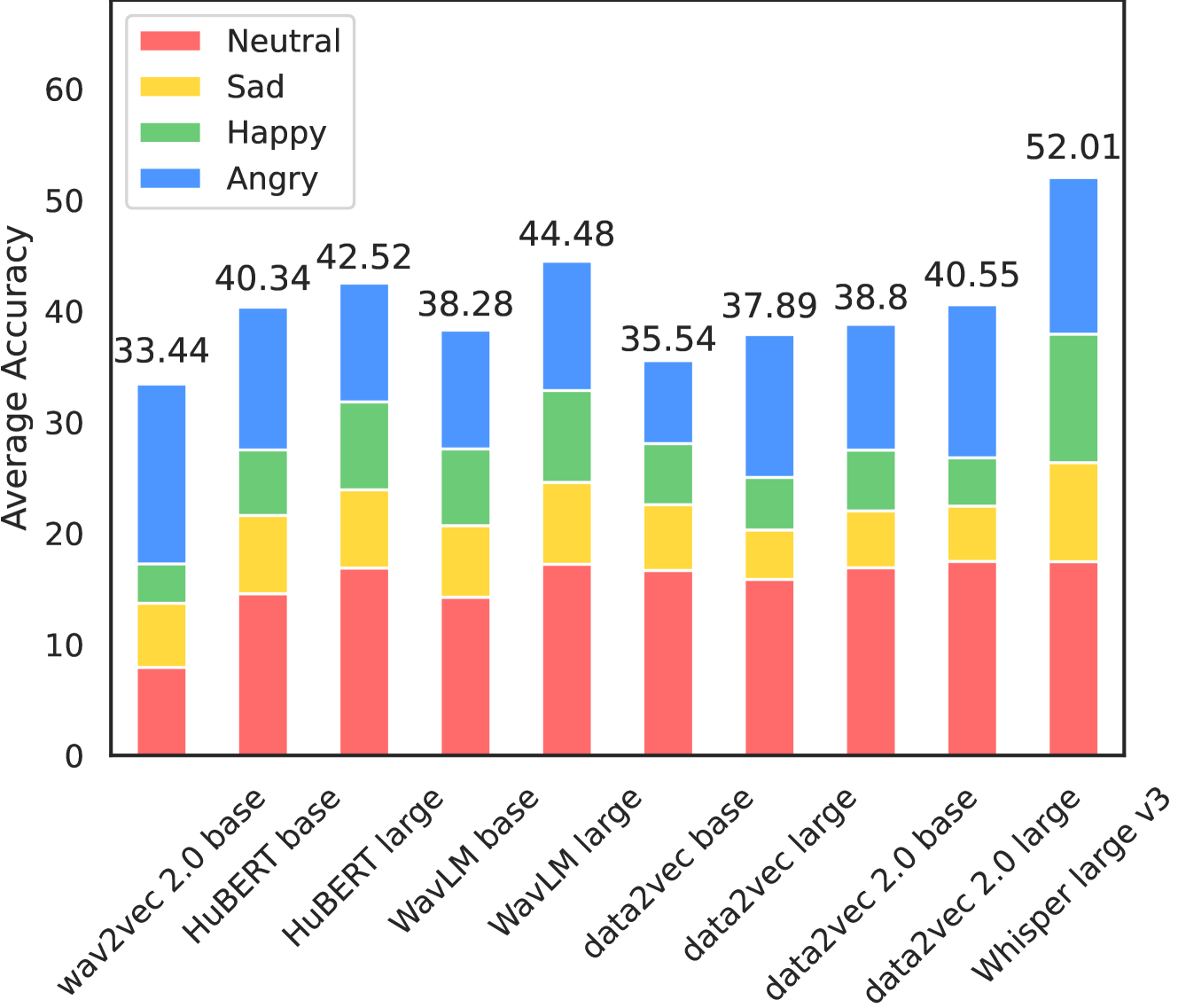
Through their experiments, the authors provide insights on the specific dataset properties, model design choices, and training techniques that can lead to improved generalization. For example, they find that dataset diversity and annotation quality are important factors, and that feature boosting strategies and explainable AI techniques can help overcome issues related to social biases in the data.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of SER model generalization, addressing an important challenge in the field. The authors' systematic approach and thorough experimentation allow them to draw valuable insights that can guide the development of more robust and versatile SER systems.
One potential limitation of the study is the reliance on existing benchmark datasets, which may not fully capture the diversity of real-world scenarios. Additionally, the authors acknowledge that their findings may be influenced by the specific models and training strategies they tested, and further research may be needed to validate the generalizability of their conclusions.
It would also be interesting to see the authors explore the impact of other factors, such as the use of multimodal (e.g., audio-visual) data or the incorporation of domain adaptation techniques, on cross-dataset generalization performance.
Conclusion
This paper presents a comprehensive benchmark for evaluating the cross-dataset generalization capabilities of speech emotion recognition models. The authors' systematic investigation of various factors, including dataset characteristics, model architectures, and training strategies, provides valuable insights that can inform the development of more robust and versatile SER systems.
The findings in this study have the potential to advance the field of emotion recognition, which is crucial for building more natural and empathetic human-AI interactions. By addressing the challenge of cross-dataset generalization, the research paves the way for SER models that can be reliably deployed in diverse real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
EmoBox: Multilingual Multi-corpus Speech Emotion Recognition Toolkit and Benchmark
Ziyang Ma, Mingjie Chen, Hezhao Zhang, Zhisheng Zheng, Wenxi Chen, Xiquan Li, Jiaxin Ye, Xie Chen, Thomas Hain
0
0
Speech emotion recognition (SER) is an important part of human-computer interaction, receiving extensive attention from both industry and academia. However, the current research field of SER has long suffered from the following problems: 1) There are few reasonable and universal splits of the datasets, making comparing different models and methods difficult. 2) No commonly used benchmark covers numerous corpus and languages for researchers to refer to, making reproduction a burden. In this paper, we propose EmoBox, an out-of-the-box multilingual multi-corpus speech emotion recognition toolkit, along with a benchmark for both intra-corpus and cross-corpus settings. For intra-corpus settings, we carefully designed the data partitioning for different datasets. For cross-corpus settings, we employ a foundation SER model, emotion2vec, to mitigate annotation errors and obtain a test set that is fully balanced in speakers and emotions distributions. Based on EmoBox, we present the intra-corpus SER results of 10 pre-trained speech models on 32 emotion datasets with 14 languages, and the cross-corpus SER results on 4 datasets with the fully balanced test sets. To the best of our knowledge, this is the largest SER benchmark, across language scopes and quantity scales. We hope that our toolkit and benchmark can facilitate the research of SER in the community.
6/12/2024

INTERSPEECH 2009 Emotion Challenge Revisited: Benchmarking 15 Years of Progress in Speech Emotion Recognition
Andreas Triantafyllopoulos, Anton Batliner, Simon Rampp, Manuel Milling, Bjorn Schuller
0
0
We revisit the INTERSPEECH 2009 Emotion Challenge -- the first ever speech emotion recognition (SER) challenge -- and evaluate a series of deep learning models that are representative of the major advances in SER research in the time since then. We start by training each model using a fixed set of hyperparameters, and further fine-tune the best-performing models of that initial setup with a grid search. Results are always reported on the official test set with a separate validation set only used for early stopping. Most models score below or close to the official baseline, while they marginally outperform the original challenge winners after hyperparameter tuning. Our work illustrates that, despite recent progress, FAU-AIBO remains a very challenging benchmark. An interesting corollary is that newer methods do not consistently outperform older ones, showing that progress towards `solving' SER is not necessarily monotonic.
6/11/2024

Iterative Feature Boosting for Explainable Speech Emotion Recognition
Alaa Nfissi, Wassim Bouachir, Nizar Bouguila, Brian Mishara
0
0
In speech emotion recognition (SER), using predefined features without considering their practical importance may lead to high dimensional datasets, including redundant and irrelevant information. Consequently, high-dimensional learning often results in decreasing model accuracy while increasing computational complexity. Our work underlines the importance of carefully considering and analyzing features in order to build efficient SER systems. We present a new supervised SER method based on an efficient feature engineering approach. We pay particular attention to the explainability of results to evaluate feature relevance and refine feature sets. This is performed iteratively through feature evaluation loop, using Shapley values to boost feature selection and improve overall framework performance. Our approach allows thus to balance the benefits between model performance and transparency. The proposed method outperforms human-level performance (HLP) and state-of-the-art machine learning methods in emotion recognition on the TESS dataset. The source code of this paper is publicly available at https://github.com/alaaNfissi/Iterative-Feature-Boosting-for-Explainable-Speech-Emotion-Recognition.
6/7/2024
🗣️
Speech Emotion Recognition under Resource Constraints with Data Distillation
Yi Chang, Zhao Ren, Zhonghao Zhao, Thanh Tam Nguyen, Kun Qian, Tanja Schultz, Bjorn W. Schuller
0
0
Speech emotion recognition (SER) plays a crucial role in human-computer interaction. The emergence of edge devices in the Internet of Things (IoT) presents challenges in constructing intricate deep learning models due to constraints in memory and computational resources. Moreover, emotional speech data often contains private information, raising concerns about privacy leakage during the deployment of SER models. To address these challenges, we propose a data distillation framework to facilitate efficient development of SER models in IoT applications using a synthesised, smaller, and distilled dataset. Our experiments demonstrate that the distilled dataset can be effectively utilised to train SER models with fixed initialisation, achieving performances comparable to those developed using the original full emotional speech dataset.
6/24/2024