Set the Clock: Temporal Alignment of Pretrained Language Models
2402.16797
0
0
Abstract
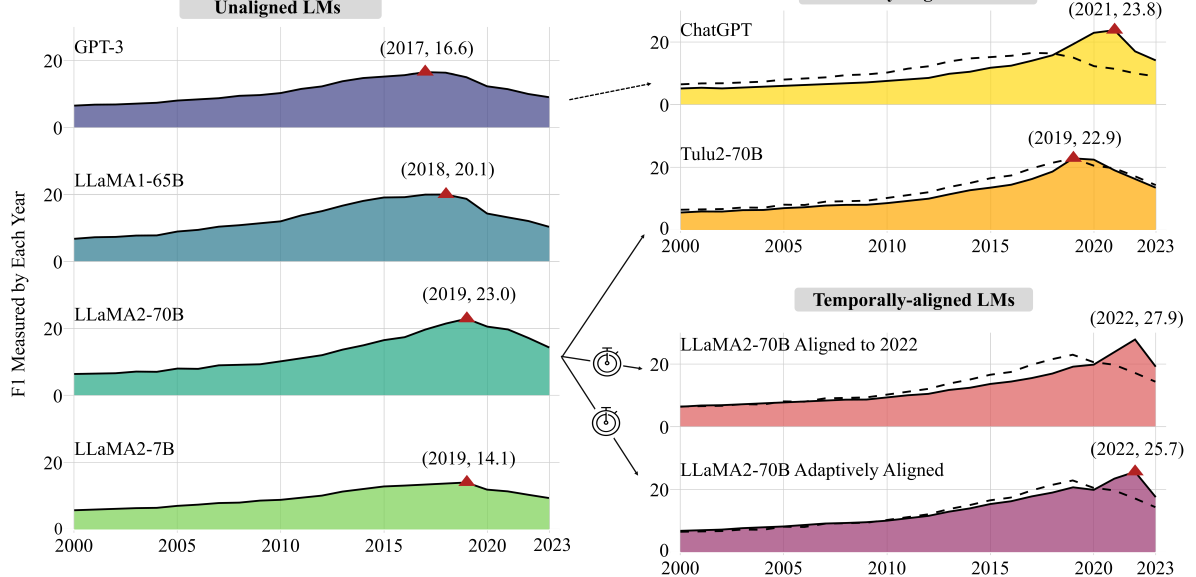
Language models (LMs) are trained on web text originating from many points in time and, in general, without any explicit temporal grounding. This work investigates the temporal chaos of pretrained LMs and explores various methods to align their internal knowledge to a target time, which we call temporal alignment. To do this, we first automatically construct a dataset containing 20K time-sensitive questions and their answers for each year from 2000 to 2023. Based on this dataset, we empirically show that pretrained LMs (e.g., LLaMa2), despite having a recent pretraining cutoff (e.g., 2022), mostly answer questions using earlier knowledge (e.g., in 2019). We then develop several methods, from prompting to finetuning, to align LMs to use their most recent knowledge when answering questions, and investigate various factors in this alignment. Our experiments demonstrate that aligning LLaMa2 to the year 2022 can enhance its performance by up to 62% according to that year's answers. This improvement occurs even without explicitly mentioning time information, indicating the possibility of aligning models' internal sense of time after pretraining. Finally, we find that alignment to a historical time is also possible, with up to 2.8$times$ the performance of the unaligned LM in 2010 if finetuning models to that year. These findings hint at the sophistication of LMs' internal knowledge organization and the necessity of tuning them properly.
Create account to get full access
Overview
- This paper explores the concept of temporal alignment in pretrained language models (LMs), which refers to the ability of LMs to accurately model language use and evolution over time.
- The authors introduce a new question-answering (QA) dataset called TAQA that is designed to evaluate the temporal alignment of LMs.
- The paper presents experiments using TAQA to assess the temporal alignment capabilities of various LMs, and discusses the implications for real-world applications.
Plain English Explanation
Towards Effective Time-Aware Language Representation Exploring is a technical paper that looks at how well language models (LMs) can understand and use language that changes over time. The authors created a new dataset called TAQA that tests this "temporal alignment" of LMs - how well they can handle language that evolves or refers to different time periods.
The key idea is that language is not static - words, phrases, and even ideas can change meaning or usage over time. For example, the word "cool" used to just mean cold, but now commonly means something is good or interesting. LMs need to be able to understand and work with this temporal aspect of language to be truly effective.
The authors use TAQA to evaluate how well different LMs can handle temporally-sensitive language tasks. This helps identify strengths and weaknesses in current LM capabilities when it comes to modeling language change. The findings have implications for real-world applications like search engines, assistants, and other systems that need to understand and communicate using up-to-date language.
Technical Explanation
The paper introduces the concept of temporal alignment in pretrained language models (LMs), which refers to the ability of LMs to accurately model language use and evolution over time. To study this, the authors create a new question-answering (QA) dataset called TAQA that contains temporally-sensitive questions designed to test an LM's temporal alignment.
The TAQA dataset is constructed by crowdsourcing questions that require understanding of language across different time periods. For example, a question might ask about the meaning of a word or phrase at a specific historical point in time. The dataset also includes questions that require reasoning about events, entities, or cultural references from different eras.
The authors then use TAQA to evaluate the temporal alignment of various popular pretrained LMs, including BERT, RoBERTa, and GPT-2/3. Their experiments show that while these LMs perform reasonably well on standard QA tasks, they struggle with questions that require understanding of how language and concepts have changed over time.
The results highlight important limitations in the temporal generalization capabilities of current LMs, and suggest that more work is needed to develop LMs that can effectively model and reason about the dynamic nature of language. The authors discuss potential approaches for improving temporal alignment, such as incorporating explicit temporal information or fine-tuning on historical data.
Critical Analysis
The paper provides a valuable contribution by introducing the concept of temporal alignment and the TAQA dataset as a tool for evaluating this important aspect of language model performance. Is Your LLM Outdated? Benchmarking LLMs' Alignment and Language Models Resist Alignment have also explored similar ideas around the temporal challenges for large language models.
One potential limitation of the TAQA dataset is that it may not fully capture the nuances and complexities of real-world language evolution. The questions are designed to test specific temporal reasoning abilities, but language change can be subtle and contextual. Systematic Analysis of Temporal Generalization in Language Models on Social Media has explored more naturalistic datasets that could complement TAQA.
Additionally, while the experiments demonstrate shortcomings in the temporal alignment of current LMs, the paper does not provide a comprehensive solution. Further research is needed to develop effective techniques for improving the temporal awareness and generalization capabilities of language models, as discussed in Evaluating LLMs' Ability to Evaluate Temporal Generalization.
Overall, this paper makes an important contribution by highlighting a critical area for language model development and providing a valuable dataset and methodology for further exploration and advancement in the field.
Conclusion
This paper presents a novel approach to studying the temporal alignment of pretrained language models (LMs). By introducing the TAQA dataset, the authors have created a valuable tool for evaluating how well LMs can handle language that evolves over time.
The experimental results demonstrate significant limitations in the temporal generalization capabilities of current state-of-the-art LMs, suggesting that more work is needed to develop models that can effectively reason about and adapt to the dynamic nature of language. Addressing these challenges will be crucial for building language technologies that can truly understand and communicate in a temporally-aware manner, with important implications for a wide range of real-world applications.
The paper provides a solid foundation for further research in this area, and the insights gained can help guide the development of more advanced, temporally-aligned language models that can better serve the needs of users in an ever-changing linguistic landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Towards Effective Time-Aware Language Representation: Exploring Enhanced Temporal Understanding in Language Models
Jiexin Wang, Adam Jatowt, Yi Cai
0
0
In the evolving field of Natural Language Processing, understanding the temporal context of text is increasingly crucial. This study investigates methods to incorporate temporal information during pre-training, aiming to achieve effective time-aware language representation for improved performance on time-related tasks. In contrast to common pre-trained models like BERT, which rely on synchronic document collections such as BookCorpus and Wikipedia, our research introduces BiTimeBERT 2.0, a novel language model pre-trained on a temporal news article collection. BiTimeBERT 2.0 utilizes this temporal news collection, focusing on three innovative pre-training objectives: Time-Aware Masked Language Modeling (TAMLM), Document Dating (DD), and Time-Sensitive Entity Replacement (TSER). Each objective targets a unique aspect of temporal information. TAMLM is designed to enhance the understanding of temporal contexts and relations, DD integrates document timestamps as chronological markers, and TSER focuses on the temporal dynamics of Person entities, recognizing their inherent temporal significance. The experimental results consistently demonstrate that BiTimeBERT 2.0 outperforms models like BERT and other existing pre-trained models, achieving substantial gains across a variety of downstream NLP tasks and applications where time plays a pivotal role.
6/5/2024
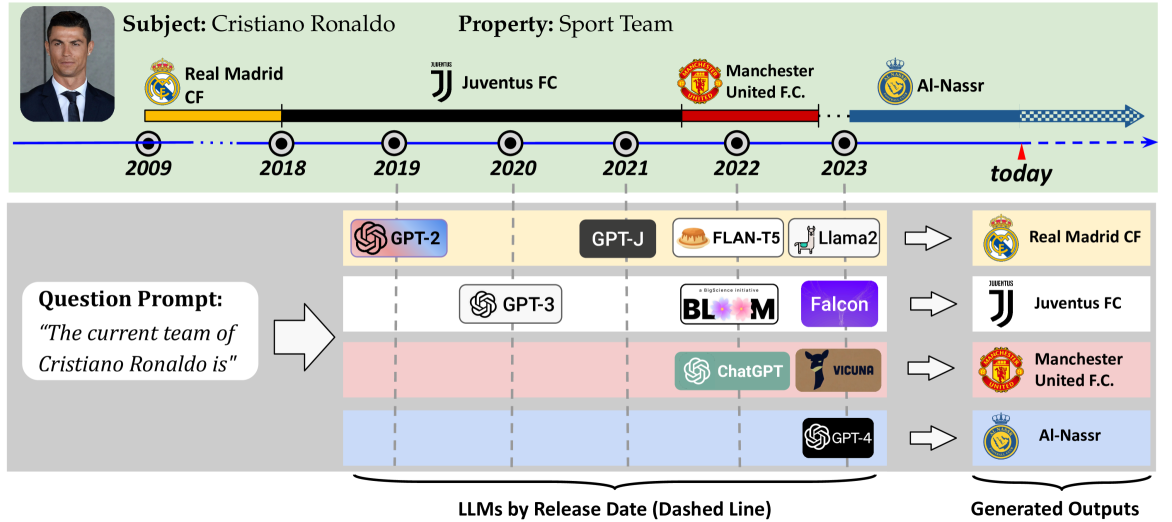
Is Your LLM Outdated? Benchmarking LLMs & Alignment Algorithms for Time-Sensitive Knowledge
Seyed Mahed Mousavi, Simone Alghisi, Giuseppe Riccardi
0
0
LLMs acquire knowledge from massive data snapshots collected at different timestamps. Their knowledge is then commonly evaluated using static benchmarks. However, factual knowledge is generally subject to time-sensitive changes, and static benchmarks cannot address those cases. We present an approach to dynamically evaluate the knowledge in LLMs and their time-sensitiveness against Wikidata, a publicly available up-to-date knowledge graph. We evaluate the time-sensitive knowledge in twenty-four private and open-source LLMs, as well as the effectiveness of four editing methods in updating the outdated facts. Our results show that 1) outdatedness is a critical problem across state-of-the-art LLMs; 2) LLMs output inconsistent answers when prompted with slight variations of the question prompt; and 3) the performance of the state-of-the-art knowledge editing algorithms is very limited, as they can not reduce the cases of outdatedness and output inconsistency.
6/13/2024
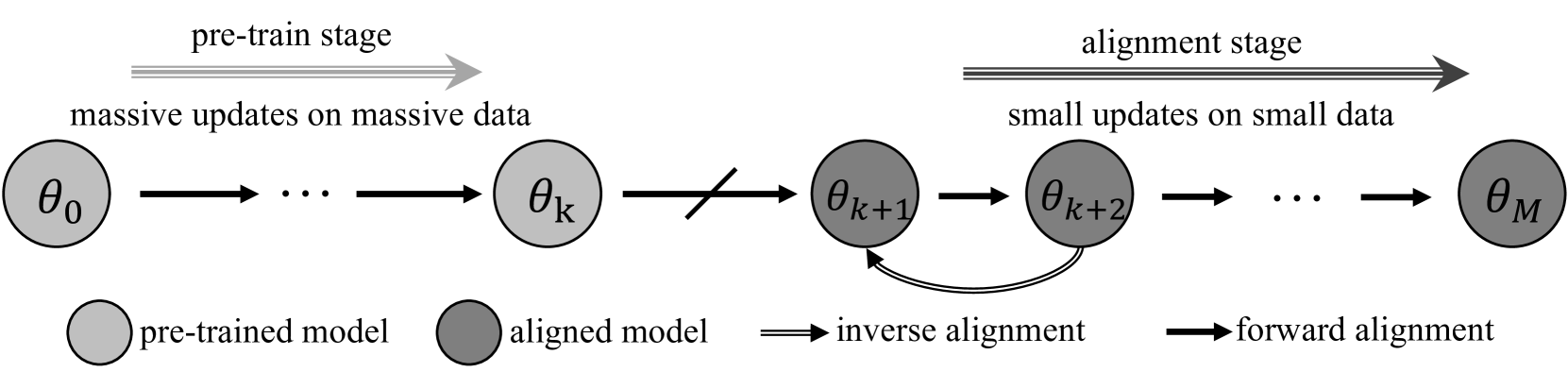
Language Models Resist Alignment
Jiaming Ji, Kaile Wang, Tianyi Qiu, Boyuan Chen, Jiayi Zhou, Changye Li, Hantao Lou, Yaodong Yang
0
0
Large language models (LLMs) may exhibit undesirable behaviors. Recent efforts have focused on aligning these models to prevent harmful generation. Despite these efforts, studies have shown that even a well-conducted alignment process can be easily circumvented, whether intentionally or accidentally. Do alignment fine-tuning have robust effects on models, or are merely superficial? In this work, we answer this question through both theoretical and empirical means. Empirically, we demonstrate the elasticity of post-alignment models, i.e., the tendency to revert to the behavior distribution formed during the pre-training phase upon further fine-tuning. Using compression theory, we formally derive that such fine-tuning process disproportionately undermines alignment compared to pre-training, potentially by orders of magnitude. We conduct experimental validations to confirm the presence of elasticity across models of varying types and sizes. Specifically, we find that model performance declines rapidly before reverting to the pre-training distribution, after which the rate of decline drops significantly. We further reveal that elasticity positively correlates with increased model size and the expansion of pre-training data. Our discovery signifies the importance of taming the inherent elasticity of LLMs, thereby overcoming the resistance of LLMs to alignment finetuning.
6/14/2024
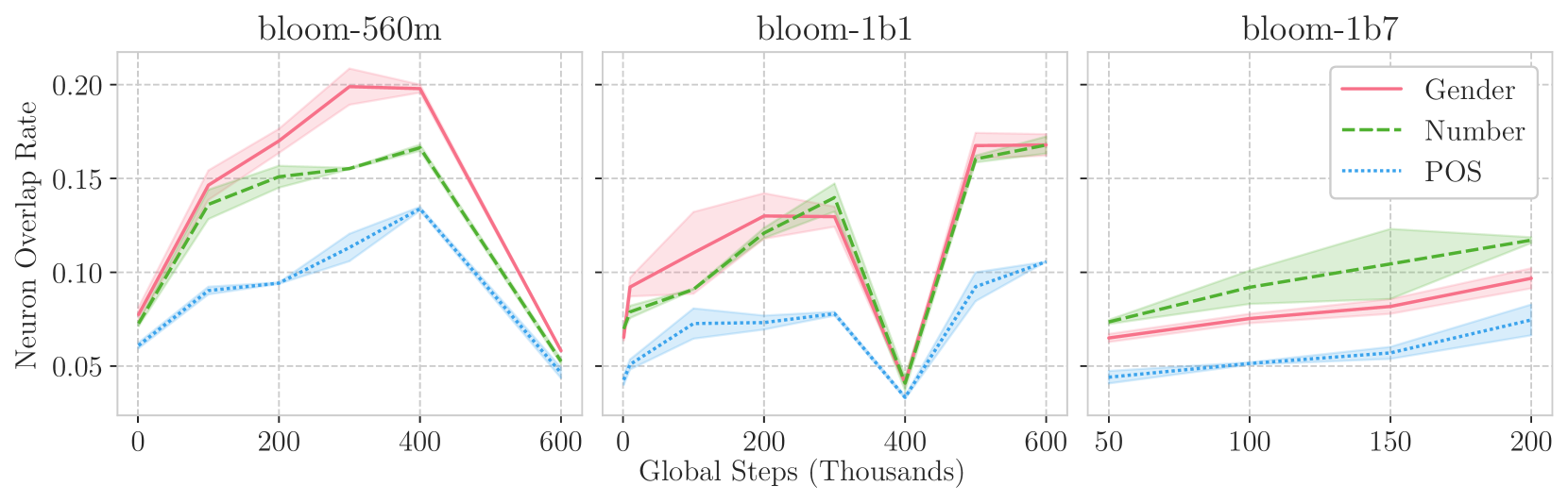
Probing the Emergence of Cross-lingual Alignment during LLM Training
Hetong Wang, Pasquale Minervini, Edoardo M. Ponti
0
0
Multilingual Large Language Models (LLMs) achieve remarkable levels of zero-shot cross-lingual transfer performance. We speculate that this is predicated on their ability to align languages without explicit supervision from parallel sentences. While representations of translationally equivalent sentences in different languages are known to be similar after convergence, however, it remains unclear how such cross-lingual alignment emerges during pre-training of LLMs. Our study leverages intrinsic probing techniques, which identify which subsets of neurons encode linguistic features, to correlate the degree of cross-lingual neuron overlap with the zero-shot cross-lingual transfer performance for a given model. In particular, we rely on checkpoints of BLOOM, a multilingual autoregressive LLM, across different training steps and model scales. We observe a high correlation between neuron overlap and downstream performance, which supports our hypothesis on the conditions leading to effective cross-lingual transfer. Interestingly, we also detect a degradation of both implicit alignment and multilingual abilities in certain phases of the pre-training process, providing new insights into the multilingual pretraining dynamics.
6/21/2024