RoScenes: A Large-scale Multi-view 3D Dataset for Roadside Perception

0
Sign in to get full access
Overview
- Introduces a large-scale, multi-view 3D dataset called RoScenes for roadside perception tasks
- Provides diverse and comprehensive data for training and evaluating 3D perception models in autonomous driving applications
- Includes various scenarios, camera configurations, and annotated 3D labels for objects, road surfaces, and other elements
Plain English Explanation
The paper presents a new dataset called RoScenes that is designed to help develop and test 3D computer vision systems for autonomous driving. The dataset contains a large collection of images and 3D data captured from multiple cameras mounted on vehicles driving along roads. These images and 3D data are annotated to identify and label different objects, road surfaces, and other elements that a self-driving car's perception system would need to detect and understand.
The key innovation of RoScenes is that it provides a much richer and more diverse set of data compared to previous datasets. It includes a wide variety of driving scenarios, camera configurations, and annotated 3D information that can be used to train more robust and capable 3D perception models. This is important because autonomous driving systems need to be able to accurately perceive and understand the full 3D environment around the vehicle in order to navigate safely.
By making this dataset publicly available, the researchers hope to accelerate progress in BEV perception, 3D object detection, and other key technologies for self-driving cars. The diverse data in RoScenes can be used to train and evaluate a wide range of 3D perception models in a more realistic and comprehensive way than has been possible before.
Technical Explanation
The RoScenes dataset was collected using a multi-camera setup installed on a fleet of vehicles driving in urban and suburban environments. It includes over 1 million images and corresponding 3D point clouds captured from various viewpoints around the vehicle. The data covers a diverse set of road scenarios, weather conditions, and traffic situations.
Each frame in the dataset is annotated with 3D bounding boxes, segmentation masks, and other metadata for a variety of objects, including vehicles, pedestrians, cyclists, traffic signs, and road infrastructure. The annotations also include detailed 3D reconstructions of the road surface and surrounding environments.
The researchers designed RoScenes to address key limitations of existing 3D perception datasets, which tend to have limited diversity, lack comprehensive 3D annotations, or focus only on the view directly in front of the vehicle. In contrast, RoScenes provides a more holistic and representative dataset for training and evaluating BEV perception and roadside 3D object detection models.
The paper also introduces several baseline models and evaluation metrics for assessing 3D perception performance on the RoScenes dataset. These include adaptations of popular architectures like SGV3D and SEVD for the specific tasks and data distribution of the RoScenes benchmark.
Critical Analysis
The RoScenes dataset represents a valuable contribution to the field of autonomous driving research. By providing a large-scale, diverse, and comprehensive 3D perception dataset, the authors have addressed an important gap in existing benchmarks. The detailed annotations and variety of scenarios will enable the development of more robust and capable 3D perception models.
However, the paper does not fully address potential biases or limitations in the data collection process. For example, the geographic distribution of the data is not clearly specified, and the dataset may over-represent certain types of environments or road infrastructure. Additionally, the paper does not discuss the cost and logistics of scaling up the data collection process to maintain and expand the RoScenes dataset over time.
Further research could also explore ways to incorporate distortion-aware fisheye camera data or synthetic data generation to enhance the realism and diversity of the RoScenes dataset. Evaluating the performance of 3D perception models on edge cases or rare scenarios could also provide valuable insights.
Conclusion
The RoScenes dataset represents a significant advancement in the field of 3D perception for autonomous driving. By providing a large-scale, multi-view dataset with comprehensive 3D annotations, the researchers have enabled the development of more robust and capable 3D perception models. The diverse set of scenarios and camera configurations captured in RoScenes will help push the boundaries of what is possible in BEV perception, 3D object detection, and other key technologies for self-driving cars. The public release of this dataset is a valuable contribution that will accelerate progress in this critical area of autonomous driving research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RoScenes: A Large-scale Multi-view 3D Dataset for Roadside Perception
Xiaosu Zhu, Hualian Sheng, Sijia Cai, Bing Deng, Shaopeng Yang, Qiao Liang, Ken Chen, Lianli Gao, Jingkuan Song, Jieping Ye
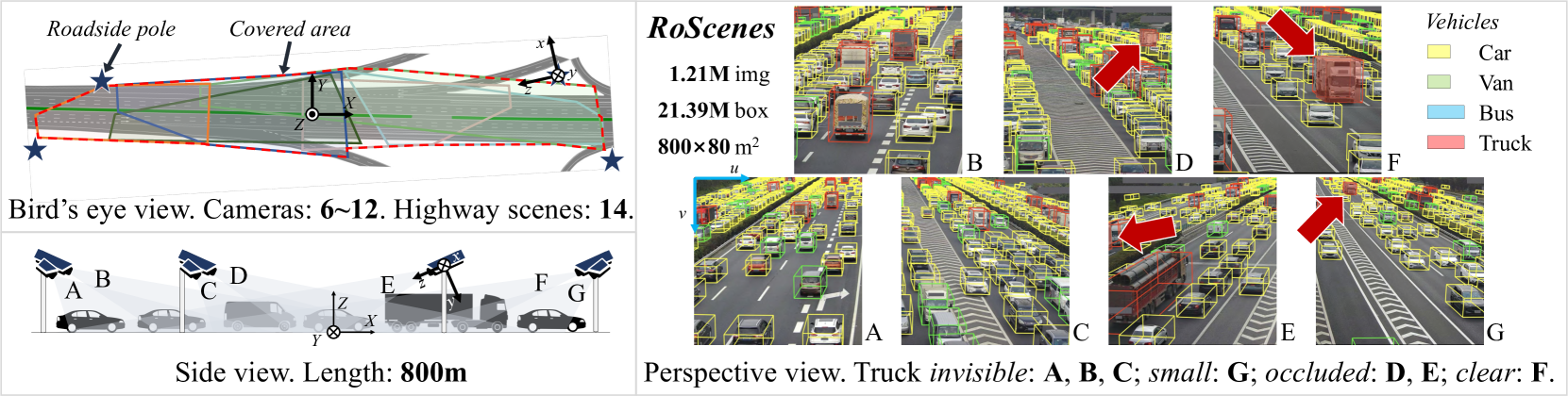
We introduce RoScenes, the largest multi-view roadside perception dataset, which aims to shed light on the development of vision-centric Bird's Eye View (BEV) approaches for more challenging traffic scenes. The highlights of RoScenes include significantly large perception area, full scene coverage and crowded traffic. More specifically, our dataset achieves surprising 21.13M 3D annotations within 64,000 $m^2$. To relieve the expensive costs of roadside 3D labeling, we present a novel BEV-to-3D joint annotation pipeline to efficiently collect such a large volume of data. After that, we organize a comprehensive study for current BEV methods on RoScenes in terms of effectiveness and efficiency. Tested methods suffer from the vast perception area and variation of sensor layout across scenes, resulting in performance levels falling below expectations. To this end, we propose RoBEV that incorporates feature-guided position embedding for effective 2D-3D feature assignment. With its help, our method outperforms state-of-the-art by a large margin without extra computational overhead on validation set. Our dataset and devkit will be made available at https://github.com/xiaosu-zhu/RoScenes.
Read more7/8/2024

0
RopeBEV: A Multi-Camera Roadside Perception Network in Bird's-Eye-View
Jinrang Jia, Guangqi Yi, Yifeng Shi
Multi-camera perception methods in Bird's-Eye-View (BEV) have gained wide application in autonomous driving. However, due to the differences between roadside and vehicle-side scenarios, there currently lacks a multi-camera BEV solution in roadside. This paper systematically analyzes the key challenges in multi-camera BEV perception for roadside scenarios compared to vehicle-side. These challenges include the diversity in camera poses, the uncertainty in Camera numbers, the sparsity in perception regions, and the ambiguity in orientation angles. In response, we introduce RopeBEV, the first dense multi-camera BEV approach. RopeBEV introduces BEV augmentation to address the training balance issues caused by diverse camera poses. By incorporating CamMask and ROIMask (Region of Interest Mask), it supports variable camera numbers and sparse perception, respectively. Finally, camera rotation embedding is utilized to resolve orientation ambiguity. Our method ranks 1st on the real-world highway dataset RoScenes and demonstrates its practical value on a private urban dataset that covers more than 50 intersections and 600 cameras.
Read more9/19/2024

0
SGV3D:Towards Scenario Generalization for Vision-based Roadside 3D Object Detection
Lei Yang, Xinyu Zhang, Jun Li, Li Wang, Chuang Zhang, Li Ju, Zhiwei Li, Yang Shen
Roadside perception can greatly increase the safety of autonomous vehicles by extending their perception ability beyond the visual range and addressing blind spots. However, current state-of-the-art vision-based roadside detection methods possess high accuracy on labeled scenes but have inferior performance on new scenes. This is because roadside cameras remain stationary after installation and can only collect data from a single scene, resulting in the algorithm overfitting these roadside backgrounds and camera poses. To address this issue, in this paper, we propose an innovative Scenario Generalization Framework for Vision-based Roadside 3D Object Detection, dubbed SGV3D. Specifically, we employ a Background-suppressed Module (BSM) to mitigate background overfitting in vision-centric pipelines by attenuating background features during the 2D to bird's-eye-view projection. Furthermore, by introducing the Semi-supervised Data Generation Pipeline (SSDG) using unlabeled images from new scenes, diverse instance foregrounds with varying camera poses are generated, addressing the risk of overfitting specific camera poses. We evaluate our method on two large-scale roadside benchmarks. Our method surpasses all previous methods by a significant margin in new scenes, including +42.57% for vehicle, +5.87% for pedestrian, and +14.89% for cyclist compared to BEVHeight on the DAIR-V2X-I heterologous benchmark. On the larger-scale Rope3D heterologous benchmark, we achieve notable gains of 14.48% for car and 12.41% for large vehicle. We aspire to contribute insights on the exploration of roadside perception techniques, emphasizing their capability for scenario generalization. The code will be available at https://github.com/yanglei18/SGV3D
Read more4/10/2024

0
WayveScenes101: A Dataset and Benchmark for Novel View Synthesis in Autonomous Driving
Jannik Zurn, Paul Gladkov, Sof'ia Dudas, Fergal Cotter, Sofi Toteva, Jamie Shotton, Vasiliki Simaiaki, Nikhil Mohan
We present WayveScenes101, a dataset designed to help the community advance the state of the art in novel view synthesis that focuses on challenging driving scenes containing many dynamic and deformable elements with changing geometry and texture. The dataset comprises 101 driving scenes across a wide range of environmental conditions and driving scenarios. The dataset is designed for benchmarking reconstructions on in-the-wild driving scenes, with many inherent challenges for scene reconstruction methods including image glare, rapid exposure changes, and highly dynamic scenes with significant occlusion. Along with the raw images, we include COLMAP-derived camera poses in standard data formats. We propose an evaluation protocol for evaluating models on held-out camera views that are off-axis from the training views, specifically testing the generalisation capabilities of methods. Finally, we provide detailed metadata for all scenes, including weather, time of day, and traffic conditions, to allow for a detailed model performance breakdown across scene characteristics. Dataset and code are available at https://github.com/wayveai/wayve_scenes.
Read more7/12/2024