Rendering-Enhanced Automatic Image-to-Point Cloud Registration for Roadside Scenes
2404.05164
0
0

Abstract
Prior point cloud provides 3D environmental context, which enhances the capabilities of monocular camera in downstream vision tasks, such as 3D object detection, via data fusion. However, the absence of accurate and automated registration methods for estimating camera extrinsic parameters in roadside scene point clouds notably constrains the potential applications of roadside cameras. This paper proposes a novel approach for the automatic registration between prior point clouds and images from roadside scenes. The main idea involves rendering photorealistic grayscale views taken at specific perspectives from the prior point cloud with the help of their features like RGB or intensity values. These generated views can reduce the modality differences between images and prior point clouds, thereby improve the robustness and accuracy of the registration results. Particularly, we specify an efficient algorithm, named neighbor rendering, for the rendering process. Then we introduce a method for automatically estimating the initial guess using only rough guesses of camera's position. At last, we propose a procedure for iteratively refining the extrinsic parameters by minimizing the reprojection error for line features extracted from both generated and camera images using Segment Anything Model (SAM). We assess our method using a self-collected dataset, comprising eight cameras strategically positioned throughout the university campus. Experiments demonstrate our method's capability to automatically align prior point cloud with roadside camera image, achieving a rotation accuracy of 0.202 degrees and a translation precision of 0.079m. Furthermore, we validate our approach's effectiveness in visual applications by substantially improving monocular 3D object detection performance.
Create account to get full access
Overview
- This paper presents a new approach for automatically registering images to point cloud data in roadside scenes.
- The key innovation is the use of rendering-enhanced techniques to improve the registration accuracy and robustness.
- The method leverages 3D point cloud data and images captured from roadside scenes to enable applications like MOSE: Boosting Vision-Based Roadside 3D Object Detection and NeRF2Points: Large-Scale Point Cloud Generation from Neural Radiance Fields.
Plain English Explanation
The paper describes a new way to automatically match up camera images and 3D point cloud data of roadside scenes. This is an important problem because being able to align these two types of data enables a range of applications, like detecting 3D objects in the roadside environment using vision-based techniques (MOSE: Boosting Vision-Based Roadside 3D Object Detection) or generating large-scale 3D point clouds from neural radiance fields (NeRF2Points: Large-Scale Point Cloud Generation from Neural Radiance Fields).
The key innovation in this paper is the use of rendering-enhanced techniques to improve the accuracy and robustness of the image-to-point cloud registration process. Rather than just trying to directly match features between the 2D images and 3D point cloud, the method also generates synthetic renderings of the point cloud from different viewpoints and uses those to guide the registration. This helps overcome challenges like occlusions, lighting variations, and other factors that can make the direct matching difficult.
The authors demonstrate the effectiveness of their approach on real-world roadside scenes, showing that it can achieve more accurate and reliable registration compared to prior methods. This paves the way for more advanced applications that rely on combining camera images and 3D point cloud data, like Roadside Monocular 3D Detection via 2D Detection, Few-Shot Point Cloud Reconstruction & Denoising via Self-Supervision, and Holistic Inverse Rendering of Complex Facade via Aerial.
Technical Explanation
The paper presents a novel approach for automatic image-to-point cloud registration in roadside scenes. The key technical innovation is the integration of rendering-enhanced techniques to improve the accuracy and robustness of the registration process.
The method starts by extracting salient features from both the input camera images and the 3D point cloud data. It then generates synthetic renderings of the 3D point cloud from different viewpoints using a differentiable rendering module. These renderings are used to guide the feature matching and registration optimization, helping to overcome challenges like occlusions, lighting variations, and other factors that can hinder direct feature-based matching.
The authors formulate the registration as an optimization problem, iteratively updating the camera pose parameters to minimize the distance between the projected 2D image features and the corresponding 3D point cloud features. The rendering-enhanced terms in the objective function encourage the optimization to converge to a more accurate and stable solution.
Extensive experiments on real-world roadside datasets demonstrate the effectiveness of the proposed method compared to prior state-of-the-art approaches. The rendering-enhanced technique is shown to significantly improve registration accuracy, robustness to occlusions, and computational efficiency.
Critical Analysis
The paper presents a well-designed and technically sound approach for addressing the important problem of image-to-point cloud registration in roadside scenes. The use of rendering-enhanced techniques is a clever and effective innovation that helps overcome key challenges in this task.
One potential limitation is that the method relies on the availability of high-quality 3D point cloud data, which may not always be readily available in all roadside environments. The authors mention that their approach can handle sparse or noisy point clouds to some degree, but it would be interesting to see how it performs in more extreme cases.
Additionally, the paper focuses on the registration task itself, but does not delve into the downstream applications that could benefit from this capability, such as Roadside Monocular 3D Detection via 2D Detection, Few-Shot Point Cloud Reconstruction & Denoising via Self-Supervision, or Holistic Inverse Rendering of Complex Facade via Aerial. Exploring the performance and integration of this registration technique within these broader systems could be a fruitful direction for future research.
Conclusion
This paper presents a novel rendering-enhanced approach for automatically registering images to 3D point cloud data in roadside scenes. The key innovation is the use of differentiable rendering to guide the feature matching and optimization process, which helps overcome challenges like occlusions and lighting variations that can hinder traditional registration methods.
The authors demonstrate the effectiveness of their approach on real-world datasets, showing significant improvements in registration accuracy and robustness compared to prior state-of-the-art techniques. This work paves the way for more advanced applications that rely on the seamless integration of 2D image and 3D point cloud data, such as MOSE: Boosting Vision-Based Roadside 3D Object Detection and NeRF2Points: Large-Scale Point Cloud Generation from Neural Radiance Fields. The proposed rendering-enhanced registration technique is a valuable contribution to the field of 3D computer vision and its applications in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
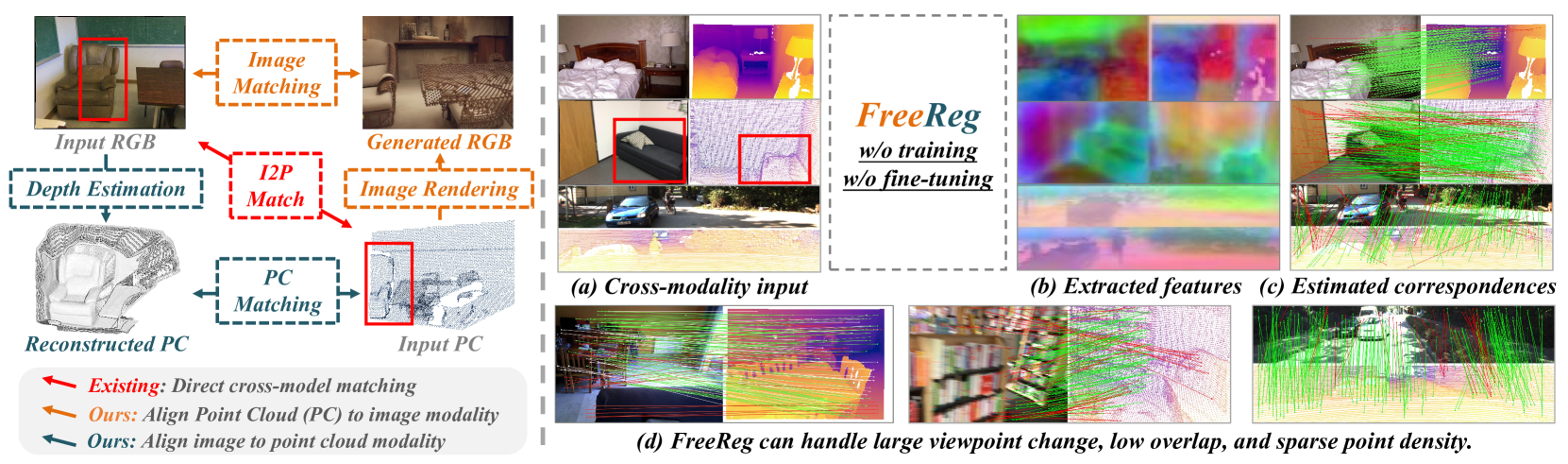
FreeReg: Image-to-Point Cloud Registration Leveraging Pretrained Diffusion Models and Monocular Depth Estimators
Haiping Wang, Yuan Liu, Bing Wang, Yujing Sun, Zhen Dong, Wenping Wang, Bisheng Yang
0
0
Matching cross-modality features between images and point clouds is a fundamental problem for image-to-point cloud registration. However, due to the modality difference between images and points, it is difficult to learn robust and discriminative cross-modality features by existing metric learning methods for feature matching. Instead of applying metric learning on cross-modality data, we propose to unify the modality between images and point clouds by pretrained large-scale models first, and then establish robust correspondence within the same modality. We show that the intermediate features, called diffusion features, extracted by depth-to-image diffusion models are semantically consistent between images and point clouds, which enables the building of coarse but robust cross-modality correspondences. We further extract geometric features on depth maps produced by the monocular depth estimator. By matching such geometric features, we significantly improve the accuracy of the coarse correspondences produced by diffusion features. Extensive experiments demonstrate that without any task-specific training, direct utilization of both features produces accurate image-to-point cloud registration. On three public indoor and outdoor benchmarks, the proposed method averagely achieves a 20.6 percent improvement in Inlier Ratio, a three-fold higher Inlier Number, and a 48.6 percent improvement in Registration Recall than existing state-of-the-arts.
4/16/2024

Label-Efficient 3D Object Detection For Road-Side Units
Minh-Quan Dao, Holger Caesar, Julie Stephany Berrio, Mao Shan, Stewart Worrall, Vincent Fr'emont, Ezio Malis
0
0
Occlusion presents a significant challenge for safety-critical applications such as autonomous driving. Collaborative perception has recently attracted a large research interest thanks to the ability to enhance the perception of autonomous vehicles via deep information fusion with intelligent roadside units (RSU), thus minimizing the impact of occlusion. While significant advancement has been made, the data-hungry nature of these methods creates a major hurdle for their real-world deployment, particularly due to the need for annotated RSU data. Manually annotating the vast amount of RSU data required for training is prohibitively expensive, given the sheer number of intersections and the effort involved in annotating point clouds. We address this challenge by devising a label-efficient object detection method for RSU based on unsupervised object discovery. Our paper introduces two new modules: one for object discovery based on a spatial-temporal aggregation of point clouds, and another for refinement. Furthermore, we demonstrate that fine-tuning on a small portion of annotated data allows our object discovery models to narrow the performance gap with, or even surpass, fully supervised models. Extensive experiments are carried out in simulated and real-world datasets to evaluate our method.
4/10/2024
🛸
Automatic Odometry-Less OpenDRIVE Generation From Sparse Point Clouds
Leon Eisemann, Johannes Maucher
0
0
High-resolution road representations are a key factor for the success of (highly) automated driving functions. These representations, for example, high-definition (HD) maps, contain accurate information on a multitude of factors, among others: road geometry, lane information, and traffic signs. Through the growing complexity and functionality of automated driving functions, also the requirements on testing and evaluation grow continuously. This leads to an increasing interest in virtual test drives for evaluation purposes. As roads play a crucial role in traffic flow, accurate real-world representations are needed, especially when deriving realistic driving behavior data. This paper proposes a novel approach to generate realistic road representations based solely on point cloud information, independent of the LiDAR sensor, mounting position, and without the need for odometry data, multi-sensor fusion, machine learning, or highly-accurate calibration. As the primary use case is simulation, we use the OpenDRIVE format for evaluation.
5/14/2024

SGV3D:Towards Scenario Generalization for Vision-based Roadside 3D Object Detection
Lei Yang, Xinyu Zhang, Jun Li, Li Wang, Chuang Zhang, Li Ju, Zhiwei Li, Yang Shen
0
0
Roadside perception can greatly increase the safety of autonomous vehicles by extending their perception ability beyond the visual range and addressing blind spots. However, current state-of-the-art vision-based roadside detection methods possess high accuracy on labeled scenes but have inferior performance on new scenes. This is because roadside cameras remain stationary after installation and can only collect data from a single scene, resulting in the algorithm overfitting these roadside backgrounds and camera poses. To address this issue, in this paper, we propose an innovative Scenario Generalization Framework for Vision-based Roadside 3D Object Detection, dubbed SGV3D. Specifically, we employ a Background-suppressed Module (BSM) to mitigate background overfitting in vision-centric pipelines by attenuating background features during the 2D to bird's-eye-view projection. Furthermore, by introducing the Semi-supervised Data Generation Pipeline (SSDG) using unlabeled images from new scenes, diverse instance foregrounds with varying camera poses are generated, addressing the risk of overfitting specific camera poses. We evaluate our method on two large-scale roadside benchmarks. Our method surpasses all previous methods by a significant margin in new scenes, including +42.57% for vehicle, +5.87% for pedestrian, and +14.89% for cyclist compared to BEVHeight on the DAIR-V2X-I heterologous benchmark. On the larger-scale Rope3D heterologous benchmark, we achieve notable gains of 14.48% for car and 12.41% for large vehicle. We aspire to contribute insights on the exploration of roadside perception techniques, emphasizing their capability for scenario generalization. The code will be available at https://github.com/yanglei18/SGV3D
4/10/2024