Hyper-Transformer for Amodal Completion

0

Sign in to get full access
Overview
- This paper presents a novel Hyper-Transformer architecture for the task of amodal completion, which aims to predict the full, occluded extent of objects in an image.
- The model combines a Transformer-based backbone with a novel Hyper-Transformer module that allows the network to adaptively reason about the visible and occluded parts of objects.
- The authors demonstrate the effectiveness of their approach on several amodal completion benchmarks, outperforming prior state-of-the-art methods.
Plain English Explanation
The paper introduces a new deep learning model called the Hyper-Transformer, which is designed to tackle the challenge of amodal completion. Amodal completion is the ability to understand and predict the full extent of an object, even if parts of it are hidden or occluded in an image.
The key innovation of the Hyper-Transformer is that it combines a standard Transformer-based neural network backbone with a specialized "Hyper-Transformer" module. This Hyper-Transformer module allows the model to adaptively reason about which parts of an object are visible versus occluded, and use that understanding to more accurately predict the full, amodal shape of the object.
By incorporating this amodal reasoning capability, the Hyper-Transformer is able to outperform previous state-of-the-art models on several benchmark datasets for amodal completion. This is an important advancement, as the ability to understand the full, occluded extent of objects has many practical applications, such as in autonomous driving, robotic manipulation, and image editing.
Technical Explanation
The core of the Hyper-Transformer architecture is a Transformer-based backbone, similar to models like DETR or Swin Transformer. This backbone encodes the input image and generates a set of object-centric feature maps.
The key novelty is the addition of the Hyper-Transformer module, which sits on top of the backbone and adaptively reasons about the visible and occluded parts of each object. This module takes the object-centric features as input and outputs amodal segmentation masks, which represent the full, occluded extents of the objects.
The Hyper-Transformer module achieves this by learning to dynamically adjust the receptive field of its attention mechanisms, allowing it to focus on both the visible and occluded regions of each object. This is in contrast to previous amodal completion methods, which typically relied on hand-crafted priors or separate modules to handle visible and occluded areas.
The authors evaluate the Hyper-Transformer on several amodal completion benchmarks, including COCO-Amodal, KINS, and MSCOCO-Amodal. They show that their model outperforms prior state-of-the-art methods by a significant margin, demonstrating the effectiveness of the Hyper-Transformer's adaptive amodal reasoning capabilities.
Critical Analysis
One potential limitation of the Hyper-Transformer is that it relies on a Transformer-based backbone, which can be computationally expensive and challenging to deploy in real-world scenarios with tight latency requirements, such as autonomous driving or robotic manipulation. The authors do not discuss the computational complexity or inference time of their model, which would be an important consideration for practical applications.
Additionally, the paper does not provide a detailed analysis of the model's performance on different types of occlusions or object categories. It would be valuable to understand how the Hyper-Transformer's amodal reasoning capabilities generalize to various occlusion patterns and object classes, as this could inform future improvements to the architecture.
Conclusion
The Hyper-Transformer presented in this paper represents a significant advancement in amodal completion, a critical task for understanding the full, occluded extent of objects in images. By incorporating a novel Hyper-Transformer module that adaptively reasons about visible and occluded regions, the model is able to outperform previous state-of-the-art methods on several benchmark datasets.
While the computational complexity of the Transformer-based architecture may be a concern for some real-world applications, the core ideas behind the Hyper-Transformer's amodal reasoning capabilities could inspire future research in this important area of computer vision. As the ability to understand occluded objects becomes increasingly important for applications like autonomous driving, robotic manipulation, and image editing, the Hyper-Transformer represents a valuable contribution to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hyper-Transformer for Amodal Completion
Jianxiong Gao, Xuelin Qian, Longfei Liang, Junwei Han, Yanwei Fu
Amodal object completion is a complex task that involves predicting the invisible parts of an object based on visible segments and background information. Learning shape priors is crucial for effective amodal completion, but traditional methods often rely on two-stage processes or additional information, leading to inefficiencies and potential error accumulation. To address these shortcomings, we introduce a novel framework named the Hyper-Transformer Amodal Network (H-TAN). This framework utilizes a hyper transformer equipped with a dynamic convolution head to directly learn shape priors and accurately predict amodal masks. Specifically, H-TAN uses a dual-branch structure to extract multi-scale features from both images and masks. The multi-scale features from the image branch guide the hyper transformer in learning shape priors and in generating the weights for dynamic convolution tailored to each instance. The dynamic convolution head then uses the features from the mask branch to predict precise amodal masks. We extensively evaluate our model on three benchmark datasets: KINS, COCOA-cls, and D2SA, where H-TAN demonstrated superior performance compared to existing methods. Additional experiments validate the effectiveness and stability of the novel hyper transformer in our framework.
Read more5/31/2024

0
Amodal Ground Truth and Completion in the Wild
Guanqi Zhan, Chuanxia Zheng, Weidi Xie, Andrew Zisserman
This paper studies amodal image segmentation: predicting entire object segmentation masks including both visible and invisible (occluded) parts. In previous work, the amodal segmentation ground truth on real images is usually predicted by manual annotaton and thus is subjective. In contrast, we use 3D data to establish an automatic pipeline to determine authentic ground truth amodal masks for partially occluded objects in real images. This pipeline is used to construct an amodal completion evaluation benchmark, MP3D-Amodal, consisting of a variety of object categories and labels. To better handle the amodal completion task in the wild, we explore two architecture variants: a two-stage model that first infers the occluder, followed by amodal mask completion; and a one-stage model that exploits the representation power of Stable Diffusion for amodal segmentation across many categories. Without bells and whistles, our method achieves a new state-of-the-art performance on Amodal segmentation datasets that cover a large variety of objects, including COCOA and our new MP3D-Amodal dataset. The dataset, model, and code are available at https://www.robots.ox.ac.uk/~vgg/research/amodal/.
Read more4/30/2024

0
ShapeFormer: Shape Prior Visible-to-Amodal Transformer-based Amodal Instance Segmentation
Minh Tran, Winston Bounsavy, Khoa Vo, Anh Nguyen, Tri Nguyen, Ngan Le
Amodal Instance Segmentation (AIS) presents a challenging task as it involves predicting both visible and occluded parts of objects within images. Existing AIS methods rely on a bidirectional approach, encompassing both the transition from amodal features to visible features (amodal-to-visible) and from visible features to amodal features (visible-to-amodal). Our observation shows that the utilization of amodal features through the amodal-to-visible can confuse the visible features due to the extra information of occluded/hidden segments not presented in visible display. Consequently, this compromised quality of visible features during the subsequent visible-to-amodal transition. To tackle this issue, we introduce ShapeFormer, a decoupled Transformer-based model with a visible-to-amodal transition. It facilitates the explicit relationship between output segmentations and avoids the need for amodal-to-visible transitions. ShapeFormer comprises three key modules: (i) Visible-Occluding Mask Head for predicting visible segmentation with occlusion awareness, (ii) Shape-Prior Amodal Mask Head for predicting amodal and occluded masks, and (iii) Category-Specific Shape Prior Retriever aims to provide shape prior knowledge. Comprehensive experiments and extensive ablation studies across various AIS benchmarks demonstrate the effectiveness of our ShapeFormer. The code is available at: https://github.com/UARK-AICV/ShapeFormer
Read more4/16/2024
0
PLUG: Revisiting Amodal Segmentation with Foundation Model and Hierarchical Focus
Zhaochen Liu, Limeng Qiao, Xiangxiang Chu, Tingting Jiang
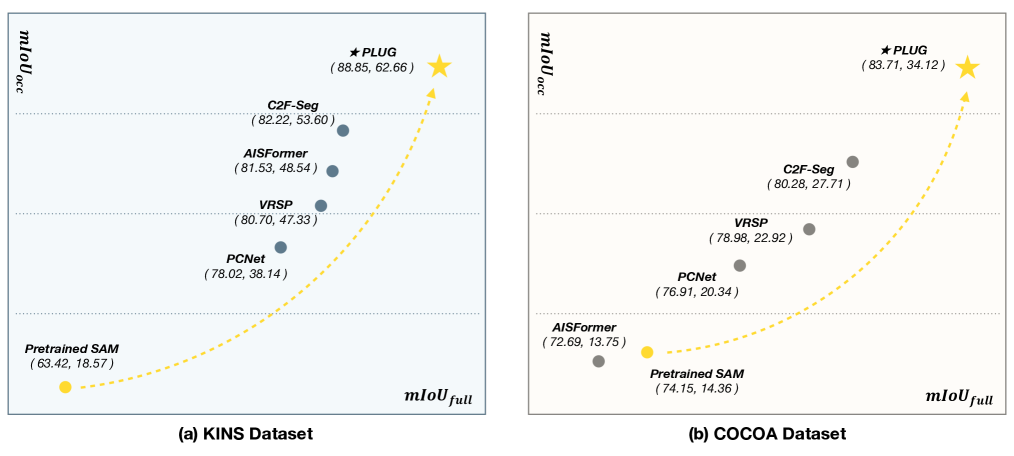
Aiming to predict the complete shapes of partially occluded objects, amodal segmentation is an important step towards visual intelligence. With crucial significance, practical prior knowledge derives from sufficient training, while limited amodal annotations pose challenges to achieve better performance. To tackle this problem, utilizing the mighty priors accumulated in the foundation model, we propose the first SAM-based amodal segmentation approach, PLUG. Methodologically, a novel framework with hierarchical focus is presented to better adapt the task characteristics and unleash the potential capabilities of SAM. In the region level, due to the association and division in visible and occluded areas, inmodal and amodal regions are assigned as the focuses of distinct branches to avoid mutual disturbance. In the point level, we introduce the concept of uncertainty to explicitly assist the model in identifying and focusing on ambiguous points. Guided by the uncertainty map, a computation-economic point loss is applied to improve the accuracy of predicted boundaries. Experiments are conducted on several prominent datasets, and the results show that our proposed method outperforms existing methods with large margins. Even with fewer total parameters, our method still exhibits remarkable advantages.
Read more6/4/2024