Shared Latent Space by Both Languages in Non-Autoregressive Neural Machine Translation

0
🧠
Sign in to get full access
Overview
- Non-autoregressive neural machine translation (NAT) can translate faster than autoregressive translation (AT), but at the cost of quality.
- Latent variable modeling is a promising approach to improve NAT quality by addressing the multimodality problem.
- Previous works added an auxiliary model to estimate the latent variable, which had some disadvantages.
- This paper proposes a novel latent variable modeling approach to address these issues.
Plain English Explanation
In machine translation, the goal is to translate text from one language to another. Traditional approaches use autoregressive models (AT), which translate one word at a time in a sequential manner. This can be slow, especially for real-time applications.
Non-autoregressive translation (NAT) models can translate much faster by predicting all the words at once. However, this leads to a drop in translation quality compared to AT models.
Researchers have explored using latent variable modeling to bridge this quality gap in NAT. The idea is to learn a hidden "latent" representation of the translation, which can capture important information that helps produce higher quality translations.
Previous approaches added a separate model to estimate the latent variable, but this had some downsides. It could lead to redundant information processing, increase the number of parameters, and cause the model to ignore important input information.
This paper proposes a new latent variable modeling approach that integrates the latent representation more directly into the translation process. The key ideas are to:
- Use a "dual reconstruction" perspective, where the model learns the latent representation by reconstructing both the source and target sentences.
- Use a more advanced "hierarchical" latent modeling approach, with a shared latent space across languages.
The authors show that this leads to higher quality latent representations, which in turn improves the overall translation quality of the NAT model compared to prior approaches.
Technical Explanation
The core technical contribution of this paper is a novel latent variable modeling approach for non-autoregressive neural machine translation.
In prior work, latent variable modeling for NAT used an auxiliary model to estimate the posterior distribution of the latent variable, conditioned on the source and target sentences. However, this had several disadvantages:
- Redundant information extraction: The auxiliary model had to extract information already present in the main translation model, leading to redundant processing.
- Increased model complexity: The auxiliary model added more parameters, increasing the overall model complexity.
- Ignoring input information: The auxiliary model's estimates could cause the main model to ignore important information from the input.
To address these issues, the authors propose a new latent variable modeling approach with two key innovations:
- Dual reconstruction perspective: Instead of using an auxiliary model, the proposed approach learns the latent representation by reconstructing
both the source and target sentences. This encourages the latent variable to capture information relevant for translation in a more direct way. - Hierarchical latent modeling: The authors use a more advanced hierarchical latent modeling technique, where the latent space is shared across the source and target languages. This allows the model to better capture the underlying cross-lingual correlations.
In their experiments, the authors show that this proposed latent variable modeling approach leads to superior latent representations, which in turn significantly improves the translation quality of their NAT model compared to previous state-of-the-art NAT baselines.
Critical Analysis
The authors provide a thorough evaluation of their proposed method, including comparisons to various NAT baselines on standard benchmarks like WMT. The results demonstrate clear improvements in translation quality, validating the effectiveness of their latent variable modeling approach.
However, the paper does not extensively discuss potential limitations or areas for further research. For example, it would be interesting to understand how the proposed method performs on more diverse language pairs or low-resource settings. Additionally, the authors could have explored the interpretability of the learned latent representations and their connection to human-interpretable translation concepts.
While the technical details are well-explained, the paper could have provided more high-level intuition and analogies to help a general audience better understand the core ideas. Some additional discussion on the broader implications of improving NAT quality could also be valuable.
Overall, this paper presents a promising step forward in bridging the quality gap between autoregressive and non-autoregressive neural machine translation models. Further research into latent variable modeling and its applications to other sequence-to-sequence tasks could lead to exciting advancements in the field.
Conclusion
This paper introduces a novel latent variable modeling approach for non-autoregressive neural machine translation. By using a dual reconstruction perspective and hierarchical latent modeling, the authors were able to learn superior latent representations that significantly improved the translation quality of their NAT model compared to previous state-of-the-art baselines.
The key insights from this work highlight the importance of carefully designing latent variable modeling techniques to address the unique challenges of NAT, such as the multimodality problem. The authors' approach demonstrates how integrating the latent representation more directly into the translation process can be an effective way to bridge the quality gap between autoregressive and non-autoregressive models.
While the paper could have explored some additional limitations and future research directions, it represents an important contribution to the ongoing efforts to make non-autoregressive machine translation a viable and high-performing alternative to traditional autoregressive approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Shared Latent Space by Both Languages in Non-Autoregressive Neural Machine Translation
DongNyeong Heo, Heeyoul Choi
Non-autoregressive neural machine translation (NAT) offers substantial translation speed up compared to autoregressive neural machine translation (AT) at the cost of translation quality. Latent variable modeling has emerged as a promising approach to bridge this quality gap, particularly for addressing the chronic multimodality problem in NAT. In the previous works that used latent variable modeling, they added an auxiliary model to estimate the posterior distribution of the latent variable conditioned on the source and target sentences. However, it causes several disadvantages, such as redundant information extraction in the latent variable, increasing the number of parameters, and a tendency to ignore some information from the inputs. In this paper, we propose a novel latent variable modeling that integrates a dual reconstruction perspective and an advanced hierarchical latent modeling with a shared intermediate latent space across languages. This latent variable modeling hypothetically alleviates or prevents the above disadvantages. In our experiment results, we present comprehensive demonstrations that our proposed approach infers superior latent variables which lead better translation quality. Finally, in the benchmark translation tasks, such as WMT, we demonstrate that our proposed method significantly improves translation quality compared to previous NAT baselines including the state-of-the-art NAT model.
Read more9/10/2024
🌀
0
What Have We Achieved on Non-autoregressive Translation?
Yafu Li, Huajian Zhang, Jianhao Yan, Yongjing Yin, Yue Zhang
Recent advances have made non-autoregressive (NAT) translation comparable to autoregressive methods (AT). However, their evaluation using BLEU has been shown to weakly correlate with human annotations. Limited research compares non-autoregressive translation and autoregressive translation comprehensively, leaving uncertainty about the true proximity of NAT to AT. To address this gap, we systematically evaluate four representative NAT methods across various dimensions, including human evaluation. Our empirical results demonstrate that despite narrowing the performance gap, state-of-the-art NAT still underperforms AT under more reliable evaluation metrics. Furthermore, we discover that explicitly modeling dependencies is crucial for generating natural language and generalizing to out-of-distribution sequences.
Read more5/22/2024
0
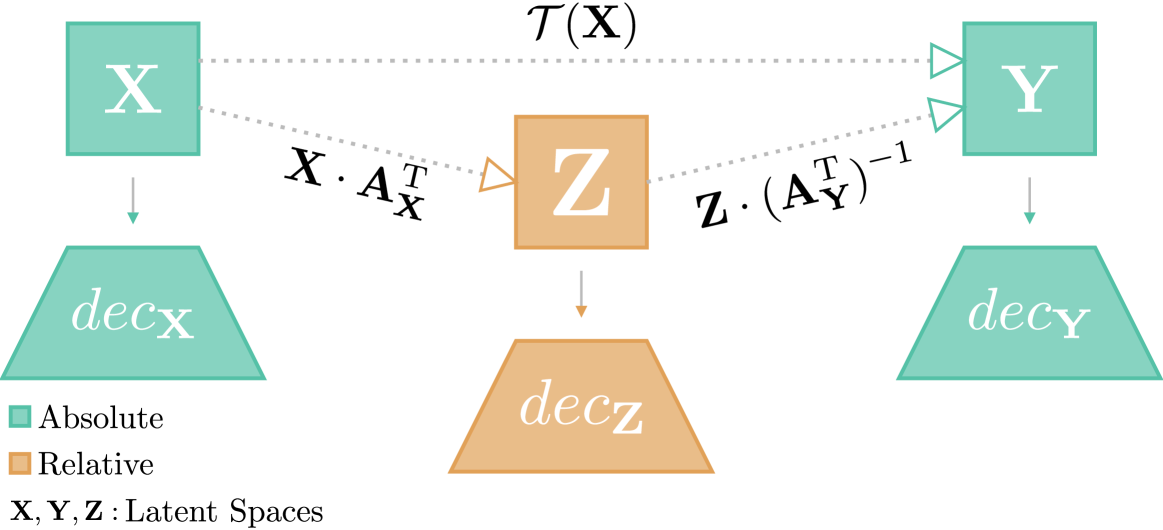
Latent Space Translation via Inverse Relative Projection
Valentino Maiorca, Luca Moschella, Marco Fumero, Francesco Locatello, Emanuele Rodol`a
The emergence of similar representations between independently trained neural models has sparked significant interest in the representation learning community, leading to the development of various methods to obtain communication between latent spaces. Latent space communication can be achieved in two ways: i) by independently mapping the original spaces to a shared or relative one; ii) by directly estimating a transformation from a source latent space to a target one. In this work, we combine the two into a novel method to obtain latent space translation through the relative space. By formalizing the invertibility of angle-preserving relative representations and assuming the scale invariance of decoder modules in neural models, we can effectively use the relative space as an intermediary, independently projecting onto and from other semantically similar spaces. Extensive experiments over various architectures and datasets validate our scale invariance assumption and demonstrate the high accuracy of our method in latent space translation. We also apply our method to zero-shot stitching between arbitrary pre-trained text and image encoders and their classifiers, even across modalities. Our method has significant potential for facilitating the reuse of models in a practical manner via compositionality.
Read more6/24/2024

0
A Non-autoregressive Generation Framework for End-to-End Simultaneous Speech-to-Any Translation
Zhengrui Ma, Qingkai Fang, Shaolei Zhang, Shoutao Guo, Yang Feng, Min Zhang
Simultaneous translation models play a crucial role in facilitating communication. However, existing research primarily focuses on text-to-text or speech-to-text models, necessitating additional cascade components to achieve speech-to-speech translation. These pipeline methods suffer from error propagation and accumulate delays in each cascade component, resulting in reduced synchronization between the speaker and listener. To overcome these challenges, we propose a novel non-autoregressive generation framework for simultaneous speech translation (NAST-S2X), which integrates speech-to-text and speech-to-speech tasks into a unified end-to-end framework. We develop a non-autoregressive decoder capable of concurrently generating multiple text or acoustic unit tokens upon receiving fixed-length speech chunks. The decoder can generate blank or repeated tokens and employ CTC decoding to dynamically adjust its latency. Experimental results show that NAST-S2X outperforms state-of-the-art models in both speech-to-text and speech-to-speech tasks. It achieves high-quality simultaneous interpretation within a delay of less than 3 seconds and provides a 28 times decoding speedup in offline generation.
Read more6/12/2024