ShareGPT4Video: Improving Video Understanding and Generation with Better Captions
2406.04325
0
0

Abstract
We present the ShareGPT4Video series, aiming to facilitate the video understanding of large video-language models (LVLMs) and the video generation of text-to-video models (T2VMs) via dense and precise captions. The series comprises: 1) ShareGPT4Video, 40K GPT4V annotated dense captions of videos with various lengths and sources, developed through carefully designed data filtering and annotating strategy. 2) ShareCaptioner-Video, an efficient and capable captioning model for arbitrary videos, with 4.8M high-quality aesthetic videos annotated by it. 3) ShareGPT4Video-8B, a simple yet superb LVLM that reached SOTA performance on three advancing video benchmarks. To achieve this, taking aside the non-scalable costly human annotators, we find using GPT4V to caption video with a naive multi-frame or frame-concatenation input strategy leads to less detailed and sometimes temporal-confused results. We argue the challenge of designing a high-quality video captioning strategy lies in three aspects: 1) Inter-frame precise temporal change understanding. 2) Intra-frame detailed content description. 3) Frame-number scalability for arbitrary-length videos. To this end, we meticulously designed a differential video captioning strategy, which is stable, scalable, and efficient for generating captions for videos with arbitrary resolution, aspect ratios, and length. Based on it, we construct ShareGPT4Video, which contains 40K high-quality videos spanning a wide range of categories, and the resulting captions encompass rich world knowledge, object attributes, camera movements, and crucially, detailed and precise temporal descriptions of events. Based on ShareGPT4Video, we further develop ShareCaptioner-Video, a superior captioner capable of efficiently generating high-quality captions for arbitrary videos...
Create account to get full access
Overview
• This paper introduces ShareGPT4Video, a dataset and models that aim to improve video understanding and generation by leveraging better video captions.
• The key ideas are to use a large-scale dataset of video-caption pairs and multi-task training to build models that can both understand video content and generate informative captions.
Plain English Explanation
• ShareGPT4Video is a new dataset and set of AI models that are designed to help computers better understand and describe video content.
• The researchers collected a large dataset of video clips paired with high-quality captions that describe what's happening in the video. This provides rich training data for AI models.
• The models are trained to do two things: (1) analyze video content and understand what's happening, and (2) generate informative captions to describe the video.
• By combining these two capabilities, the models can both comprehend videos and produce detailed, human-like descriptions of the video content.
• This could be useful for applications like video search, summarization, and captioning, as well as generating creative video content.
Technical Explanation
• The ShareGPT4Video dataset consists of over 1 million video-caption pairs, drawn from a variety of online sources. The captions are high-quality, providing detailed descriptions of the video content.
• The researchers train multi-task models that are jointly optimized for both video understanding and caption generation. This allows the models to learn rich representations that capture the connections between visual and textual information.
• The video understanding component uses a transformer-based architecture to encode video frames and output representations of the video content. The caption generation component uses a language model to generate fluent, informative captions.
• Experiments show that the ShareGPT4Video models outperform previous state-of-the-art approaches on a range of video understanding and generation benchmarks, demonstrating the value of the dataset and multi-task training approach.
Critical Analysis
• While the ShareGPT4Video dataset and models represent an impressive advancement in video-language understanding, the paper does not thoroughly discuss potential limitations or biases in the dataset or models.
• For example, the dataset may over-represent certain types of videos or lack diversity in terms of geographic, demographic, or cultural representation. This could lead to biases in the model's understanding and generation capabilities.
• Additionally, the multi-task training approach, while effective, may not fully capture the nuances and complexities of real-world video understanding and generation. Further research into more sophisticated architectures and training procedures may be warranted.
• Overall, the ShareGPT4Video work is a significant contribution to the field, but continued scrutiny and refinement will be important to ensure the models are robust, fair, and widely applicable.
Conclusion
• The ShareGPT4Video dataset and models represent an important step forward in improving video understanding and generation capabilities through the use of high-quality video captions and multi-task learning.
• The models' ability to both comprehend video content and produce informative descriptions could have wide-ranging applications, from video search and summarization to creative video generation.
• While the work shows promise, further research is needed to address potential biases and limitations, and to continue advancing the state of the art in this rapidly evolving field of multimodal AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Retrieval Enhanced Zero-Shot Video Captioning
Yunchuan Ma, Laiyun Qing, Guorong Li, Yuankai Qi, Quan Z. Sheng, Qingming Huang
0
0
Despite the significant progress of fully-supervised video captioning, zero-shot methods remain much less explored. In this paper, we propose to take advantage of existing pre-trained large-scale vision and language models to directly generate captions with test time adaptation. Specifically, we bridge video and text using three key models: a general video understanding model XCLIP, a general image understanding model CLIP, and a text generation model GPT-2, due to their source-code availability. The main challenge is how to enable the text generation model to be sufficiently aware of the content in a given video so as to generate corresponding captions. To address this problem, we propose using learnable tokens as a communication medium between frozen GPT-2 and frozen XCLIP as well as frozen CLIP. Differing from the conventional way to train these tokens with training data, we update these tokens with pseudo-targets of the inference data under several carefully crafted loss functions which enable the tokens to absorb video information catered for GPT-2. This procedure can be done in just a few iterations (we use 16 iterations in the experiments) and does not require ground truth data. Extensive experimental results on three widely used datasets, MSR-VTT, MSVD, and VATEX, show 4% to 20% improvements in terms of the main metric CIDEr compared to the existing state-of-the-art methods.
5/14/2024
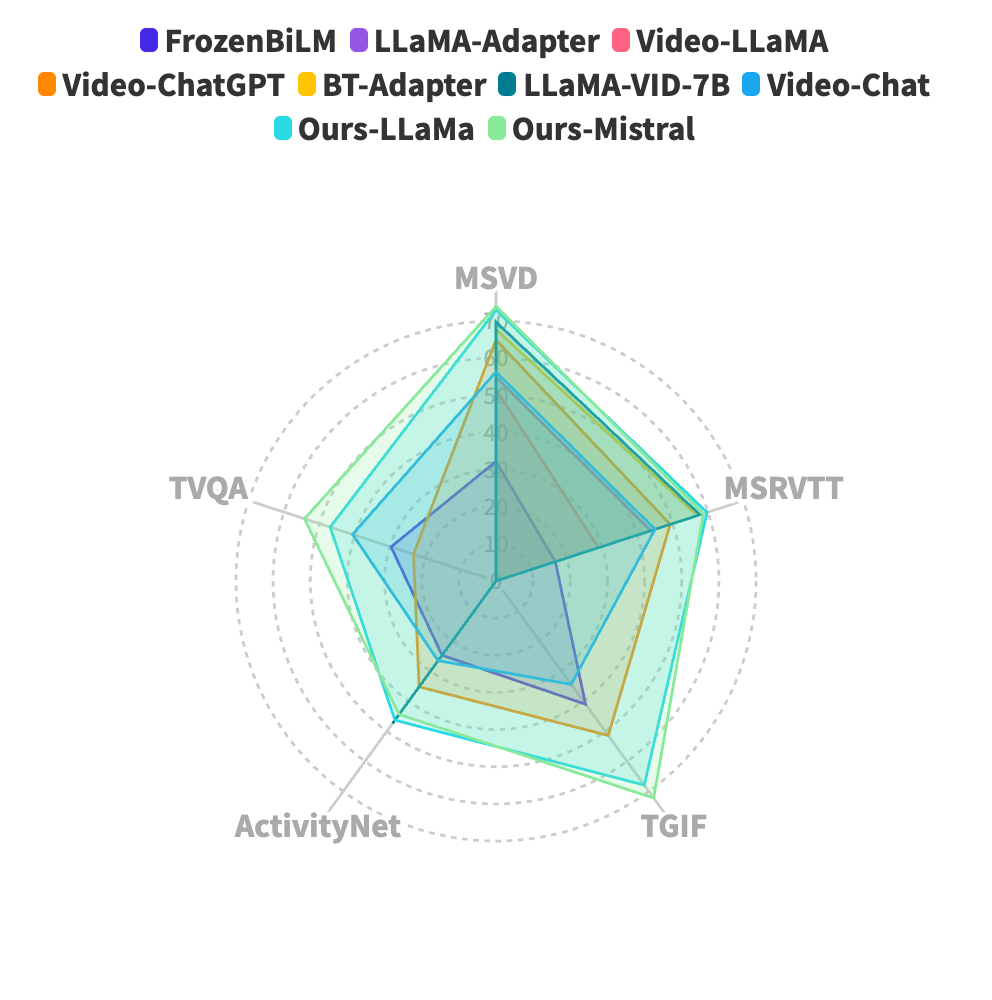
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
Kirolos Ataallah, Xiaoqian Shen, Eslam Abdelrahman, Essam Sleiman, Deyao Zhu, Jian Ding, Mohamed Elhoseiny
0
0
This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
4/5/2024
🤔
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, Fahad Shahbaz Khan
0
0
Conversation agents fueled by Large Language Models (LLMs) are providing a new way to interact with visual data. While there have been initial attempts for image-based conversation models, this work addresses the under-explored field of emph{video-based conversation} by introducing Video-ChatGPT. It is a multimodal model that merges a video-adapted visual encoder with an LLM. The resulting model is capable of understanding and generating detailed conversations about videos. We introduce a new dataset of 100,000 video-instruction pairs used to train Video-ChatGPT acquired via manual and semi-automated pipeline that is easily scalable and robust to label noise. We also develop a quantitative evaluation framework for video-based dialogue models to objectively analyze the strengths and weaknesses of video-based dialogue models. Code: https://github.com/mbzuai-oryx/Video-ChatGPT.
6/11/2024
VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding
Muhammad Maaz, Hanoona Rasheed, Salman Khan, Fahad Khan
0
0
Building on the advances of language models, Large Multimodal Models (LMMs) have contributed significant improvements in video understanding. While the current video LMMs utilize advanced Large Language Models (LLMs), they rely on either image or video encoders to process visual inputs, each of which has its own limitations. Image encoders excel at capturing rich spatial details from frame sequences but lack explicit temporal context, which can be important in videos with intricate action sequences. On the other hand, video encoders provide temporal context but are often limited by computational constraints that lead to processing only sparse frames at lower resolutions, resulting in reduced contextual and spatial understanding. To this end, we introduce VideoGPT+, which combines the complementary benefits of the image encoder (for detailed spatial understanding) and the video encoder (for global temporal context modeling). The model processes videos by dividing them into smaller segments and applies an adaptive pooling strategy on features extracted by both image and video encoders. Our architecture showcases improved performance across multiple video benchmarks, including VCGBench, MVBench and Zero-shot question-answering. Further, we develop 112K video-instruction set using a novel semi-automatic annotation pipeline which further improves the model performance. Additionally, to comprehensively evaluate video LMMs, we present VCGBench-Diverse, covering 18 broad video categories such as lifestyle, sports, science, gaming, and surveillance videos. This benchmark with 4,354 question-answer pairs evaluates the generalization of existing LMMs on dense video captioning, spatial and temporal understanding, and complex reasoning, ensuring comprehensive assessment across diverse video types and dynamics. Code: https://github.com/mbzuai-oryx/VideoGPT-plus.
6/14/2024