Misspecification uncertainties in near-deterministic regression
2402.01810
0
0
Abstract
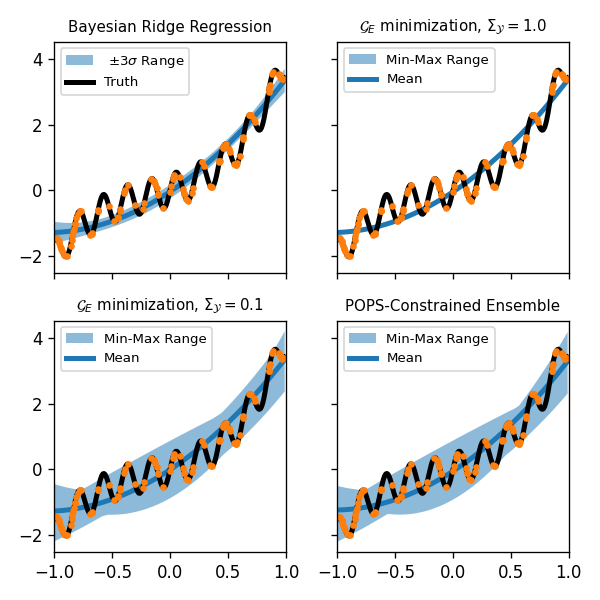
Bayesian regression determines model parameters by minimizing the expected loss, an upper bound to the true generalization error. However, the loss ignores misspecification, where models are imperfect. Parameter uncertainties from Bayesian regression are thus significantly underestimated and vanish in the large data limit. This is particularly problematic when building models of low- noise, or near-deterministic, calculations, as the main source of uncertainty is neglected. We analyze the generalization error of misspecified, near-deterministic surrogate models, a regime of broad relevance in science and engineering. We show posterior distributions must cover every training point to avoid a divergent generalization error and design an ansatz that respects this constraint, which for linear models incurs minimal overhead. This is demonstrated on model problems before application to thousand dimensional datasets in atomistic machine learning. Our efficient misspecification-aware scheme gives accurate prediction and bounding of test errors where existing schemes fail, allowing this important source of uncertainty to be incorporated in computational workflows.
Create account to get full access
Overview
- This paper discusses the challenges of handling uncertainty in near-deterministic regression models, where the underlying systems have very little inherent randomness.
- The authors propose a Bayesian surrogate modeling approach to quantify the impact of model misspecification on predictive uncertainty.
- The research aims to improve the reliability and robustness of regression-based predictions in domains with near-deterministic behavior, such as scientific simulations and engineering systems.
Plain English Explanation
In many real-world applications, such as scientific simulations or engineering models, the underlying systems being studied tend to be highly predictable, with very little inherent randomness or uncertainty. However, the models used to represent these systems may not be perfect and can have their own sources of uncertainty, known as "model misspecification."
The key problem addressed in this paper is how to properly quantify and account for this model misspecification uncertainty when making predictions. Typical regression approaches may underestimate the true predictive uncertainty in near-deterministic settings, leading to overconfident and potentially unreliable results.
The researchers propose using a Bayesian surrogate modeling approach to tackle this challenge. By building a probabilistic model that captures both the deterministic system behavior and the uncertainties introduced by the regression model, they aim to provide more accurate and reliable predictions, along with a better understanding of the sources of uncertainty.
This work has important implications for fields that rely heavily on regression-based models, such as scientific simulations, engineering design, and machine learning. By addressing the issue of model misspecification, the proposed approach can help improve the trustworthiness and interpretability of these critical predictive models.
Technical Explanation
The paper begins by highlighting the challenges of dealing with near-deterministic regression problems, where the underlying systems exhibit very little inherent randomness or uncertainty. In such cases, traditional regression approaches may fail to adequately capture the impact of model misspecification, leading to overconfident and potentially unreliable predictions.
To address this issue, the authors propose a Bayesian surrogate modeling framework that explicitly models the deterministic system behavior and the uncertainties introduced by the regression model. The key idea is to treat the deterministic system as a "black box" and use a Gaussian process (GP) model to learn a probabilistic representation of its input-output relationship.
The GP model is then used to quantify the impact of model misspecification on the predictive uncertainty. By propagating the GP-based uncertainty through the deterministic system, the approach provides a more realistic assessment of the overall predictive uncertainty, accounting for both the inherent system behavior and the limitations of the regression model.
The paper demonstrates the effectiveness of the proposed Bayesian surrogate modeling approach through several numerical examples, comparing its performance to traditional regression methods. The results show that the Bayesian approach can better capture the true predictive uncertainty, leading to more reliable and robust predictions in near-deterministic settings.
Critical Analysis
The paper presents a well-designed and thorough investigation of the problem of model misspecification uncertainty in near-deterministic regression problems. The proposed Bayesian surrogate modeling approach is a promising solution that seems to address the key limitations of existing methods.
One potential area for further research could be the exploration of alternative probabilistic modeling techniques, beyond the Gaussian process used in this work. For example, Bayesian neural networks or imprecise probabilistic models may offer additional flexibility and modeling capabilities that could further improve the quantification of misspecification uncertainties.
Additionally, the authors mention the potential computational challenges associated with the Bayesian surrogate modeling approach, particularly for high-dimensional input spaces. Investigating ways to improve the scalability and efficiency of the method, such as through approximate inference techniques or model compression strategies, could enhance its practical applicability.
Overall, this paper makes a valuable contribution to the field of regression-based predictive modeling, addressing an important and understudied challenge in near-deterministic settings. The proposed Bayesian surrogate modeling approach represents a significant step forward in improving the reliability and robustness of such models, with potential applications across a wide range of scientific and engineering domains.
Conclusion
This paper tackles the critical issue of handling model misspecification uncertainty in near-deterministic regression problems, where the underlying systems exhibit very little inherent randomness. By proposing a Bayesian surrogate modeling approach, the authors introduce a more comprehensive and reliable way to quantify the impact of model limitations on predictive uncertainty.
The key innovation of this work is the explicit incorporation of the deterministic system behavior and the model misspecification uncertainties into a unified probabilistic framework. This allows for a more accurate assessment of the overall predictive uncertainty, leading to more trustworthy and interpretable regression-based models.
The potential applications of this research span a wide range of domains, from scientific simulations and engineering design to machine learning and decision-making. By addressing the challenges of model misspecification, this work represents an important step forward in enhancing the reliability and robustness of critical predictive models, with significant implications for both scientific progress and real-world decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
Universal Batch Learning Under The Misspecification Setting
Shlomi Vituri, Meir Feder
0
0
In this paper we consider the problem of universal {em batch} learning in a misspecification setting with log-loss. In this setting the hypothesis class is a set of models $Theta$. However, the data is generated by an unknown distribution that may not belong to this set but comes from a larger set of models $Phi supset Theta$. Given a training sample, a universal learner is requested to predict a probability distribution for the next outcome and a log-loss is incurred. The universal learner performance is measured by the regret relative to the best hypothesis matching the data, chosen from $Theta$. Utilizing the minimax theorem and information theoretical tools, we derive the optimal universal learner, a mixture over the set of the data generating distributions, and get a closed form expression for the min-max regret. We show that this regret can be considered as a constrained version of the conditional capacity between the data and its generating distributions set. We present tight bounds for this min-max regret, implying that the complexity of the problem is dominated by the richness of the hypotheses models $Theta$ and not by the data generating distributions set $Phi$. We develop an extension to the Arimoto-Blahut algorithm for numerical evaluation of the regret and its capacity achieving prior distribution. We demonstrate our results for the case where the observations come from a $K$-parameters multinomial distributions while the hypothesis class $Theta$ is only a subset of this family of distributions.
6/26/2024
📉
Negative impact of heavy-tailed uncertainty and error distributions on the reliability of calibration statistics for machine learning regression tasks
Pascal Pernot
0
0
Average calibration of the (variance-based) prediction uncertainties of machine learning regression tasks can be tested in two ways: one is to estimate the calibration error (CE) as the difference between the mean absolute error (MSE) and the mean variance (MV); the alternative is to compare the mean squared z-scores (ZMS) to 1. The problem is that both approaches might lead to different conclusions, as illustrated in this study for an ensemble of datasets from the recent machine learning uncertainty quantification (ML-UQ) literature. It is shown that the estimation of MV, MSE and their confidence intervals becomes unreliable for heavy-tailed uncertainty and error distributions, which seems to be a frequent feature of ML-UQ datasets. By contrast, the ZMS statistic is less sensitive and offers the most reliable approach in this context. Unfortunately, the same problem is expected to affect also conditional calibrations statistics, such as the popular ENCE, and very likely post-hoc calibration methods based on similar statistics. Several solutions to circumvent the outlined problems are proposed.
6/6/2024
Error Bounds of Supervised Classification from Information-Theoretic Perspective
Binchuan Qi, Wei Gong, Li Li
0
0
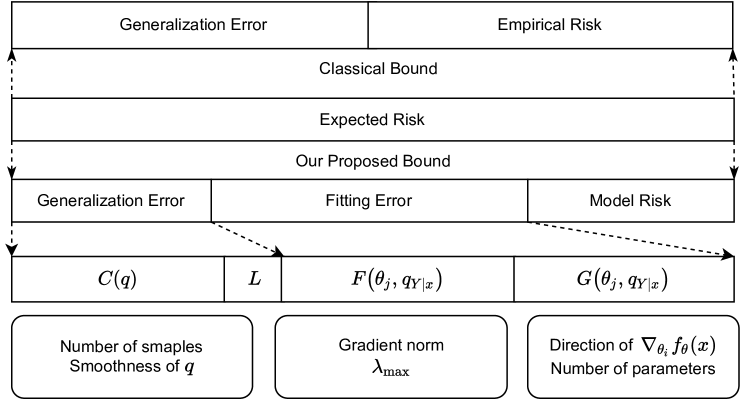
There remains a list of unanswered research questions on deep learning (DL), including the remarkable generalization power of overparametrized neural networks, the efficient optimization performance despite the non-convexity, and the mechanisms behind flat minima in generalization. In this paper, we adopt an information-theoretic perspective to explore the theoretical foundations of supervised classification using deep neural networks (DNNs). Our analysis introduces the concepts of fitting error and model risk, which, together with generalization error, constitute an upper bound on the expected risk. We demonstrate that the generalization errors are bounded by the complexity, influenced by both the smoothness of distribution and the sample size. Consequently, task complexity serves as a reliable indicator of the dataset's quality, guiding the setting of regularization hyperparameters. Furthermore, the derived upper bound fitting error links the back-propagated gradient, Neural Tangent Kernel (NTK), and the model's parameter count with the fitting error. Utilizing the triangle inequality, we establish an upper bound on the expected risk. This bound offers valuable insights into the effects of overparameterization, non-convex optimization, and the flat minima in DNNs.Finally, empirical verification confirms a significant positive correlation between the derived theoretical bounds and the practical expected risk, confirming the practical relevance of the theoretical findings.
6/28/2024
Bayesian Inference for Consistent Predictions in Overparameterized Nonlinear Regression
Tomoya Wakayama
0
0
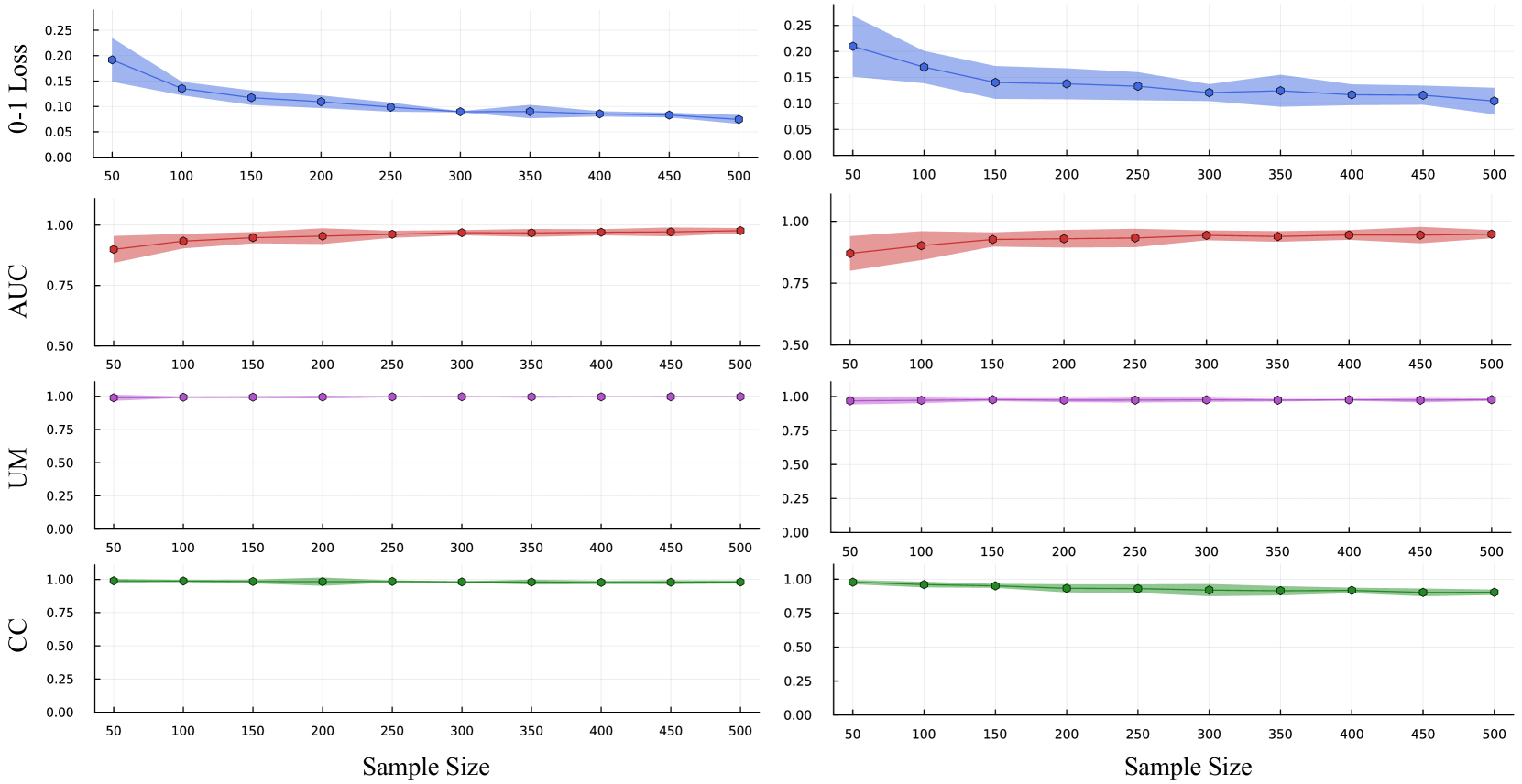
The remarkable generalization performance of large-scale models has been challenging the conventional wisdom of the statistical learning theory. Although recent theoretical studies have shed light on this behavior in linear models and nonlinear classifiers, a comprehensive understanding of overparameterization in nonlinear regression models is still lacking. This study explores the predictive properties of overparameterized nonlinear regression within the Bayesian framework, extending the methodology of the adaptive prior considering the intrinsic spectral structure of the data. Posterior contraction is established for generalized linear and single-neuron models with Lipschitz continuous activation functions, demonstrating the consistency in the predictions of the proposed approach. Moreover, the Bayesian framework enables uncertainty estimation of the predictions. The proposed method was validated via numerical simulations and a real data application, showing its ability to achieve accurate predictions and reliable uncertainty estimates. This work provides a theoretical understanding of the advantages of overparameterization and a principled Bayesian approach to large nonlinear models.
6/18/2024