SheetAgent: Towards A Generalist Agent for Spreadsheet Reasoning and Manipulation via Large Language Models

0
💬
Sign in to get full access
Overview
- Spreadsheet manipulation is a common task that improves work efficiency.
- Large language models (LLMs) have been used for automatic spreadsheet manipulation, but they struggle with complicated, real-world tasks requiring reasoning.
- To address this, the researchers introduce SheetRM, a benchmark for long-horizon, multi-step spreadsheet manipulation tasks with ambiguous requirements.
- They also propose SheetAgent, an autonomous agent that uses LLMs to tackle these challenges through iterative task reasoning and reflection.
Plain English Explanation
Spreadsheets are widely used in various daily tasks and help improve work efficiency. Recently, researchers have tried using large language models to automate spreadsheet manipulation, but these models have struggled with complicated, real-world tasks that require complex reasoning.
To address this, the researchers created a new benchmark called SheetRM that features long-term, multi-step spreadsheet manipulation tasks with ambiguous requirements, similar to what people might encounter in their jobs. These tasks are designed to be more challenging and realistic than previous benchmarks.
To tackle the SheetRM benchmark, the researchers developed a new system called SheetAgent. SheetAgent uses large language models, but it has three specialized modules that work together to plan, gather information, and retrieve relevant knowledge to solve the spreadsheet tasks. By iteratively reasoning about the task and reflecting on its progress, SheetAgent can manipulate spreadsheets accurately and demonstrate strong reasoning abilities, outperforming other approaches.
Technical Explanation
The researchers introduce SheetRM, a benchmark designed to evaluate an agent's ability to perform long-horizon, multi-step spreadsheet manipulation tasks with ambiguous requirements. SheetRM includes a diverse set of tasks that reflect real-world challenges, such as uncertainty about the task's goal, the need for multi-step reasoning, and the use of external information to complete the task.
To address the challenges posed by SheetRM, the researchers propose SheetAgent, a novel autonomous agent that utilizes the power of large language models. SheetAgent consists of three collaborative modules:
- Planner: Responsible for breaking down the task, planning the steps required to solve it, and coordinating the overall problem-solving process.
- Informer: Gathers relevant information from the spreadsheet and external sources to support the task-solving process.
- Retriever: Retrieves and leverages relevant knowledge and skills to execute the planned actions accurately.
These modules work together iteratively, with the Planner guiding the process, the Informer gathering necessary information, and the Retriever executing the actions. This collaborative approach allows SheetAgent to reason about the task, reflect on its progress, and manipulate the spreadsheet effectively, even in the face of ambiguous requirements.
The researchers conducted extensive experiments on the SheetRM benchmark and found that SheetAgent outperformed baseline approaches by a significant margin, achieving a 20-30% improvement in pass rates on multiple tasks. This demonstrates SheetAgent's enhanced precision in spreadsheet manipulation and its superior table reasoning abilities compared to other systems.
Critical Analysis
The researchers have made a commendable effort in addressing the limitations of existing approaches to spreadsheet manipulation by large language models. The SheetRM benchmark introduces a more realistic and challenging set of tasks, which is a valuable contribution to the field.
One potential area for further research is the scalability and generalization of SheetAgent. The current evaluation is focused on the benchmark tasks, and it would be interesting to see how well the system performs on a wider range of real-world spreadsheet manipulation scenarios, including tasks with even more ambiguity, longer time horizons, and more complex data structures.
Additionally, the researchers could explore ways to make the system more transparent and interpretable, allowing users to understand the reasoning behind the agent's actions. This could be particularly useful in scenarios where the task requirements are not entirely clear, and the agent's decision-making process needs to be scrutinized.
Finally, the researchers could investigate the potential for SheetAgent to be integrated with other AI-powered tools, such as automated data science systems or flexible mobile interaction agents, to create a more comprehensive suite of intelligent tools for office productivity and decision-making.
Conclusion
The introduction of SheetRM and SheetAgent represents a significant step forward in addressing the challenges of spreadsheet manipulation using large language models. By focusing on long-horizon, multi-step tasks with ambiguous requirements, the researchers have pushed the boundaries of what is possible with AI-powered spreadsheet automation.
SheetAgent's ability to reason about the task, gather relevant information, and execute accurate manipulations demonstrates the potential of collaborative, LLM-based systems to handle complex, real-world challenges. As the field of AI-powered productivity tools continues to evolve, the insights and techniques developed in this research could have broader implications for enhancing human-computer collaboration and improving work efficiency across various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
SheetAgent: Towards A Generalist Agent for Spreadsheet Reasoning and Manipulation via Large Language Models
Yibin Chen, Yifu Yuan, Zeyu Zhang, Yan Zheng, Jinyi Liu, Fei Ni, Jianye Hao
Spreadsheet manipulation is widely existing in most daily works and significantly improves working efficiency. Large language model (LLM) has been recently attempted for automatic spreadsheet manipulation but has not yet been investigated in complicated and realistic tasks where reasoning challenges exist (e.g., long horizon manipulation with multi-step reasoning and ambiguous requirements). To bridge the gap with the real-world requirements, we introduce $textbf{SheetRM}$, a benchmark featuring long-horizon and multi-category tasks with reasoning-dependent manipulation caused by real-life challenges. To mitigate the above challenges, we further propose $textbf{SheetAgent}$, a novel autonomous agent that utilizes the power of LLMs. SheetAgent consists of three collaborative modules: $textit{Planner}$, $textit{Informer}$, and $textit{Retriever}$, achieving both advanced reasoning and accurate manipulation over spreadsheets without human interaction through iterative task reasoning and reflection. Extensive experiments demonstrate that SheetAgent delivers 20-30% pass rate improvements on multiple benchmarks over baselines, achieving enhanced precision in spreadsheet manipulation and demonstrating superior table reasoning abilities. More details and visualizations are available at https://sheetagent.github.io.
Read more8/27/2024
🤔
0
SpreadsheetBench: Towards Challenging Real World Spreadsheet Manipulation
Zeyao Ma, Bohan Zhang, Jing Zhang, Jifan Yu, Xiaokang Zhang, Xiaohan Zhang, Sijia Luo, Xi Wang, Jie Tang
We introduce SpreadsheetBench, a challenging spreadsheet manipulation benchmark exclusively derived from real-world scenarios, designed to immerse current large language models (LLMs) in the actual workflow of spreadsheet users. Unlike existing benchmarks that rely on synthesized queries and simplified spreadsheet files, SpreadsheetBench is built from 912 real questions gathered from online Excel forums, which reflect the intricate needs of users. The associated spreadsheets from the forums contain a variety of tabular data such as multiple tables, non-standard relational tables, and abundant non-textual elements. Furthermore, we propose a more reliable evaluation metric akin to online judge platforms, where multiple spreadsheet files are created as test cases for each instruction, ensuring the evaluation of robust solutions capable of handling spreadsheets with varying values. Our comprehensive evaluation of various LLMs under both single-round and multi-round inference settings reveals a substantial gap between the state-of-the-art (SOTA) models and human performance, highlighting the benchmark's difficulty.
Read more6/24/2024

138
SpreadsheetLLM: Encoding Spreadsheets for Large Language Models
Yuzhang Tian, Jianbo Zhao, Haoyu Dong, Junyu Xiong, Shiyu Xia, Mengyu Zhou, Yun Lin, Jos'e Cambronero, Yeye He, Shi Han, Dongmei Zhang
Spreadsheets, with their extensive two-dimensional grids, various layouts, and diverse formatting options, present notable challenges for large language models (LLMs). In response, we introduce SpreadsheetLLM, pioneering an efficient encoding method designed to unleash and optimize LLMs' powerful understanding and reasoning capability on spreadsheets. Initially, we propose a vanilla serialization approach that incorporates cell addresses, values, and formats. However, this approach was limited by LLMs' token constraints, making it impractical for most applications. To tackle this challenge, we develop SheetCompressor, an innovative encoding framework that compresses spreadsheets effectively for LLMs. It comprises three modules: structural-anchor-based compression, inverse index translation, and data-format-aware aggregation. It significantly improves performance in spreadsheet table detection task, outperforming the vanilla approach by 25.6% in GPT4's in-context learning setting. Moreover, fine-tuned LLM with SheetCompressor has an average compression ratio of 25 times, but achieves a state-of-the-art 78.9% F1 score, surpassing the best existing models by 12.3%. Finally, we propose Chain of Spreadsheet for downstream tasks of spreadsheet understanding and validate in a new and demanding spreadsheet QA task. We methodically leverage the inherent layout and structure of spreadsheets, demonstrating that SpreadsheetLLM is highly effective across a variety of spreadsheet tasks.
Read more7/15/2024
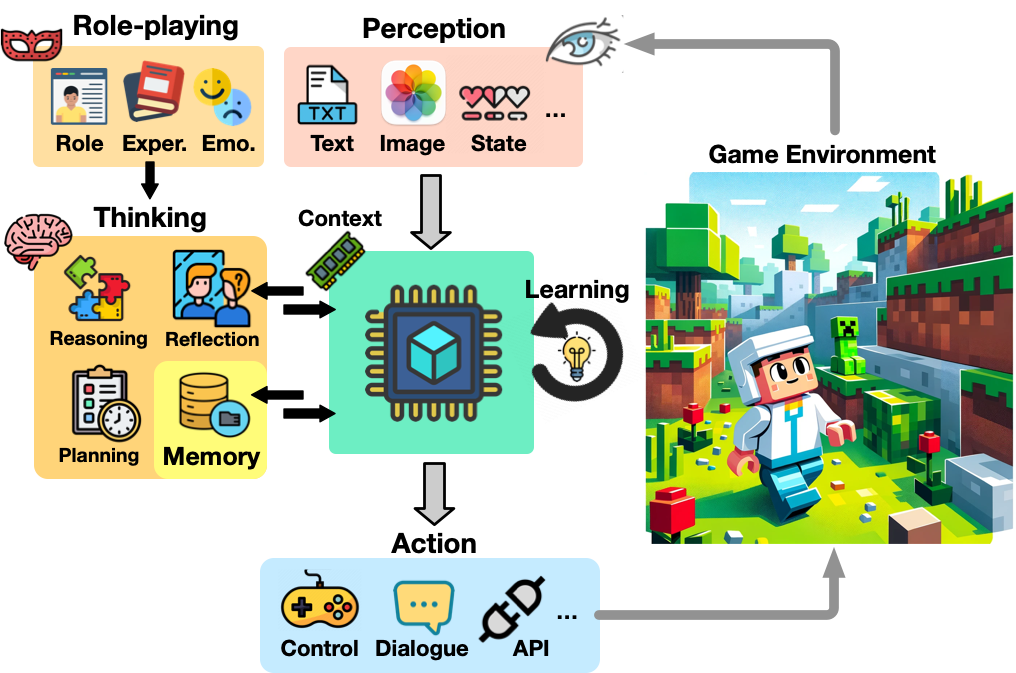
0
A Survey on Large Language Model-Based Game Agents
Sihao Hu, Tiansheng Huang, Fatih Ilhan, Selim Tekin, Gaowen Liu, Ramana Kompella, Ling Liu
The development of game agents holds a critical role in advancing towards Artificial General Intelligence (AGI). The progress of LLMs and their multimodal counterparts (MLLMs) offers an unprecedented opportunity to evolve and empower game agents with human-like decision-making capabilities in complex computer game environments. This paper provides a comprehensive overview of LLM-based game agents from a holistic viewpoint. First, we introduce the conceptual architecture of LLM-based game agents, centered around six essential functional components: perception, memory, thinking, role-playing, action, and learning. Second, we survey existing representative LLM-based game agents documented in the literature with respect to methodologies and adaptation agility across six genres of games, including adventure, communication, competition, cooperation, simulation, and crafting & exploration games. Finally, we present an outlook of future research and development directions in this burgeoning field. A curated list of relevant papers is maintained and made accessible at: https://github.com/git-disl/awesome-LLM-game-agent-papers.
Read more4/3/2024