SignCLIP: Connecting Text and Sign Language by Contrastive Learning

0

Sign in to get full access
Overview
• This paper introduces SignCLIP, a novel approach to connect text and sign language using contrastive learning.
• SignCLIP aims to learn a shared representation between text and sign language, allowing for cross-modal applications like sign language translation and retrieval.
• The model is trained on a large-scale sign language dataset using a contrastive objective, which encourages the text and sign language embeddings to be close for matching pairs and far apart for non-matching pairs.
Plain English Explanation
SignCLIP is a new way to connect text and sign language using a machine learning technique called contrastive learning. The goal is to create a shared representation, or understanding, between text and sign language so that they can be used interchangeably.
For example, with SignCLIP you could take a sentence in English text and automatically translate it into sign language, or search for sign language videos based on text queries. This could be very helpful for people who use sign language, making it easier for them to access information and communicate.
The key idea behind SignCLIP is to train the model on a large dataset of text and sign language examples. The model learns to map both text and sign language into a common space, where matching pairs (e.g. an English sentence and its sign language translation) are pushed together, and non-matching pairs are pushed apart. This allows the model to learn the relationship between text and sign language.
Technical Explanation
• SignCLIP builds on recent advancements in contrastive learning for text-image models and multimodal pretraining.
• The model consists of two encoders - one for text and one for sign language - that project their respective inputs into a shared embedding space.
• During training, the model is presented with pairs of text and sign language examples, and a contrastive loss is used to pull matching pairs closer together and push non-matching pairs farther apart in the embedding space.
• This allows the model to learn rich cross-modal representations that capture the semantic and structural relationships between text and sign language.
• Experiments on sign language translation and retrieval tasks demonstrate the effectiveness of SignCLIP, outperforming previous state-of-the-art methods.
Critical Analysis
• A potential limitation of SignCLIP is the reliance on large-scale datasets of text and sign language pairs, which can be difficult to acquire and curate.
• The paper does not explore how well SignCLIP would generalize to low-resource languages or dialects of sign language, which is an important consideration for real-world applications.
• Additionally, the paper does not address potential biases or ethical concerns that may arise from deploying such a system, such as issues of privacy or accessibility for the deaf and hard-of-hearing community.
• Further research is needed to better understand the strengths and weaknesses of the contrastive learning approach used by SignCLIP, and to explore alternative techniques for connecting text and sign language.
Conclusion
In summary, the SignCLIP paper presents a novel approach to bridging the gap between text and sign language using contrastive learning. By learning a shared representation between the two modalities, SignCLIP enables cross-modal applications like sign language translation and retrieval, which could have a significant impact on improving accessibility and communication for the deaf and hard-of-hearing community. While the paper demonstrates promising results, further research is needed to address the potential limitations and ethical considerations of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SignCLIP: Connecting Text and Sign Language by Contrastive Learning
Zifan Jiang, Gerard Sant, Amit Moryossef, Mathias Muller, Rico Sennrich, Sarah Ebling
We present SignCLIP, which re-purposes CLIP (Contrastive Language-Image Pretraining) to project spoken language text and sign language videos, two classes of natural languages of distinct modalities, into the same space. SignCLIP is an efficient method of learning useful visual representations for sign language processing from large-scale, multilingual video-text pairs, without directly optimizing for a specific task or sign language which is often of limited size. We pretrain SignCLIP on Spreadthesign, a prominent sign language dictionary consisting of ~500 thousand video clips in up to 44 sign languages, and evaluate it with various downstream datasets. SignCLIP discerns in-domain signing with notable text-to-video/video-to-text retrieval accuracy. It also performs competitively for out-of-domain downstream tasks such as isolated sign language recognition upon essential few-shot prompting or fine-tuning. We analyze the latent space formed by the spoken language text and sign language poses, which provides additional linguistic insights. Our code and models are openly available.
Read more7/2/2024
0
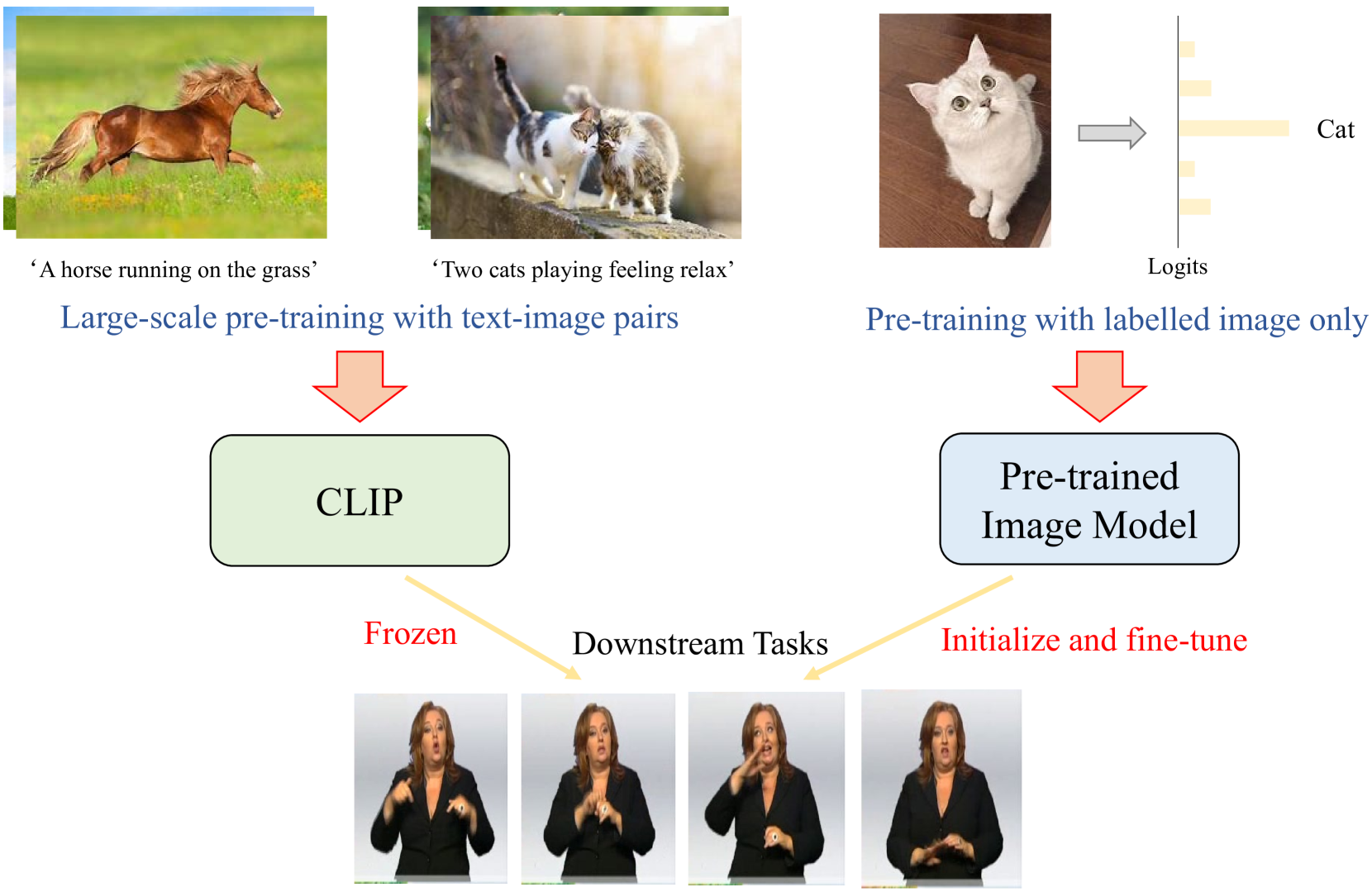
Improving Continuous Sign Language Recognition with Adapted Image Models
Lianyu Hu, Tongkai Shi, Liqing Gao, Zekang Liu, Wei Feng
The increase of web-scale weakly labelled image-text pairs have greatly facilitated the development of large-scale vision-language models (e.g., CLIP), which have shown impressive generalization performance over a series of downstream tasks. However, the massive model size and scarcity of available data limit their applications to fine-tune the whole model in downstream tasks. Besides, fully fine-tuning the model easily forgets the generic essential knowledge acquired in the pretraining stage and overfits the downstream data. To enable high efficiency when adapting these large vision-language models (e.g., CLIP) to performing continuous sign language recognition (CSLR) while preserving their generalizability, we propose a novel strategy (AdaptSign). Especially, CLIP is adopted as the visual backbone to extract frame-wise features whose parameters are fixed, and a set of learnable modules are introduced to model spatial sign variations or capture temporal sign movements. The introduced additional modules are quite lightweight, only owning 3.2% extra computations with high efficiency. The generic knowledge acquired in the pretraining stage is well-preserved in the frozen CLIP backbone in this process. Extensive experiments show that despite being efficient, AdaptSign is able to demonstrate superior performance across a series of CSLR benchmarks including PHOENIX14, PHOENIX14-T, CSL-Daily and CSL compared to existing methods. Visualizations show that AdaptSign could learn to dynamically pay major attention to the informative spatial regions and cross-frame trajectories in sign videos.
Read more4/15/2024

0
RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
Read more6/21/2024
0
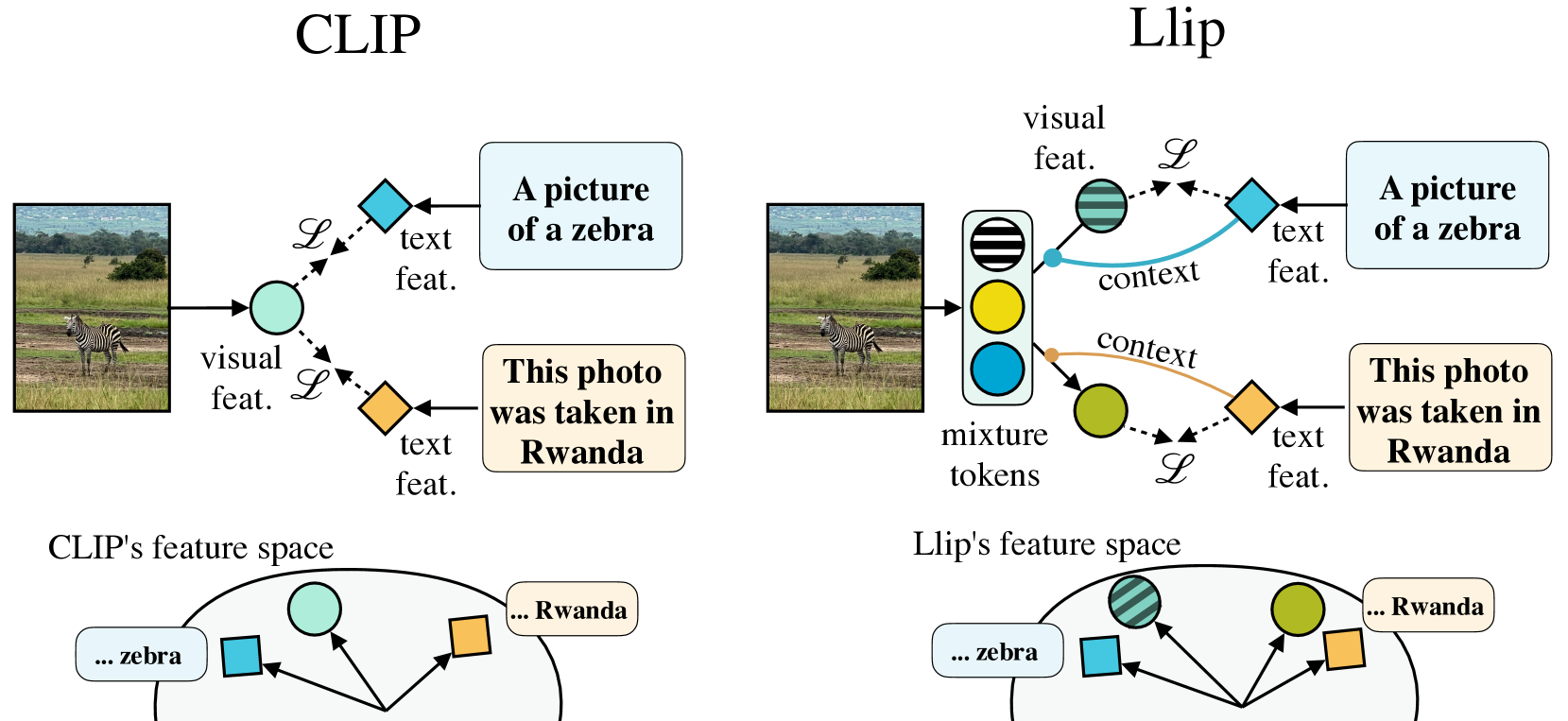
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
Read more5/15/2024