Similarity is Not All You Need: Endowing Retrieval Augmented Generation with Multi Layered Thoughts

0
Sign in to get full access
Overview
- This paper proposes a novel approach to retrieval-augmented generation (RAG) that aims to enhance the quality and coherence of generated text by incorporating multi-layered "thoughts" from the retrieval process.
- The authors argue that traditional RAG models, which rely solely on surface-level similarity between the input and retrieved passages, are limited in their ability to capture the deeper semantic and contextual relationships needed for high-quality text generation.
- The proposed Similarity is Not All You Need: Endowing Retrieval-Augmented Generation with Multi–layered Thoughts model addresses this by introducing a multi-layered retrieval process that considers various aspects of the input-passage relationship, such as semantic, logical, and pragmatic coherence.
Plain English Explanation
The paper describes a new way to improve the quality of text generated by AI models that use retrieval-augmented generation (RAG) techniques. RAG models work by first searching a database of information to find relevant passages, and then using those passages to help generate new text.
The authors argue that traditional RAG models focus too much on finding passages that are simply similar to the input text, without considering the deeper meaning and context behind the information. This can lead to generated text that, while factually accurate, may lack coherence and feel disconnected.
To address this, the proposed model introduces a more sophisticated retrieval process that looks at multiple "layers" of how the retrieved passages relate to the input. This includes not just surface-level similarity, but also the semantic meaning, logical flow, and pragmatic intent behind the information. By considering these richer relationships, the model can generate text that is more coherent, relevant, and contextually appropriate.
The key innovation is this multi-layered retrieval approach, which aims to give the generation model a more nuanced understanding of the information it's drawing upon, rather than just relying on simple keyword matching. This, in turn, should lead to more natural and meaningful text output.
Technical Explanation
The Similarity is Not All You Need: Endowing Retrieval-Augmented Generation with Multi–layered Thoughts paper proposes a new retrieval-augmented generation (RAG) model that goes beyond traditional approaches focused solely on surface-level similarity.
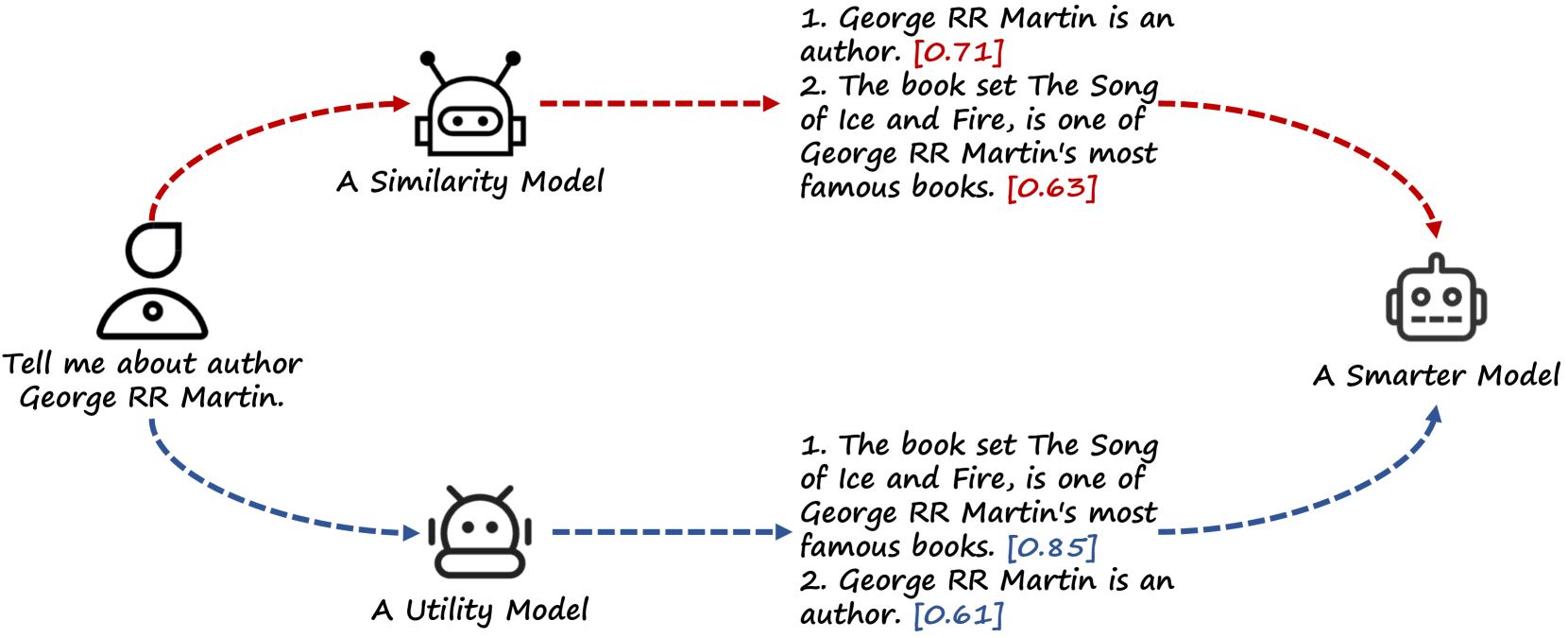
The model introduces a multi-layered retrieval process that considers semantic, logical, and pragmatic relationships between the input text and the passages retrieved from the database. This is achieved through the use of specialized encoders that capture different aspects of the input-passage relationship, such as:
- Semantic Encoder: Measures the semantic similarity between the input and passage content.
- Logical Encoder: Evaluates the logical coherence and flow of information between the input and passage.
- Pragmatic Encoder: Assesses the contextual appropriateness and intent behind the passage in relation to the input.
These multi-layered retrieval scores are then used to select the most relevant passages, which are in turn fed into the generation model to produce the final output text. The authors hypothesize that this richer understanding of the input-passage relationship will result in more coherent and contextually-appropriate generated text, compared to traditional RAG approaches.
The paper evaluates the proposed model on several text generation tasks, including question answering, abstractive summarization, and open-ended dialogue. The results demonstrate the benefits of the multi-layered retrieval approach, with the model outperforming strong baseline RAG systems on various metrics of text quality and coherence.
Critical Analysis
The Similarity is Not All You Need: Endowing Retrieval-Augmented Generation with Multi–layered Thoughts paper presents a compelling approach to enhancing retrieval-augmented generation by going beyond simple similarity-based retrieval.
One potential limitation is the complexity of the multi-layered retrieval process, which may come at the cost of increased computational overhead and model size. The paper does not provide a thorough analysis of the trade-offs between the improved text quality and the additional computational resources required.
Additionally, the evaluation is focused on a limited set of tasks, and it would be valuable to see how the model performs on a wider range of generation scenarios, including more open-ended and creative tasks. The paper also does not address potential biases or ethical considerations that may arise from the use of this technology.
Overall, the Similarity is Not All You Need: Endowing Retrieval-Augmented Generation with Multi–layered Thoughts model represents a promising step forward in improving the coherence and context-awareness of retrieval-augmented generation. However, further research is needed to fully understand the implications and limitations of this approach.
Conclusion
The Similarity is Not All You Need: Endowing Retrieval-Augmented Generation with Multi–layered Thoughts paper proposes a novel retrieval-augmented generation (RAG) model that goes beyond traditional similarity-based approaches. By introducing a multi-layered retrieval process that considers semantic, logical, and pragmatic relationships between the input and retrieved passages, the model aims to generate more coherent and contextually-appropriate text.
The results demonstrate the benefits of this approach, with the proposed model outperforming strong RAG baselines on various text generation tasks. This work represents an important step towards developing more advanced, context-aware language generation systems that can draw upon rich, multi-faceted knowledge to produce high-quality, relevant output.
As AI language models continue to advance, approaches like the one presented in this paper will be crucial for unlocking the full potential of retrieval-augmented generation, with applications ranging from question answering and summarization to open-ended dialogue and task-oriented assistance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Similarity is Not All You Need: Endowing Retrieval Augmented Generation with Multi Layered Thoughts
Chunjing Gan, Dan Yang, Binbin Hu, Hanxiao Zhang, Siyuan Li, Ziqi Liu, Yue Shen, Lin Ju, Zhiqiang Zhang, Jinjie Gu, Lei Liang, Jun Zhou
In recent years, large language models (LLMs) have made remarkable achievements in various domains. However, the untimeliness and cost of knowledge updates coupled with hallucination issues of LLMs have curtailed their applications in knowledge intensive tasks, where retrieval augmented generation (RAG) can be of help. Nevertheless, existing retrieval augmented models typically use similarity as a bridge between queries and documents and follow a retrieve then read procedure. In this work, we argue that similarity is not always the panacea and totally relying on similarity would sometimes degrade the performance of retrieval augmented generation. To this end, we propose MetRag, a Multi layEred Thoughts enhanced Retrieval Augmented Generation framework. To begin with, beyond existing similarity oriented thought, we embrace a small scale utility model that draws supervision from an LLM for utility oriented thought and further come up with a smarter model by comprehensively combining the similarity and utility oriented thoughts. Furthermore, given the fact that the retrieved document set tends to be huge and using them in isolation makes it difficult to capture the commonalities and characteristics among them, we propose to make an LLM as a task adaptive summarizer to endow retrieval augmented generation with compactness-oriented thought. Finally, with multi layered thoughts from the precedent stages, an LLM is called for knowledge augmented generation. Extensive experiments on knowledge-intensive tasks have demonstrated the superiority of MetRag.
Read more5/31/2024
💬
0
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
Read more6/18/2024

0
Unveil the Duality of Retrieval-Augmented Generation: Theoretical Analysis and Practical Solution
Shicheng Xu, Liang Pang, Huawei Shen, Xueqi Cheng
Retrieval-augmented generation (RAG) utilizes retrieved texts to enhance large language models (LLMs). However, studies show that RAG is not consistently effective and can even mislead LLMs due to noisy or incorrect retrieved texts. This suggests that RAG possesses a duality including both benefit and detriment. Although many existing methods attempt to address this issue, they lack a theoretical explanation for the duality in RAG. The benefit and detriment within this duality remain a black box that cannot be quantified or compared in an explainable manner. This paper takes the first step in theoretically giving the essential explanation of benefit and detriment in RAG by: (1) decoupling and formalizing them from RAG prediction, (2) approximating the gap between their values by representation similarity and (3) establishing the trade-off mechanism between them, to make them explainable, quantifiable, and comparable. We demonstrate that the distribution difference between retrieved texts and LLMs' knowledge acts as double-edged sword, bringing both benefit and detriment. We also prove that the actual effect of RAG can be predicted at token level. Based on our theory, we propose a practical novel method, X-RAG, which achieves collaborative generation between pure LLM and RAG at token level to preserve benefit and avoid detriment. Experiments in real-world tasks based on LLMs including OPT, LLaMA-2, and Mistral show the effectiveness of our method and support our theoretical results.
Read more6/4/2024

0
Retrieval-Augmented Generation for Natural Language Processing: A Survey
Shangyu Wu, Ying Xiong, Yufei Cui, Haolun Wu, Can Chen, Ye Yuan, Lianming Huang, Xue Liu, Tei-Wei Kuo, Nan Guan, Chun Jason Xue
Large language models (LLMs) have demonstrated great success in various fields, benefiting from their huge amount of parameters that store knowledge. However, LLMs still suffer from several key issues, such as hallucination problems, knowledge update issues, and lacking domain-specific expertise. The appearance of retrieval-augmented generation (RAG), which leverages an external knowledge database to augment LLMs, makes up those drawbacks of LLMs. This paper reviews all significant techniques of RAG, especially in the retriever and the retrieval fusions. Besides, tutorial codes are provided for implementing the representative techniques in RAG. This paper further discusses the RAG training, including RAG with/without datastore update. Then, we introduce the application of RAG in representative natural language processing tasks and industrial scenarios. Finally, this paper discusses the future directions and challenges of RAG for promoting its development.
Read more7/22/2024