Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
2406.00670
0
0
🛸
Abstract
Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
Create account to get full access
Overview
- This paper presents Cascade-CLIP, a novel approach for zero-shot semantic segmentation that leverages cascaded vision-language embeddings alignment.
- The key ideas include using multi-level visual features, cascaded decoders, and vision-language alignment to enable zero-shot transfer of semantic segmentation models to new classes.
- The proposed method demonstrates state-of-the-art performance on several zero-shot semantic segmentation benchmarks.
Plain English Explanation
Cascade-CLIP is a new technique for a computer vision task called zero-shot semantic segmentation. This means it can identify and locate different objects in an image without having been trained on those specific objects before.
The core innovation is a cascaded architecture that aligns visual features from the image with corresponding language descriptions. This allows the model to learn how visual patterns correspond to semantic concepts, even for objects it hasn't seen during training.
By using multi-level visual features and cascaded decoders, Cascade-CLIP can effectively transfer its understanding of object semantics to new classes it hasn't encountered before. This enables zero-shot transfer, where the model can perform segmentation on novel classes without any additional training.
The researchers demonstrate that Cascade-CLIP achieves state-of-the-art results on several benchmark datasets for zero-shot semantic segmentation, outperforming previous methods. This suggests the technique could be broadly applicable for efficiently scaling semantic understanding to new domains.
Technical Explanation
The key technical elements of Cascade-CLIP include:
-
Multi-level Visual Features: The model extracts visual features at multiple levels of the convolutional neural network, capturing both low-level details and high-level semantic information.
-
Cascaded Decoders: Rather than a single segmentation decoder, Cascade-CLIP uses a cascaded architecture with multiple decoders. Each decoder refines the segmentation output by leveraging the multi-level visual features.
-
Vision-Language Alignment: The model is pre-trained on vision-language data (e.g. CLIP) to align the visual features with corresponding textual descriptions. This allows zero-shot transfer to new classes.
During inference, Cascade-CLIP takes an input image and generates a semantic segmentation map, even for object classes not seen during training. This is achieved by transferring the model's understanding of visual-semantic alignment to the new classes.
The researchers evaluate Cascade-CLIP on several zero-shot semantic segmentation benchmarks, including PASCAL-VOC, COCO, and ADE20K. The results demonstrate state-of-the-art performance, outperforming previous methods that rely on additional training data or complex architectures.
Critical Analysis
The authors acknowledge several limitations of the Cascade-CLIP approach. First, the vision-language pre-training requires large-scale datasets, which may not be available for all domains. Additionally, the cascaded architecture increases model complexity and computational cost compared to simpler segmentation models.
Another potential issue is the reliance on the quality of the underlying vision-language embeddings (e.g. CLIP). If the pre-trained embeddings have biases or limitations, these could be propagated through the Cascade-CLIP model.
Further research could explore ways to reduce the model complexity or improve the robustness of the vision-language alignment. Additionally, investigating the model's performance on more diverse or challenging datasets could provide additional insights.
Conclusion
Cascade-CLIP presents a novel approach for zero-shot semantic segmentation that leverages cascaded vision-language embeddings alignment. By using multi-level visual features, cascaded decoders, and pre-trained vision-language understanding, the model can effectively transfer its semantic knowledge to new object classes without any additional training.
The strong results on several benchmark datasets suggest Cascade-CLIP could be a valuable tool for efficiently scaling semantic segmentation to new domains. However, the reliance on large-scale vision-language data and increased model complexity are areas that warrant further investigation.
Overall, this research demonstrates the potential of vision-language models and cascaded architectures for advancing the state-of-the-art in zero-shot transfer learning for computer vision tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Enhancing Fine-Grained Image Classifications via Cascaded Vision Language Models
Canshi Wei
0
0
Fine-grained image classification, particularly in zero/few-shot scenarios, presents a significant challenge for vision-language models (VLMs), such as CLIP. These models often struggle with the nuanced task of distinguishing between semantically similar classes due to limitations in their pre-trained recipe, which lacks supervision signals for fine-grained categorization. This paper introduces CascadeVLM, an innovative framework that overcomes the constraints of previous CLIP-based methods by effectively leveraging the granular knowledge encapsulated within large vision-language models (LVLMs). Experiments across various fine-grained image datasets demonstrate that CascadeVLM significantly outperforms existing models, specifically on the Stanford Cars dataset, achieving an impressive 85.6% zero-shot accuracy. Performance gain analysis validates that LVLMs produce more accurate predictions for challenging images that CLIPs are uncertain about, bringing the overall accuracy boost. Our framework sheds light on a holistic integration of VLMs and LVLMs for effective and efficient fine-grained image classification.
5/21/2024
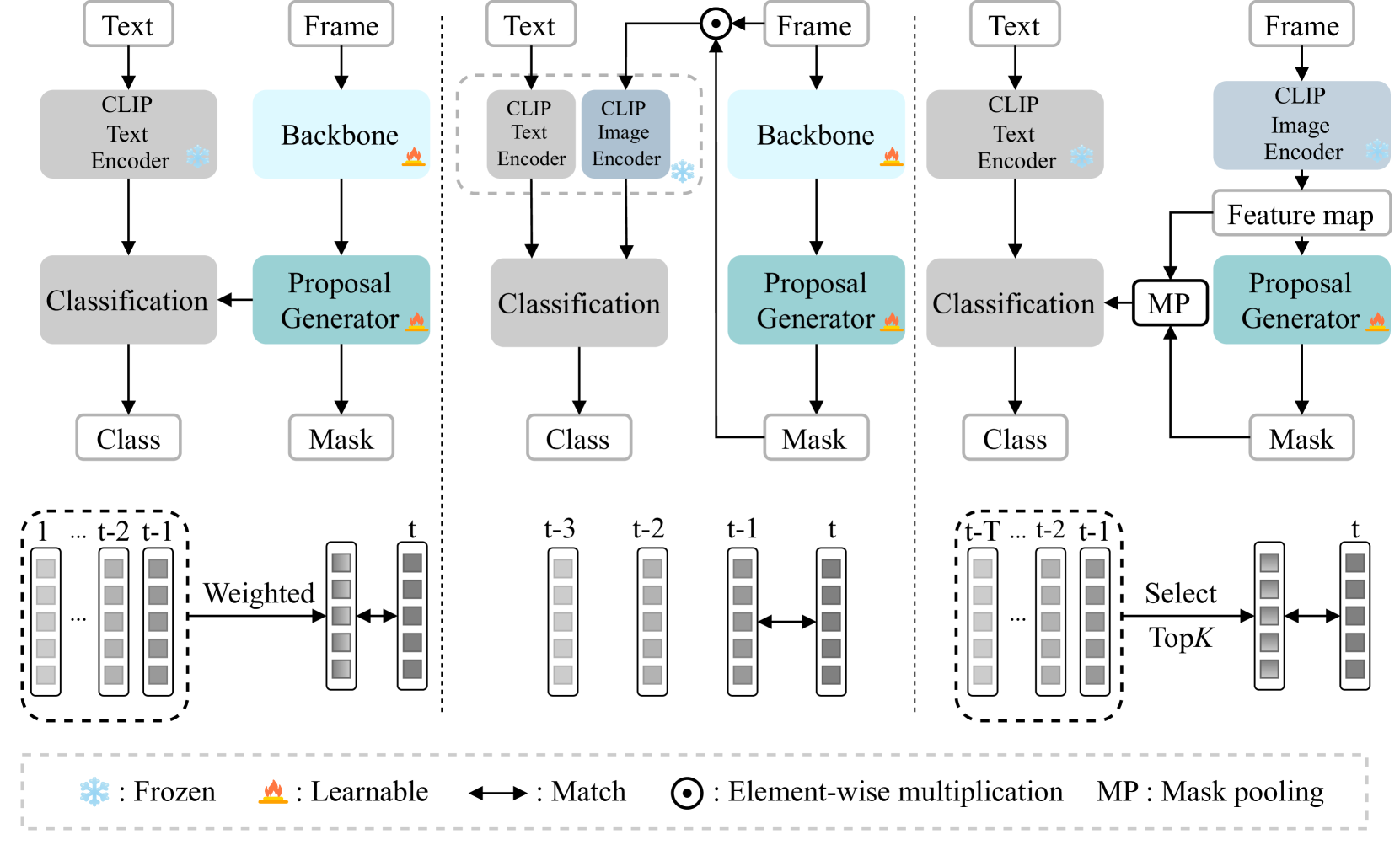
CLIP-VIS: Adapting CLIP for Open-Vocabulary Video Instance Segmentation
Wenqi Zhu, Jiale Cao, Jin Xie, Shuangming Yang, Yanwei Pang
0
0
Open-vocabulary video instance segmentation strives to segment and track instances belonging to an open set of categories in a video. The vision-language model Contrastive Language-Image Pre-training (CLIP) has shown robust zero-shot classification ability in image-level open-vocabulary task. In this paper, we propose a simple encoder-decoder network, called CLIP-VIS, to adapt CLIP for open-vocabulary video instance segmentation. Our CLIP-VIS adopts frozen CLIP image encoder and introduces three modules, including class-agnostic mask generation, temporal topK-enhanced matching, and weighted open-vocabulary classification. Given a set of initial queries, class-agnostic mask generation employs a transformer decoder to predict query masks and corresponding object scores and mask IoU scores. Then, temporal topK-enhanced matching performs query matching across frames by using K mostly matched frames. Finally, weighted open-vocabulary classification first generates query visual features with mask pooling, and second performs weighted classification using object scores and mask IoU scores.Our CLIP-VIS does not require the annotations of instance categories and identities. The experiments are performed on various video instance segmentation datasets, which demonstrate the effectiveness of our proposed method, especially on novel categories. When using ConvNeXt-B as backbone, our CLIP-VIS achieves the AP and APn scores of 32.2% and 40.2% on validation set of LV-VIS dataset, which outperforms OV2Seg by 11.1% and 23.9% respectively. We will release the source code and models at https://github.com/zwq456/CLIP-VIS.git.
6/11/2024
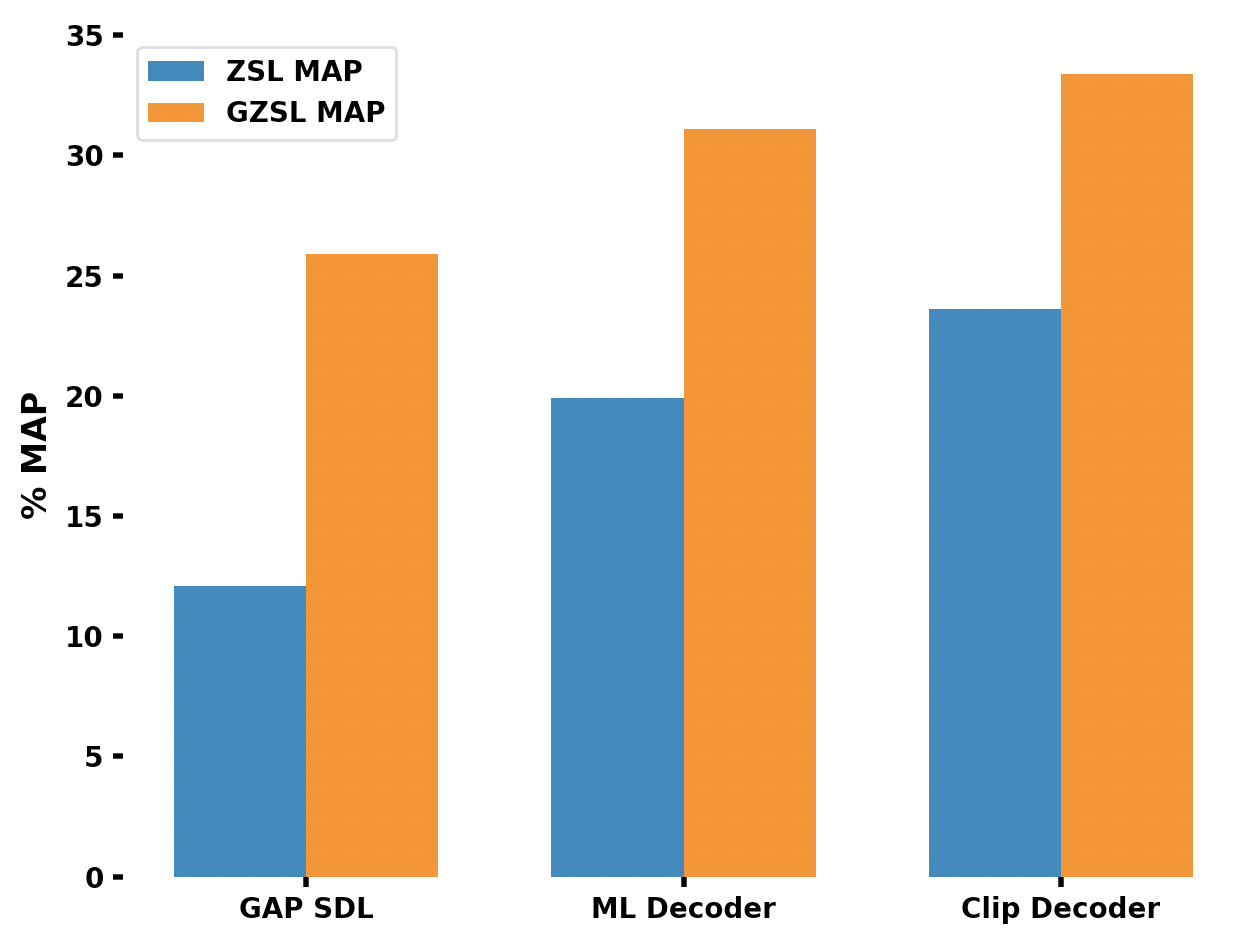
CLIP-Decoder : ZeroShot Multilabel Classification using Multimodal CLIP Aligned Representation
Muhammad Ali, Salman Khan
0
0
Multi-label classification is an essential task utilized in a wide variety of real-world applications. Multi-label zero-shot learning is a method for classifying images into multiple unseen categories for which no training data is available, while in general zero-shot situations, the test set may include observed classes. The CLIP-Decoder is a novel method based on the state-of-the-art ML-Decoder attention-based head. We introduce multi-modal representation learning in CLIP-Decoder, utilizing the text encoder to extract text features and the image encoder for image feature extraction. Furthermore, we minimize semantic mismatch by aligning image and word embeddings in the same dimension and comparing their respective representations using a combined loss, which comprises classification loss and CLIP loss. This strategy outperforms other methods and we achieve cutting-edge results on zero-shot multilabel classification tasks using CLIP-Decoder. Our method achieves an absolute increase of 3.9% in performance compared to existing methods for zero-shot learning multi-label classification tasks. Additionally, in the generalized zero-shot learning multi-label classification task, our method shows an impressive increase of almost 2.3%.
6/24/2024
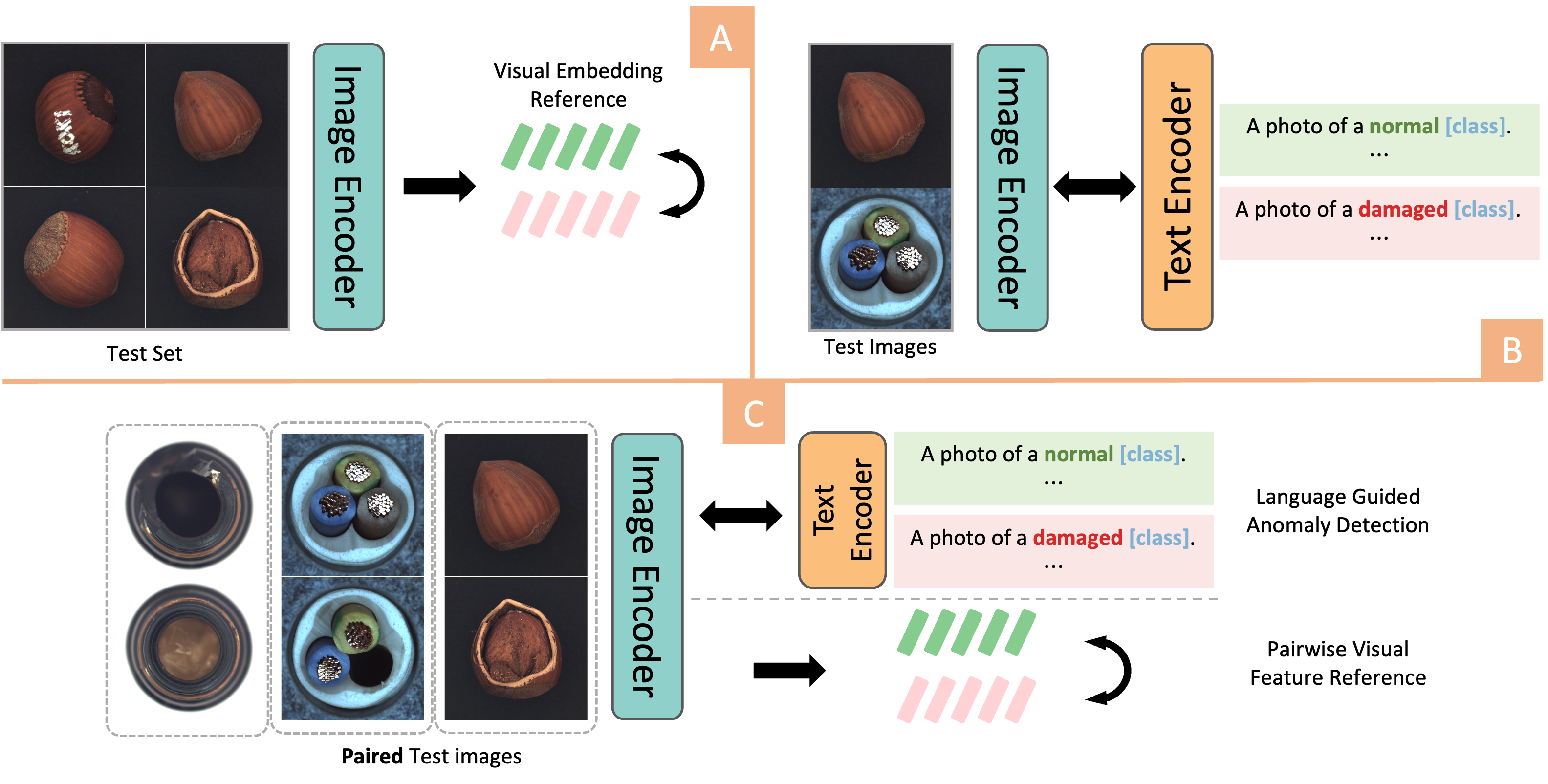
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
Zhaoxiang Zhang, Hanqiu Deng, Jinan Bao, Xingyu Li
0
0
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
5/9/2024