A simple theory for training response of deep neural networks
2405.04074
0
0
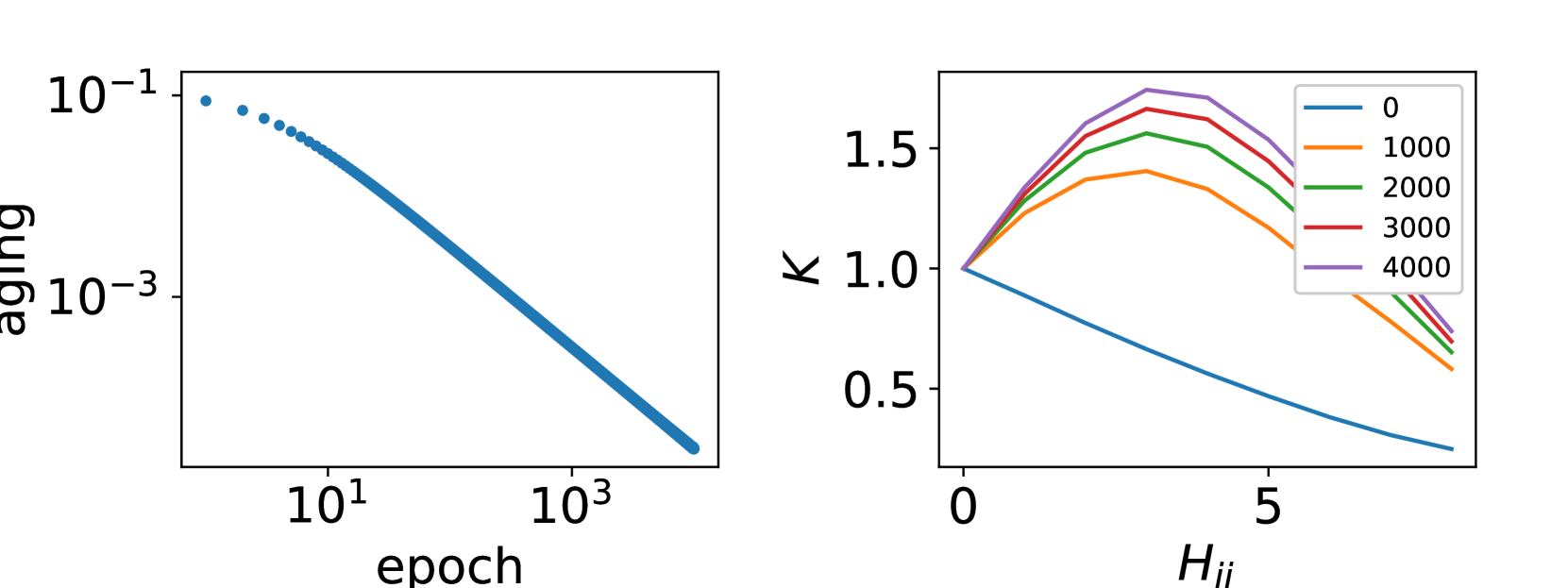
Abstract
Deep neural networks give us a powerful method to model the training dataset's relationship between input and output. We can regard that as a complex adaptive system consisting of many artificial neurons that work as an adaptive memory as a whole. The network's behavior is training dynamics with a feedback loop from the evaluation of the loss function. We already know the training response can be constant or shows power law-like aging in some ideal situations. However, we still have gaps between those findings and other complex phenomena, like network fragility. To fill the gap, we introduce a very simple network and analyze it. We show the training response consists of some different factors based on training stages, activation functions, or training methods. In addition, we show feature space reduction as an effect of stochastic training dynamics, which can result in network fragility. Finally, we discuss some complex phenomena of deep networks.
Create account to get full access
Overview
- This paper presents a simple theoretical model to explain the training response of deep neural networks.
- The model focuses on the concepts of response decay and response specificity in deep learning.
- The authors aim to provide a better understanding of how deep neural networks learn and generalize.
Plain English Explanation
Deep neural networks have become incredibly powerful tools for a wide range of tasks, from image recognition to language processing. However, the internal workings of these complex models are not always well understood. This paper proposes a simple theoretical model to help explain how deep neural networks learn and make predictions.
The key ideas are response decay and response specificity. Response decay refers to the fact that as you go deeper into a neural network, the response to a given input tends to become more muted or "decayed." Response specificity means that deeper layers of the network become tuned to very specific, localized patterns in the data.
Imagine a deep neural network as a series of filters, each one becoming more and more specialized. The first filter might detect simple edges or shapes, the middle filters might find more complex patterns, and the final filters are extremely specific, responding only to very particular configurations of features. This specialization allows the network to build up a rich, hierarchical representation of the input data.
The authors use this idea of response decay and specificity to explain several key phenomena in deep learning, such as the ability of neural networks to generalize to new data and their impressive performance on tasks like image classification. By providing a simple, intuitive model, the researchers hope to shed light on the inner workings of these powerful AI systems.
Technical Explanation
The paper presents a simple theoretical model to explain the training response of deep neural networks. The key concepts are response decay and response specificity.
The model assumes that each layer of a deep neural network acts as a linear filter, where the filter response decays exponentially with depth. This response decay is a consequence of the stretched and measured neural predictions in complex network dynamics. As the signal propagates through the network, it becomes increasingly attenuated, leading to the well-known "vanishing gradient" problem.
However, the model also incorporates the idea of response specificity. As the network trains, the filters become increasingly tuned to specific patterns in the input data, leading to a more sparse and localized response in the deeper layers. This specialization allows the network to build up a rich, hierarchical representation of the input, enabling impressive generalization performance.
The authors show that this simple model can explain several empirical observations, such as the scaling laws governing the dynamical model of neural network scaling, the exactly solvable model for the emergence of scaling laws, and the ability of deep neural networks to generalize to new data.
Critical Analysis
The paper presents a compelling and intuitive theoretical framework for understanding the training response of deep neural networks. The concepts of response decay and response specificity provide a coherent explanation for several empirical observations in deep learning, and the authors do a good job of connecting their model to prior work in the field.
One potential limitation of the model is that it assumes a very simple, linear filter structure for each layer of the network. In reality, deep neural networks are much more complex, with nonlinear activation functions, skip connections, and other architectural features that may not be fully captured by the model.
Additionally, the model does not address the role of optimization algorithms, regularization techniques, and other training practices that can significantly impact the behavior of deep neural networks. These factors may introduce additional complexities that are not accounted for in the current framework.
It would be interesting to see the authors extend the model to incorporate these additional elements and explore how they might interact with the core concepts of response decay and response specificity. Rigorous empirical validation of the model's predictions on a wider range of deep learning tasks and architectures would also help to strengthen the case for its utility.
Overall, this paper provides a valuable contribution to the ongoing effort to understand the inner workings of deep neural networks. By offering a simple, intuitive theory that can explain key phenomena, the authors have taken an important step towards a more comprehensive understanding of these powerful AI systems.
Conclusion
This paper presents a simple theoretical model to explain the training response of deep neural networks. The key ideas are response decay and response specificity, which together can account for several empirical observations in deep learning, such as the ability of neural networks to generalize to new data and the scaling laws that govern their performance.
By offering a coherent and intuitive framework for understanding how deep neural networks learn and operate, this paper represents an important step towards a more comprehensive theory of deep learning. While the model has some limitations, it provides a valuable starting point for further exploration and refinement, potentially leading to new insights and advancements in the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
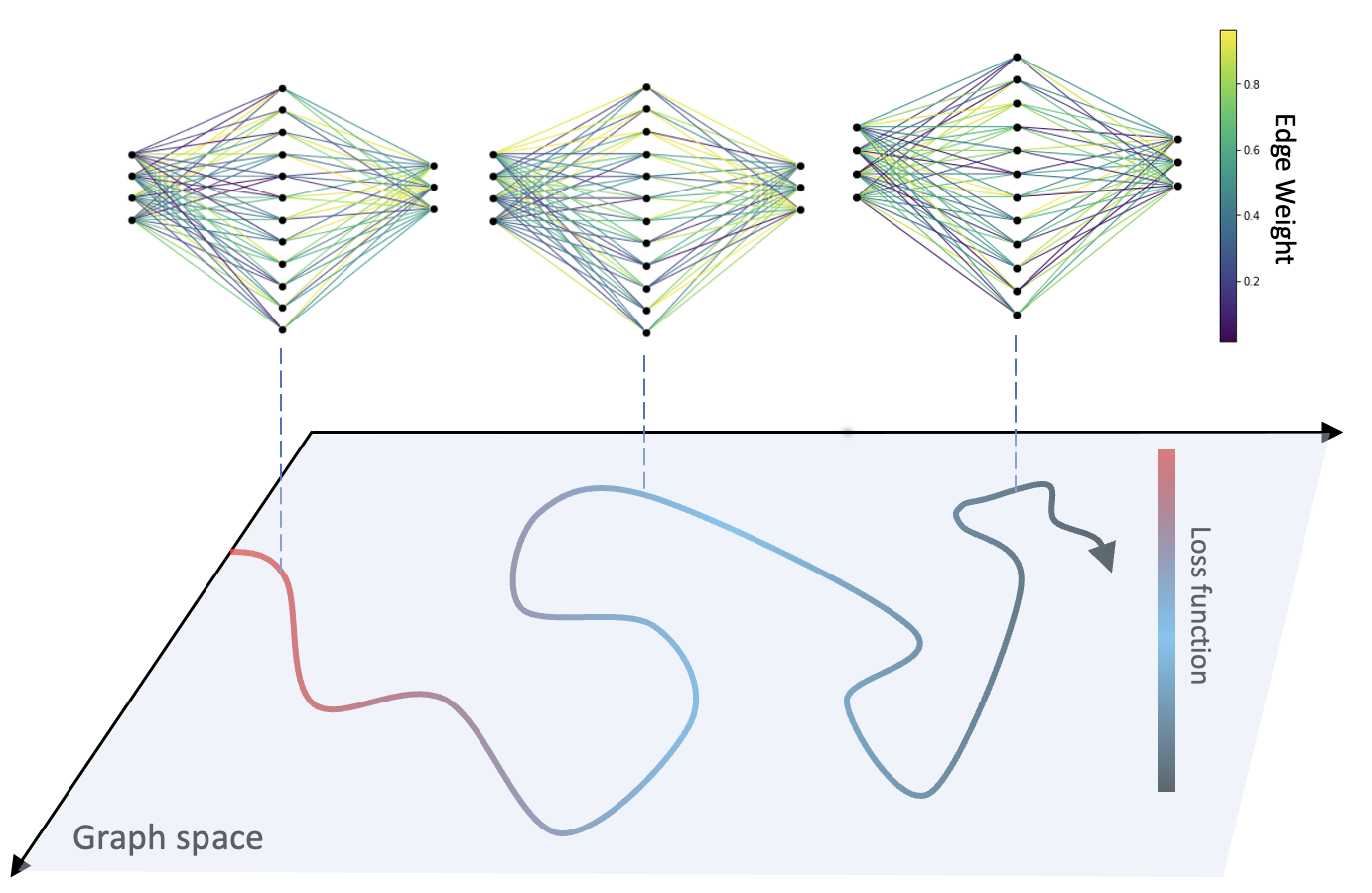
Dynamical stability and chaos in artificial neural network trajectories along training
Kaloyan Danovski, Miguel C. Soriano, Lucas Lacasa
0
0
The process of training an artificial neural network involves iteratively adapting its parameters so as to minimize the error of the network's prediction, when confronted with a learning task. This iterative change can be naturally interpreted as a trajectory in network space -- a time series of networks -- and thus the training algorithm (e.g. gradient descent optimization of a suitable loss function) can be interpreted as a dynamical system in graph space. In order to illustrate this interpretation, here we study the dynamical properties of this process by analyzing through this lens the network trajectories of a shallow neural network, and its evolution through learning a simple classification task. We systematically consider different ranges of the learning rate and explore both the dynamical and orbital stability of the resulting network trajectories, finding hints of regular and chaotic behavior depending on the learning rate regime. Our findings are put in contrast to common wisdom on convergence properties of neural networks and dynamical systems theory. This work also contributes to the cross-fertilization of ideas between dynamical systems theory, network theory and machine learning
4/10/2024
On the weight dynamics of learning networks
Nahal Sharafi, Christoph Martin, Sarah Hallerberg
0
0
Neural networks have become a widely adopted tool for tackling a variety of problems in machine learning and artificial intelligence. In this contribution we use the mathematical framework of local stability analysis to gain a deeper understanding of the learning dynamics of feed forward neural networks. Therefore, we derive equations for the tangent operator of the learning dynamics of three-layer networks learning regression tasks. The results are valid for an arbitrary numbers of nodes and arbitrary choices of activation functions. Applying the results to a network learning a regression task, we investigate numerically, how stability indicators relate to the final training-loss. Although the specific results vary with different choices of initial conditions and activation functions, we demonstrate that it is possible to predict the final training loss, by monitoring finite-time Lyapunov exponents or covariant Lyapunov vectors during the training process.
5/3/2024
🧠
Stretched and measured neural predictions of complex network dynamics
Vaiva Vasiliauskaite, Nino Antulov-Fantulin
0
0
Differential equations are a ubiquitous tool to study dynamics, ranging from physical systems to complex systems, where a large number of agents interact through a graph with non-trivial topological features. Data-driven approximations of differential equations present a promising alternative to traditional methods for uncovering a model of dynamical systems, especially in complex systems that lack explicit first principles. A recently employed machine learning tool for studying dynamics is neural networks, which can be used for data-driven solution finding or discovery of differential equations. Specifically for the latter task, however, deploying deep learning models in unfamiliar settings - such as predicting dynamics in unobserved state space regions or on novel graphs - can lead to spurious results. Focusing on complex systems whose dynamics are described with a system of first-order differential equations coupled through a graph, we show that extending the model's generalizability beyond traditional statistical learning theory limits is feasible. However, achieving this advanced level of generalization requires neural network models to conform to fundamental assumptions about the dynamical model. Additionally, we propose a statistical significance test to assess prediction quality during inference, enabling the identification of a neural network's confidence level in its predictions.
4/26/2024
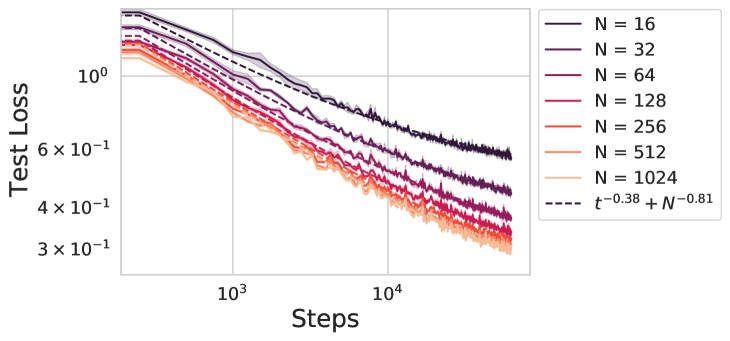
A Dynamical Model of Neural Scaling Laws
Blake Bordelon, Alexander Atanasov, Cengiz Pehlevan
0
0
On a variety of tasks, the performance of neural networks predictably improves with training time, dataset size and model size across many orders of magnitude. This phenomenon is known as a neural scaling law. Of fundamental importance is the compute-optimal scaling law, which reports the performance as a function of units of compute when choosing model sizes optimally. We analyze a random feature model trained with gradient descent as a solvable model of network training and generalization. This reproduces many observations about neural scaling laws. First, our model makes a prediction about why the scaling of performance with training time and with model size have different power law exponents. Consequently, the theory predicts an asymmetric compute-optimal scaling rule where the number of training steps are increased faster than model parameters, consistent with recent empirical observations. Second, it has been observed that early in training, networks converge to their infinite-width dynamics at a rate $1/textit{width}$ but at late time exhibit a rate $textit{width}^{-c}$, where $c$ depends on the structure of the architecture and task. We show that our model exhibits this behavior. Lastly, our theory shows how the gap between training and test loss can gradually build up over time due to repeated reuse of data.
6/26/2024