A simulation study of cluster search algorithms in data set generated by Gaussian mixture models

0

Sign in to get full access
Overview
- This paper presents a simulation study that examines the performance of various cluster search algorithms on data sets generated by Gaussian mixture models.
- The study compares the accuracy and efficiency of different clustering algorithms in identifying the underlying Gaussian components.
- Key algorithms evaluated include K-means, Gaussian Mixture Models (GMM), and Spectral Clustering.
Plain English Explanation
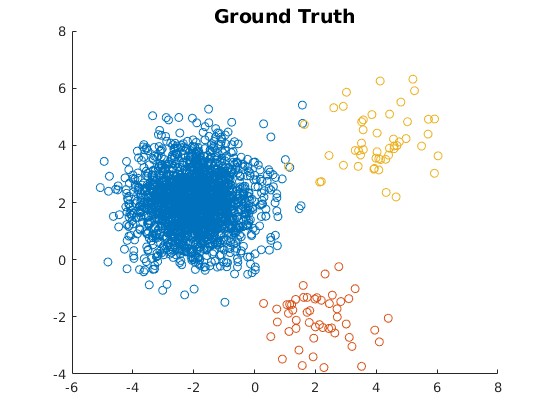
In this study, the researchers created synthetic data sets that mimic real-world data with multiple clusters or "groups" of data points. They did this by using a mathematical model called a Gaussian Mixture Model, which can generate data that looks like it comes from a combination of several normal distributions.
The researchers then tested various clustering algorithms - methods for automatically identifying the different groups in the data - to see how well they could recover the original clusters. They looked at factors like how accurate the algorithms were at correctly grouping the data points, and how efficiently the algorithms could process the data.
The main clustering methods evaluated were:
- K-means clustering: an algorithm that partitions the data into a pre-specified number of clusters
- Gaussian Mixture Models: a statistical model that represents the data as a mixture of several normal distributions
- Spectral Clustering: an approach that uses the eigenvalues of a similarity matrix to identify clusters
By testing these algorithms on the Gaussian mixture data, the researchers were able to understand their strengths and weaknesses in practical clustering applications.
Technical Explanation
The paper first describes the Gaussian mixture model used to generate the synthetic data sets. This involves specifying the number of Gaussian components, their means, variances, and mixture proportions. The researchers then apply several common clustering algorithms to these data sets and evaluate their performance.
The K-means algorithm partitions the data into K clusters by iteratively updating cluster centroids to minimize the sum of squared distances between data points and their assigned centroids. The Gaussian Mixture Model (GMM) approach models the data as a weighted sum of Gaussian distributions and uses an EM algorithm to estimate the model parameters. Spectral Clustering constructs a similarity matrix from the data and then performs eigendecomposition to identify the cluster structure.
The performance of these algorithms is evaluated in terms of clustering accuracy, as measured by the Adjusted Rand Index, as well as computational efficiency. The results show that the GMM approach generally outperforms K-means and Spectral Clustering when the true cluster structure matches the Gaussian mixture assumption. However, the algorithms have different strengths - for example, Spectral Clustering can better handle non-convex cluster shapes.
Critical Analysis
The study provides a useful simulation-based comparison of common clustering algorithms on Gaussian mixture data. However, it is important to note that real-world data often deviates from the idealized Gaussian mixture assumption. The performance of these algorithms may differ when applied to more complex, non-Gaussian clusters or high-dimensional data.
Additionally, the paper does not explore the sensitivity of the algorithms to factors like cluster overlap, imbalanced cluster sizes, or the presence of noise/outliers in the data. Further research would be needed to understand the robustness of these methods in more realistic scenarios.
It would also be valuable to see how these algorithms scale to very large data sets, as distributed approaches may be necessary for practical applications. The paper's focus on accuracy and efficiency is appropriate, but other considerations like interpretability and ease of parameter tuning could also be important in real-world use cases.
Conclusion
This simulation study provides a useful comparison of common clustering algorithms on data generated by Gaussian mixture models. The results suggest that Gaussian Mixture Models generally outperform K-means and Spectral Clustering when the data truly follows a Gaussian mixture structure. However, the algorithms have different strengths, and their performance may vary depending on the characteristics of the data. Further research is needed to understand the robustness and scalability of these methods in more realistic and complex clustering scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A simulation study of cluster search algorithms in data set generated by Gaussian mixture models
Ryosuke Motegi, Yoichi Seki
Determining the number of clusters is a fundamental issue in data clustering. Several algorithms have been proposed, including centroid-based algorithms using the Euclidean distance and model-based algorithms using a mixture of probability distributions. Among these, greedy algorithms for searching the number of clusters by repeatedly splitting or merging clusters have advantages in terms of computation time for problems with large sample sizes. However, studies comparing these methods in systematic evaluation experiments still need to be included. This study examines centroid- and model-based cluster search algorithms in various cases that Gaussian mixture models (GMMs) can generate. The cases are generated by combining five factors: dimensionality, sample size, the number of clusters, cluster overlap, and covariance type. The results show that some cluster-splitting criteria based on Euclidean distance make unreasonable decisions when clusters overlap. The results also show that model-based algorithms are insensitive to covariance type and cluster overlap compared to the centroid-based method if the sample size is sufficient. Our cluster search implementation codes are available at https://github.com/lipryou/searchClustK
Read more7/30/2024
📈
0
A new model for natural groupings in high-dimensional data
Mireille Boutin, Evzenie Coupkova
Clustering aims to divide a set of points into groups. The current paradigm assumes that the grouping is well-defined (unique) given the probability model from which the data is drawn. Yet, recent experiments have uncovered several high-dimensional datasets that form different binary groupings after projecting the data to randomly chosen one-dimensional subspaces. This paper describes a probability model for the data that could explain this phenomenon. It is a simple model to serve as a proof of concept for understanding the geometry of high-dimensional data. We start by building a rescaled multivariate Bernouilli model (stretched hypercube) so to create several overlapping grouping structures in the data. The size of each scaling parameter is related to the likelihood of uncovering the corresponding grouping by random 1D projection. Clusters in the original space are then created by adding noise to this cluster-free model. In high dimension, these clusters would hardly be observable given a sample set from the distribution because of the curse of dimensionality, but the binary groupings are clear. Our construction makes it clear that one needs to make a distinction between groupings and clusters in the original space. It also highlights the need to interpret any clustering found in projected data as merely one among potentially many other groupings in a dataset.
Read more6/26/2024
0
Imbalanced Data Clustering using Equilibrium K-Means
Yudong He
Centroid-based clustering algorithms, such as hard K-means (HKM) and fuzzy K-means (FKM), have suffered from learning bias towards large clusters. Their centroids tend to be crowded in large clusters, compromising performance when the true underlying data groups vary in size (i.e., imbalanced data). To address this, we propose a new clustering objective function based on the Boltzmann operator, which introduces a novel centroid repulsion mechanism, where data points surrounding the centroids repel other centroids. Larger clusters repel more, effectively mitigating the issue of large cluster learning bias. The proposed new algorithm, called equilibrium K-means (EKM), is simple, alternating between two steps; resource-saving, with the same time and space complexity as FKM; and scalable to large datasets via batch learning. We substantially evaluate the performance of EKM on synthetic and real-world datasets. The results show that EKM performs competitively on balanced data and significantly outperforms benchmark algorithms on imbalanced data. Deep clustering experiments demonstrate that EKM is a better alternative to HKM and FKM on imbalanced data as more discriminative representation can be obtained. Additionally, we reformulate HKM, FKM, and EKM in a general form of gradient descent and demonstrate how this general form facilitates a uniform study of K-means algorithms.
Read more6/7/2024
🚀
0
Using k-medoids for distributed approximate similarity search with arbitrary distances
Elena Garcia-Morato, Maria Jesus Algar, Cesar Alfaro, Felipe Ortega, Javier Gomez, Javier M. Moguerza
Similarity search is a central problem in domains such as information management and retrieval or data analysis. Many similarity search algorithms are designed or specifically adapted to metric distances. Thus, they are unsuitable for alternatives like the cosine distance, which has become quite common, for example, with embeddings and in text mining. This paper presents GDASC (General Distributed Approximate Similarity search with Clustering), a general framework for distributed approximate similarity search that accepts arbitrary distances. This framework can build a multilevel index structure, by selecting a clustering algorithm, the number of prototypes in each cluster and any arbitrary distance function. As a result, this framework effectively overcomes the limitation of using metric distances and can address situations involving cosine similarity or other non-standard similarity measures. Experimental results using k-medoids clustering in GDASC with real datasets confirm the applicability of this approach for approximate similarity search, improving the performance of extant algorithms for this purpose.
Read more8/9/2024